Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Cancel
- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Assigning Address Ranges from nearby Address P...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Assigning Address Ranges from nearby Address Points
Subscribe
08-05-2013
05:31 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello,
I am a GIS Tech at a city gov. with our own 911 dispatch. I am working to update our street centerline ranges for use in our dispatch software. The geography is accurate; however, the address ranges are model types and do not fit reality, i.e. range 1-100, when there are only 4 houses on the block from 101 - 116. I would like to use dynamic segmentation to help fix these ranges.
I came across this white paper by Kelly Bigley (2003) http://proceedings.esri.com/library/userconf/proc03/p1077.pdf
Which has a process I would like to replicate:
I'm new to python and eager to learn so I am asking to be pointed in the right direction to write a similar script - comparing address point street names to centerline street names before performing the NEAR analysis. Thank you.
Once the NEAR is complete for Address --> Roads, I want to dynamically segment the roads based on those address points, with each segment having an address range determined by the address points along it.
Langdon
I am a GIS Tech at a city gov. with our own 911 dispatch. I am working to update our street centerline ranges for use in our dispatch software. The geography is accurate; however, the address ranges are model types and do not fit reality, i.e. range 1-100, when there are only 4 houses on the block from 101 - 116. I would like to use dynamic segmentation to help fix these ranges.
I came across this white paper by Kelly Bigley (2003) http://proceedings.esri.com/library/userconf/proc03/p1077.pdf
Which has a process I would like to replicate:
Of course it is possible that an address point may be closer to a road that it is not addressed off of. An ArcINFO- Kelly Bigley
AML script can be used to loop through each street name. For each name it creates a subset of the streets and
address points with that street name. It performs a NEAR command on those subset coverages and transfers the
unique street coverage COVER-ID to the address points. Then it appends the resulting point coverages into one.
The resulting coverage is basically the original address coverage with a few additional attributes, including the
COVER-ID of the street centerline and the X and Y coordinate along the closest arc.
I'm new to python and eager to learn so I am asking to be pointed in the right direction to write a similar script - comparing address point street names to centerline street names before performing the NEAR analysis. Thank you.
Once the NEAR is complete for Address --> Roads, I want to dynamically segment the roads based on those address points, with each segment having an address range determined by the address points along it.
Langdon
Solved! Go to Solution.
1 Solution
Accepted Solutions
08-15-2013
03:44 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I think I have figured out a way to get the houses on each side of the ends of the lines. Working with 4 sets:
Even House Numbers on the Left Side of the Street
Even House Numbers on the Right Side of the Street
Odd House Numbers on the Left Side of the Street
Odd House Numbers on the Right Side of the Street
Here are the steps.
I created 2 fields with one named EVEN_ODD and the other named LEFT_RIGHT to simplify the selection and allow sorting that ignores the actual numeric values of the House Number and the Distance field. I calculated them to be:
Parser: VB Script
Show Codeblock: Checked
Prelogic Script Code:
EVEN_ODD = Output
For the LEFT_RIGHT field I changed the Prelogic Script Code to:
Next I selected the set of Even Houses on the Left Side of the street and exported it to a new table named Address_Even_Left using the SQL:
"EVEN_ODD" = 'EVEN_HOUSE' AND "LEFT_RIGHT" = 'LEFT_SIDE'
Then in ArcCatalog I Load data into the Address_Even_Left table to duplicate the records from the original Locate Features Along Route output using the SQL above to limit the records to match the criteria for that table.
Then I run the Sort Tool on the Address_Even_Left with the sort set for:
RID Ascending
Measure Ascending
House_Number Ascending.
In the Sorted output I added a field called LINE_NUMBER. For tables where the first ObjectID is numbered one (1) I calculated it to be (reverse the logic if the first ObjectID is 0 for dbf tables):
Parser: VB Script
Show Codeblock: Checked
Prelogic Script Code:
LINE_NUMBER = Output
Next I run the Summary Statistics to covert the points to line events. The Summary Statistic settings are:
Input Table: Address_Even_Left_Sort
Output Table: Address_Even_Left_Lines
Statistics Fields:
ObjectID Min
ObjectID Max
Meas Min
Meas Max
Case Fields:
RID
LINE_NUMBER
In the output from that tool I added a field called FROM_HOUSE_NUMBER and TO_HOUSE_NUMBER. I joined the MIN_OBJECTID field to the ObjectID field of the Address_Even_Left_Sort and calculate the FROM_HOUSE_NUMBER field to equal the House_Number of the sorted table. I then broke that join and rejoined the MAX_OBJECTID field to the ObjectID field of the Address_Even_Left_Sort and calculate the TO_HOUSE_NUMBER field to equal the House_Number of the sorted table. The line event table has zero length lines at each end of the set pf house numbers or where only one house number occurred on the entire route.
Now I have a Line event table of where the Even house numbers on the Left of the line are listed for the correct ends of the lines as the measures increase on the route. House numbers can end up ascending or descending. Now I can use the Overlay Route Events tool with my road segment end point events to find the match of the lines and house numbers to the segment ends. I calculate a copy of the segment end measure to preserve it in the overlay so I can work out its proportion to the line ends. I also calculate a duplicate of the MIN and MAX measures into two fields called FROM_MEAS and TO_MEAS so I can preserve one set of Measure field values in the Overlay output.
Even House Numbers on the Left Side of the Street
Even House Numbers on the Right Side of the Street
Odd House Numbers on the Left Side of the Street
Odd House Numbers on the Right Side of the Street
Here are the steps.
I created 2 fields with one named EVEN_ODD and the other named LEFT_RIGHT to simplify the selection and allow sorting that ignores the actual numeric values of the House Number and the Distance field. I calculated them to be:
Parser: VB Script
Show Codeblock: Checked
Prelogic Script Code:
If [HOUSE_NUMBER] = Round( [HOUSE_NUMBER] / 2, 0) * 2 Then Output = "EVEN_HOUSE" Else Output = "ODD_HOUSE" End If
EVEN_ODD = Output
For the LEFT_RIGHT field I changed the Prelogic Script Code to:
If [Distancec] > 0 Then Output = "LEFT_SIDE" Else Output = "RIGHT_SIDE" End If
Next I selected the set of Even Houses on the Left Side of the street and exported it to a new table named Address_Even_Left using the SQL:
"EVEN_ODD" = 'EVEN_HOUSE' AND "LEFT_RIGHT" = 'LEFT_SIDE'
Then in ArcCatalog I Load data into the Address_Even_Left table to duplicate the records from the original Locate Features Along Route output using the SQL above to limit the records to match the criteria for that table.
Then I run the Sort Tool on the Address_Even_Left with the sort set for:
RID Ascending
Measure Ascending
House_Number Ascending.
In the Sorted output I added a field called LINE_NUMBER. For tables where the first ObjectID is numbered one (1) I calculated it to be (reverse the logic if the first ObjectID is 0 for dbf tables):
Parser: VB Script
Show Codeblock: Checked
Prelogic Script Code:
If [OBJECTID] = Round( [OBJECTID] / 2 , 0) * 2 Then Output = [OBJECTID] + 1 Else Output = [OBJECTID] End If
LINE_NUMBER = Output
Next I run the Summary Statistics to covert the points to line events. The Summary Statistic settings are:
Input Table: Address_Even_Left_Sort
Output Table: Address_Even_Left_Lines
Statistics Fields:
ObjectID Min
ObjectID Max
Meas Min
Meas Max
Case Fields:
RID
LINE_NUMBER
In the output from that tool I added a field called FROM_HOUSE_NUMBER and TO_HOUSE_NUMBER. I joined the MIN_OBJECTID field to the ObjectID field of the Address_Even_Left_Sort and calculate the FROM_HOUSE_NUMBER field to equal the House_Number of the sorted table. I then broke that join and rejoined the MAX_OBJECTID field to the ObjectID field of the Address_Even_Left_Sort and calculate the TO_HOUSE_NUMBER field to equal the House_Number of the sorted table. The line event table has zero length lines at each end of the set pf house numbers or where only one house number occurred on the entire route.
Now I have a Line event table of where the Even house numbers on the Left of the line are listed for the correct ends of the lines as the measures increase on the route. House numbers can end up ascending or descending. Now I can use the Overlay Route Events tool with my road segment end point events to find the match of the lines and house numbers to the segment ends. I calculate a copy of the segment end measure to preserve it in the overlay so I can work out its proportion to the line ends. I also calculate a duplicate of the MIN and MAX measures into two fields called FROM_MEAS and TO_MEAS so I can preserve one set of Measure field values in the Overlay output.
22 Replies
08-06-2013
07:17 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
My theory for the workflow would be as follows
Am I on the right track? I am learning the code and formatting so will update as help is needed.
- Define the two feature classes (street centerline & address points)
- Define the field names I will be referencing for street name (STR_NAME in both)
- Create a search cursor that cycles through each address point record, and identifying its street name (Main, Oak, Broadway, etc)
- Output the street name from the address point
- Run a definition query for the centerline where STR_NAME = the output from address point street name
- Run the NEAR function for Address point to Centerline with this definition in effect(creating the appropriate fields)
- Clear the centerline definition query
- Next row in the Address Points
repeat
Am I on the right track? I am learning the code and formatting so will update as help is needed.
08-12-2013
09:29 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I maintain the street centerline for the City of Portland, Oregon, that is used in 911 dispatch.
A couple of thoughts. First, I'm intrigued by how you might end up solving your problem. I am fairly new to Python, and so we might find a need to do this ourselves at some point. We have fields on the segments for actual address ranges, but we have never populated those. Perhaps we could with your approach.
However, historically we have had the same issue with addresses not exactly matching theoretical address ranges, and those ranges are what we load into our systems for geocoding. In most cases addresses do not go up above 50, e.g the range for the block is 1000-1099, but the last address on the block is 1050. However, we also do quality control checks for contiguous ranges, and so if we did away with those, we'd be creating gaps where we might not want any. Have you thought about what the repercussions might be if you lose that contiguity? What happens if a new address is assigned above the actual range?
Also, since we went to a new CAD system (Versaterm) a couple of years ago, we now use address points as the primary method of geocoding. Address ranges are now the secondary method of geocoding. Using points instead of addresses seems to be the way geocoding is moving. So how important is it to have the ranges match the points?
Paul
---------------------------------------------------------
Paul Cone
Mapping and GIS
City of Portland, Bureau of Transportation
A couple of thoughts. First, I'm intrigued by how you might end up solving your problem. I am fairly new to Python, and so we might find a need to do this ourselves at some point. We have fields on the segments for actual address ranges, but we have never populated those. Perhaps we could with your approach.
However, historically we have had the same issue with addresses not exactly matching theoretical address ranges, and those ranges are what we load into our systems for geocoding. In most cases addresses do not go up above 50, e.g the range for the block is 1000-1099, but the last address on the block is 1050. However, we also do quality control checks for contiguous ranges, and so if we did away with those, we'd be creating gaps where we might not want any. Have you thought about what the repercussions might be if you lose that contiguity? What happens if a new address is assigned above the actual range?
Also, since we went to a new CAD system (Versaterm) a couple of years ago, we now use address points as the primary method of geocoding. Address ranges are now the secondary method of geocoding. Using points instead of addresses seems to be the way geocoding is moving. So how important is it to have the ranges match the points?
Paul
---------------------------------------------------------
Paul Cone
Mapping and GIS
City of Portland, Bureau of Transportation
08-13-2013
05:31 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Paul,
Thank you for your reply. I agree that address point geocoding is more accurate as you said and the way geocoding is headed. We do have an address point system with a fairly high degree of confidence (albeit with its own issues such as multi-tenant buildings).
Our fire department has decided upon the use of centerlines currently for throwing a broader net and the most likely chance of a �??hit�?? when creating an alarm. Often callers do not know their exact location or may say it in error which has been problematic when using the address points as the primary geocoding method. The points have higher spatial accuracy while streets give a better match rate. The address points are displayed to the dispatcher but are not the primary search model.
Our streets and addresses are fairly static as we are about 97%+ developed with very limited new growth. We would like to correct the ranges both for dispatch and future use of the centerline network. You also make a very important point for continuity which must be maintained. It is our hope to both improve our ranges (narrowing from the default 0-99) while maintaining continuity on each side of cross streets. The picture below from Kelly Bigley's process outlines what I'd like to accomplish. She used dynamic segmentation to then pull the first and last address on each street segment and then adjusts ranges based on percent distance between those endpoints and the cross streets.
[ATTACH=CONFIG]26667[/ATTACH]
Langdon
Thank you for your reply. I agree that address point geocoding is more accurate as you said and the way geocoding is headed. We do have an address point system with a fairly high degree of confidence (albeit with its own issues such as multi-tenant buildings).
Our fire department has decided upon the use of centerlines currently for throwing a broader net and the most likely chance of a �??hit�?? when creating an alarm. Often callers do not know their exact location or may say it in error which has been problematic when using the address points as the primary geocoding method. The points have higher spatial accuracy while streets give a better match rate. The address points are displayed to the dispatcher but are not the primary search model.
Our streets and addresses are fairly static as we are about 97%+ developed with very limited new growth. We would like to correct the ranges both for dispatch and future use of the centerline network. You also make a very important point for continuity which must be maintained. It is our hope to both improve our ranges (narrowing from the default 0-99) while maintaining continuity on each side of cross streets. The picture below from Kelly Bigley's process outlines what I'd like to accomplish. She used dynamic segmentation to then pull the first and last address on each street segment and then adjusts ranges based on percent distance between those endpoints and the cross streets.
[ATTACH=CONFIG]26667[/ATTACH]
Langdon
{kind=link}
08-13-2013
01:02 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
My theory for the workflow would be as follows
- Define the two feature classes (street centerline & address points)
- Define the field names I will be referencing for street name (STR_NAME in both)
- Create a search cursor that cycles through each address point record, and identifying its street name (Main, Oak, Broadway, etc)
- Output the street name from the address point
- Run a definition query for the centerline where STR_NAME = the output from address point street name
- Run the NEAR function for Address point to Centerline with this definition in effect(creating the appropriate fields)
- Clear the centerline definition query
- Next row in the Address Points
repeat
Am I on the right track? I am learning the code and formatting so will update as help is needed.
The relationship between points (address) and lines (network) is "many-to-1", so you need:
1. Using "Spatial Join" function (also called Near - in old ArcInfo version) to join line class to point class (point as target layer), the output joined point layer should have the line ID field;
2.Open the joined the point layer's attribute table, go to the ID field (from line layer), using "Field Summarize" function to get the Min and Max values for the Address number field (if the Address field data type is Text, convert it to Intege first), this summarized output should be one standalone table;
3.Using "Common Field" (line ID) to join that summarized standalone table back to the original line feature class, export it as one joined feature class;
4.In the joined line feature class, the Min field should be the start address number and the Max field should be the end address number - you can merge both fields to one new field (call it as Address Range) to fit your application.
08-14-2013
07:15 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The relationship between points (address) and lines (network) is "many-to-1", so you need:
1. Using "Spatial Join" function (also called Near - in old ArcInfo version) to join line class to point class (point as target layer), the output joined point layer should have the line ID field;
2.Open the joined the point layer's attribute table, go to the ID field (from line layer), using "Field Summarize" function to get the Min and Max values for the Address number field (if the Address field data type is Text, convert it to Intege first), this summarized output should be one standalone table;
3.Using "Common Field" (line ID) to join that summarized standalone table back to the original line feature class, export it as one joined feature class;
4.In the joined line feature class, the Min field should be the start address number and the Max field should be the end address number - you can merge both fields to one new field (call it as Address Range) to fit your application.
Thank you, I did not think of using a join then summarize. This may be a simpler answer than what I anticipated. Thank you and I'll give it a try.
Langdon
08-14-2013
07:37 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you, I did not think of using a join then summarize. This may be a simpler answer than what I anticipated. Thank you and I'll give it a try.
Langdon
It will not reliably work if you need continuous addresses on adjoining segments. It would only work well where the addresses are located close to the segment ends and the addresses at the ends represent the range across the segment's full length.
Where the addresses are far from the ends of the segment or you only have one address on a long segment of road in an area where additional developed could occur, or you have one segment with no addresses between two segments that have addresses, you would expect additional addresses to be created on the ends outside of the range of the current address(es). Determining positions along the lines relative to the ends of the lines is what Linear Referencing can much more easily analyze than a simple Spatial Join or Near tool match. It also is the only method that can deal with ordering your chains of segments that need to match up the ranges where their ends meet in a logical, sortable manner.
Linear Referencing is the only method that is capable of ordering adjoining road segments and lists of intersections along a given road according to the way you would actually drive a road from one end to the other. It is therefore ideal for this kind of problem.
08-14-2013
11:18 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank you, I did not think of using a join then summarize. This may be a simpler answer than what I anticipated. Thank you and I'll give it a try.
Langdon
For those line segs without joined address numbers, you can:
1. Extract those segs and export them as one feature class - class A, and export the another part segs (with address number) as the another feature class - class B;
2. Convert the class B to the point feature class - class C, then join (Intesect Spatial Join) the Class C to the class A - joined point class D;
3. Then join the class D table back to the Class A by using common field (line ID) and the output as Class E;
4. Open the Class E table, you can transfer the Min & Max number from joined fields (you need to know which one is Min & Max due to double Min & Max values joined - the larger Min value from both Min values is Max value for this seg, and less Max value from bothe Max values is Min value for this seg.
After above process, you may couldn't assign address for all non-address segs (ig. two adjacent non-address lines), you may need to repeat above process.
08-14-2013
11:26 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
For those line segs without joined address numbers, you can:
1. Extract those segs and export them as one feature class - class A, and export the another part segs (with address number) as the another feature class - class B;
2. Convert the class B to the point feature class - class C, then join (Intesect Spatial Join) the Class C to the class A - joined point class D;
3. Then join the class D table back to the Class A by using common field (line ID) and the output as Class E;
4. Open the Class E table, you can transfer the Min & Max number from joined fields (you need to know which one is Min & Max due to double Min & Max values joined - the larger Min value from both Min values is Max value for this seg, and less Max value from bothe Max values is Min value for this seg.
After above process, you may couldn't assign address for all non-address segs (ig. two adjacent non-address lines), you may need to repeat above process.
That simply does not work. If I have 4 addresses on a block, nothing says the block should begin and end with those addresses for creating ranges. That won't align them using geocoding either if there are many potential addresses between the last actual address and the block end. For example, if I have blocks at 1000 to 1100 and 1100 to 1200 as far as ranges, but addresses 1038 and 1058 as my min and max in the center of one segment and 1138 and 1158 as the min and max in the center of the other segment, the min and max values make no sense as the ranges. The whole reason to use ranges is potential addresses, so excluding them makes little sense. Better to use address points to only have exact matches and positions.
08-15-2013
05:19 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Determining positions along the lines relative to the ends of the lines is what Linear Referencing can much more easily analyze than a simple Spatial Join or Near tool match. It also is the only method that can deal with ordering your chains of segments that need to match up the ranges where their ends meet in a logical, sortable manner.
Linear Referencing is the only method that is capable of ordering adjoining road segments and lists of intersections along a given road according to the way you would actually drive a road from one end to the other. It is therefore ideal for this kind of problem.
Thank you Richard,
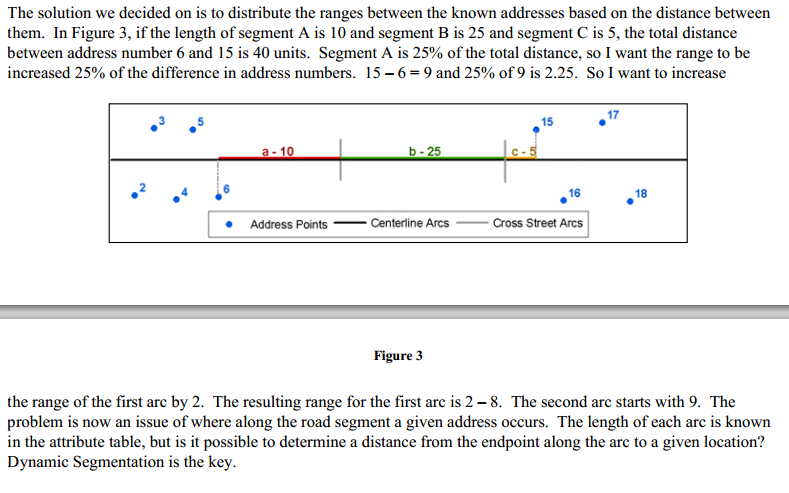
You're right and Linear Referencing has been my goal since the start. I would like to use it to both limit our ranges and maintain continuity on either side of cross streets. The address range should be updated based on the distance of the block not just the address number. Additional distance from the start and end of address events should be added to the address range. The first step was making sure the correct points are referenced to the correct streets. The paper I was working from was written in 2003 using the NEAR function by street name as a precursor to Lin. Ref. which may now be unnecessary.
[ATTACH=CONFIG]26722[/ATTACH]
Bigley later details her script process after linear referencing is performed:
"For each street name, it selects the min and max events that occur on that street name. For each event (in order from lowest to highest measure), it keeps track of the measure value and the address number for both the current event and the previous event. It selects the arc segments whose FMEAS and TMEAS encompass the previous measure value through to the current measure value. It then loops
through each of those selected arcs (in order from lowest to highest measure). It calculates the difference in measure values between the current and previous event and determines the percentage of that distance that occurs on that arc. That percentage is multiplied by the difference in address numbers. The result is added to the address number and put into the range field. The script keeps track of this new range number to add onto it for the next arc until it reaches the last arc for those events. The loop increments to the next event until there are no more events on that street name. The resulting address ranges represent more than the existing addresses and allow for very useful geocoding solutions."
The default address ranges is currently 100 units, 0-99, but often this can be narrowed to say 20 units, 0-19 (addresses 2-15) then the next street 20-39 (with addresses 24-37). These narrower ranges better our geocoding but maintain continuity.
Many of these ranges have been corrected manually by essentially the same process I hope to automate, looking at the nearby address points, then rewriting the ranges to a better match.
Thank you for all your input.
Langdon
{kind=link}