- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Alternative to concatenate field values
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Alternative to concatenate field values
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm creating a single feature class that will represent environmental areas within my study area. The environmental feature class is made up multiple feature classes that was merged, then union-ed . Each of the feature classes that were merged can contain a field "TYPE_RIV", "TYPE_WET", "TYPE_CBA", "TYPE_PROTECT".
What I'm trying to achieve is a better way of populating a new field "TYPE" that will concatenate the TYPE field (i.e. "TYPE_RIV", "TYPE_WET" etc.) values automatically based on the input environmental feature classes as this can differ from study area to study area. In other words in some cases there will be "TYPE_RIV", "TYPE_WET" and other cases there will be "TYPE_RIV", "TYPE_WET", "TYPE_CBA" lastly "TYPE_RIV", "TYPE_WET", "TYPE_CBA", "TYPE_PROTECT"
Once I've merged and union-ed the input feature classes, I'd like to identify the "TYPE_*" fields and concatenate the field fields into the new "TYPE" fields as per below:
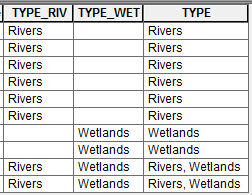
End Result Required:
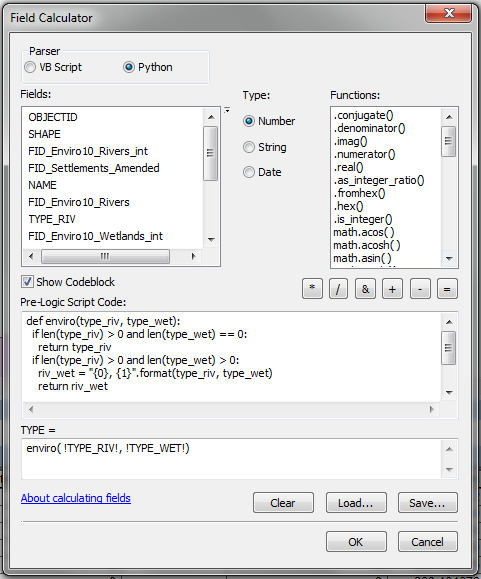
Current Code Block to Populate "TYPE" field
I can easily get the "TYPE_*" fields using s a list fields search, but how can an automatically populate the "TYPE" field concatenating the fields correctly based on the fields within the list as the if statements are hard coded and not sure how to get around the following.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Peter
You can construct a def from the example.
The key is to input your fields in the desired order of concatenation.
If a field is empty ("" or None, depending upont he database), then leave it out.
Format your concatenation string from a list of the good entries.
Pretend you have fields a,b,c,d,e with stuff inside...doesn't matter what, it will end up as a string, if unsure add {!s:} inside the curly braces. Play with this as a script, then 'def' it with
a = "A"
b = ""
c = "C"
d = None
e = "E"
flds = [a, b, c, d, e] # put in the ! marks
good = [ val for val in flds if val not in ["",None]] # LC omitting "", aka empty, can add None check
frmt = ("{}, "*len(good)).format(*good)
print(frmt[:-2])play with this, if you want commas etc separating, you can play with string strip methods, but I prefer parsing the length.
so as a function, you only need to provide the field names in the correct order to the function, the names don't matter and the concatenation will proceed as expected, regardless of the number of fields or their content. Check my blog for List comprehension and formatting posts for more information
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan
The following works great, just can't figure out how to use the following within an update cursor:
The following is how far I've gotten:
# environmental features within each settlement
def environmental_features(enviro_input):
enviro_intersect = []
for fcs in enviro_input:
orig_name = arcpy.Describe(fcs).name
input_features = ["Settlements_Amended", orig_name]
intersect_name = "{0}\\{1}_int".format("in_memory", orig_name)
arcpy.Intersect_analysis(input_features, intersect_name)
enviro_intersect.append(intersect_name)
merge_name = "{0}\\{1}_merge".format("in_memory", "Environmental")
arcpy.Merge_management(enviro_intersect, merge_name)
diss_name = "{0}\\{1}_diss".format(input_fgdb, "Environmental")
arcpy.Union_analysis(merge_name, diss_name, "ALL")
field_name = "ENVIRO_TYPE"
arcpy.AddField_management(diss_name, "ENVIRO_TYPE",
"TEXT",
field_length=100)
field_names = [f.name for f in arcpy.ListFields(diss_name, "TYPE*", "TEXT")]
cur_fields = list(field_names)
cur_fields.append(field_name)
with arcpy.da.UpdateCursor(diss_name, cur_fields)as ucur: # @UndefinedVariable
for row in ucur:
print row[0], row[1]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
so are you needing to implement the good and frmt lines in my example? you have cur_fields which is the equivalent to my flds (assuming they are field names and not field objects), then you have the frmt line which removes any "" or None (which you now have because you must be working with a gdb). so did you try appending with mods the salient lines into your function? so row 23 is where you do the concatenation of those field values that have values. Cavaet...the order of the fields determines the order of the outputs, that is where the field calculator expression offers some flexibility
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan
The problem is that I'm not sure how to get the field values without having to specify the field index and the last field row[2] = ""ENVIRO_TYPE", is the field I need to update. row[0] = "TYPE_RIV", row[1] = "TYPE_WET" this time but it won't always be the case. Any suggestions welcome 
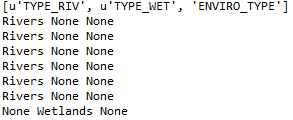
Print Statement:
# environmental features within each settlement
def environmental_features(enviro_input):
enviro_intersect = []
for fcs in enviro_input:
orig_name = arcpy.Describe(fcs).name
input_features = ["Settlements_Amended", orig_name]
intersect_name = "{0}\\{1}_int".format("in_memory", orig_name)
arcpy.Intersect_analysis(input_features, intersect_name)
enviro_intersect.append(intersect_name)
merge_name = "{0}\\{1}_merge".format("in_memory", "Environmental")
arcpy.Merge_management(enviro_intersect, merge_name)
diss_name = "{0}\\{1}_diss".format("in_memory", "Environmental")
arcpy.Union_analysis(merge_name, diss_name, "ALL")
field_name = "ENVIRO_TYPE"
arcpy.AddField_management(diss_name, "ENVIRO_TYPE",
"TEXT",
field_length=100)
field_names = [f.name for f in arcpy.ListFields(diss_name, "TYPE*", "TEXT")]
cur_fields = list(field_names)
cur_fields.append(field_name)
print cur_fields
with arcpy.da.UpdateCursor(diss_name, cur_fields)as ucur: # @UndefinedVariable
for row in ucur:
print row[0], row[1], row[2]Python Code:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
do you mean....
print( "{}, "*len(row)).format(*row))
doesn't work with cursors?
(sorry, I rarely use them)
If it works, then you just need to assembly the values if they aren't "" or None as shown
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan
I've used slicing to select the correct fields that are defined within my UpdateCursor as the fields are made up of:
- "TYPE_RIV", "TYPE_WET", "TYPE_CBA" (input to good)
- "ENVIRO_TYPE" (output field to be populated)
field_name = "ENVIRO_TYPE"
arcpy.AddField_management(union_name, "ENVIRO_TYPE", "TEXT", field_length=100)
enviro_fields = [f.name for f in arcpy.ListFields(union_name, "TYPE*", "TEXT")]
enviro_fields.append(field_name)
with arcpy.da.UpdateCursor(union_name, enviro_fields )as upcur: # @UndefinedVariable
for row in upcur:
good = [val for val in list(row[:-1]) if val not in["", None]]
frmt = ("{}, "*len(good)).format(*good)
row[-1] = frmt
upcur.updateRow(row)
print row[-1]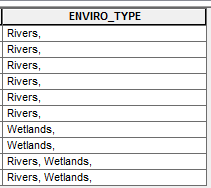
Thanks for all the help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
now if you want to get rid of that pesky ", " at the end, then you can simply use the slice of frmt[:-2] for that
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Dan 
Was just thinking about that. I was considering using a nested if statement to test the length of records for each row to remove the "space" after the "," where there is only one item and to remove the "," at the end.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan
The following dealt with both the "space" and "," thanks so much
Regards