- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Arcpy Update Rows with Field Name
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have sixteen different feature classes that mostly have the same fields that share the same domain (Pass/Fail). I want to create a script that (1) creates a new FC bringing these all together,
New_Feature_Class field examples: [FirstFailure], [SecondFailure], and [ThirdFailure].
then (2) populates rows with Field Name IF [Field] = Fail.
If a row from one of the original 16 feature classes have no fields with a 'Fail', then none of the new [Failure] fields would get populated.
I've created the first part (below), I just can't even imagine how the second part happens.
import arcpy
from arcpy import *
import os
arcpy.env.overwriteOutput = True
database = "C:\\etc"
arcpy.env.workspace = database
fc_list = arcpy.ListFeatureClasses()
for fc in fc_list:
fieldname = "From_FC_Name"
arcpy.AddField_management(fc, fieldname, "TEXT", field_length = 20)
with arcpy.da.UpdateCursor(fc, fieldname) as cursor:
for row in cursor:
if row[0] == None:
row[0] = str(fc)
cursor.updateRow(row)
arcpy.ClearEnvironment("workspace")
final_fc = "path"
arcpy.CreateFeatureclass_management(final_fc)
arcpy.Append_management(fclist2, final_fc)
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Try this:
import arcpy
import os
arcpy.env.overwriteOutput = True
database = "C:\\etc"
common_flds = [
"UGI_BarrierNeeded",
"UGI_BarrierPost",
"UGI_BoltDown",
"UGI_CableDamaged",
"UGI_CableTags",
] # add all the common fields to list
new_flds = [
{"field_name":"From_FC_Name", "field_type":"TEXT", "field_length":20},
{"field_name":"FirstFailure", "field_type":"TEXT", "field_length":40},
{"field_name":"SecondFailure", "field_type":"TEXT", "field_length":40},
{"field_name":"ThirdFailure", "field_type":"TEXT", "field_length":40}
]
arcpy.env.workspace = database
fc_list = arcpy.ListFeatureClasses()
for fc in fc_list:
desc = arcpy.Describe(fc)
flds = [fld.name for fld in desc.fields if fld.name in common_flds]
for fld in new_flds:
arcpy.AddField_management(fc, **fld)
with arcpy.da.UpdateCursor(
fc,
flds + [fld["field_name"] for fld in new_flds]
) as cur:
for row in cur:
row[len(flds)] = fc
fails = [
flds[i]
for i, v
in enumerate(row[:len(flds)])
if v == "Fail"
]
for i, v in enumerate(fails):
row[len(flds) + 1 + i] = v
cur.updateRow(row)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am still a little confused what your final outcome will look like, but I can comment on a couple items. Regarding your cursor to update the "From_FC_Name." When checking for Python None, it is more idiomatic to use var is None. That said, isn't that check unnecessary? You just created a new field so everything should be NULL to start. I think lines #16 through #20 can be condensed down to:
with arcpy.da.UpdateCursor(fc, fieldname) as cursor:
for row in cursor:
cursor.updateRow([str(fc)])Regarding line #25, Create Feature Class requires at least 2 arguments and you are passing 1.
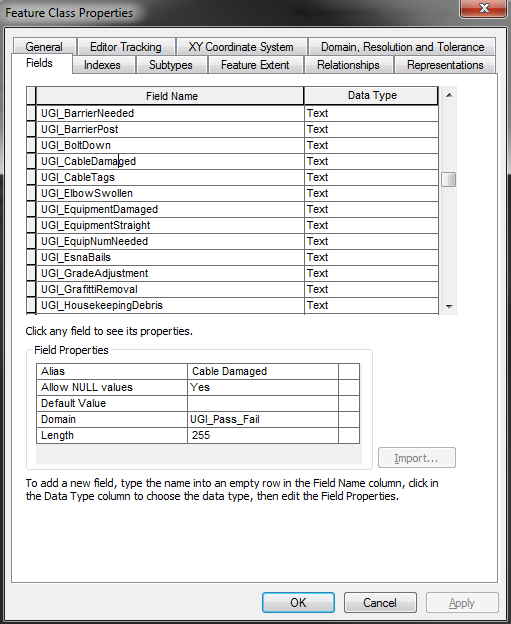
In your screenshot, are those all the common columns in the feature classes? Do you also want to add new columns to the merged feature class?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for your reply and sorry for the confusion. I'm new to python and scripting in general. Line #25 I did butcher for this post.
Yes, my screenshot is showing common columns in the 16 feature classes. All 16 feature classes get inspected for all the same things - we just keep them separated because they're different features (Poles vs. Transformers vs. Capacitors, etc).
My thought is that the "MergedFeatureClass" will have an additional 3-4 fields, on top of [From_FC_Name]. Those 3-4 additional fields would be named [FirstFailure], [SecondFailure], [ThirdFailure], etc. Rarely does an inspection have more than one fail.
So if CapacitorFeatureClass fails in the [UGI_GraffitiRemoval] column then I want the row under MergedFeatureClass' [FirstFailure] column to contain the attribute of "UGI_GraffitiRemoval". If Capacitor fails UGI_GraffitiRemoval and UGI_BarrierNeeded, then [FirstFailure] and [SecondFailure] would get populated with the respective column name.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
My suggestion is to process each feature class completely first, and then merge/append at the end. The code below is adopted from your original code and adds 4 new fields to each feature class and populates the fields as you described. If it works, you can add the final part to merge/append everything together.
import arcpy
import os
arcpy.env.overwriteOutput = True
database = "C:\\etc"
common_flds = [
"UGI_BarrierNeeded",
"UGI_BarrierPost",
"UGI_BoltDown",
"UGI_CableDamaged",
"UGI_CableTags",
] # add all the common fields to list
new_flds = [
{"field_name":"From_FC_Name", "field_type":"TEXT", "field_length":20},
{"field_name":"FirstFailure", "field_type":"TEXT", "field_length":40},
{"field_name":"SecondFailure", "field_type":"TEXT", "field_length":40},
{"field_name":"ThirdFailure", "field_type":"TEXT", "field_length":40}
]
arcpy.env.workspace = database
fc_list = arcpy.ListFeatureClasses()
for fc in fc_list:
for fld in new_flds:
arcpy.AddField_management(fc, **fld)
with arcpy.da.UpdateCursor(
fc,
common_flds + [fld["field_name"] for fld in new_flds]
) as cur:
for row in cur:
row[len(common_flds)] = fc
fails = [
common_flds[i]
for i, v
in enumerate(row[:len(common_flds)])
if v == "Fail"
]
for i, v in enumerate(fails):
row[len(common_flds) + 1 + i] = v
cur.updateRow(row)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Bix. I wish I knew enough to debug why this isn't working for me. Does this pass through if a cmmon_fld doesn't exist? For example if "UGI_BarrierNeeded" didn't exist in the Capacitor feature class, would it just go on to the next or fail?
I cannot get past line 32 in your example. I'm getting error: "A column was specified that does not exist." I put some print statements to help me get down to the bottom but I'm still clueless.
print("begin meat")
for fc in fc_list:
for fld in new_flds:
arcpy.AddField_management(fc, **fld)
with arcpy.da.UpdateCursor(fc,common_flds + [fld["field_name"] for fld in new_flds]) as cur:
print ("cur defined")
print (str(fld))
print (str(new_flds))
for row in cur:
print("begin row in cur")Here are the print results:
begin meat
cur defined
{'field_type': 'TEXT', 'field_name': 'ThirdFailure', 'field_length': 40}
[{'field_type': 'TEXT', 'field_name': 'From_FC_Name', 'field_length': 20}, {'field_type': 'TEXT', 'field_name': 'FirstFailure', 'field_length': 40}, {'field_type': 'TEXT', 'field_name': 'SecondFailure', 'field_length': 40}, {'field_type': 'TEXT', 'field_name': 'ThirdFailure', 'field_length': 40}]
Traceback (most recent call last):
File "C:\Users\..........py", line XX, in <module>
for row in cur:
RuntimeError: A column was specified that does not exist.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The fields can have missing values, i.e., records can have NULL for a field, but the columns listed must exist for my code snippet to work. I was under the impression that common columns existed in all of the feature classes. The code can be modified to handle missing columns, it might be a couple days before I can revisit it though.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Try this:
import arcpy
import os
arcpy.env.overwriteOutput = True
database = "C:\\etc"
common_flds = [
"UGI_BarrierNeeded",
"UGI_BarrierPost",
"UGI_BoltDown",
"UGI_CableDamaged",
"UGI_CableTags",
] # add all the common fields to list
new_flds = [
{"field_name":"From_FC_Name", "field_type":"TEXT", "field_length":20},
{"field_name":"FirstFailure", "field_type":"TEXT", "field_length":40},
{"field_name":"SecondFailure", "field_type":"TEXT", "field_length":40},
{"field_name":"ThirdFailure", "field_type":"TEXT", "field_length":40}
]
arcpy.env.workspace = database
fc_list = arcpy.ListFeatureClasses()
for fc in fc_list:
desc = arcpy.Describe(fc)
flds = [fld.name for fld in desc.fields if fld.name in common_flds]
for fld in new_flds:
arcpy.AddField_management(fc, **fld)
with arcpy.da.UpdateCursor(
fc,
flds + [fld["field_name"] for fld in new_flds]
) as cur:
for row in cur:
row[len(flds)] = fc
fails = [
flds[i]
for i, v
in enumerate(row[:len(flds)])
if v == "Fail"
]
for i, v in enumerate(fails):
row[len(flds) + 1 + i] = v
cur.updateRow(row)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks again Bixby. I'm already indebted to you and can hardly imagine you take this another step further.
That being said, I'll share that the script completed without error but the results are not as desired.
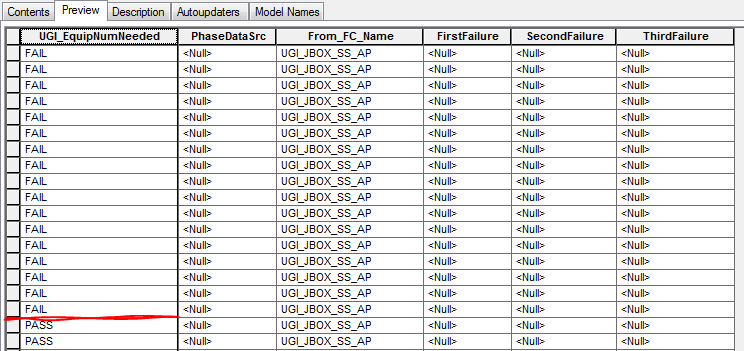
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Just change line 38 to:
if v == "FAIL"- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks to both of you. When I do change that line to == "FAIL", I get the error:
Traceback (most recent call last):
File "C:\....py", line XX, in <module>
row[len(flds) + 1 + i] = v
IndexError: list assignment index out of range