- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Advice on "roll up" / consolidation tool
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
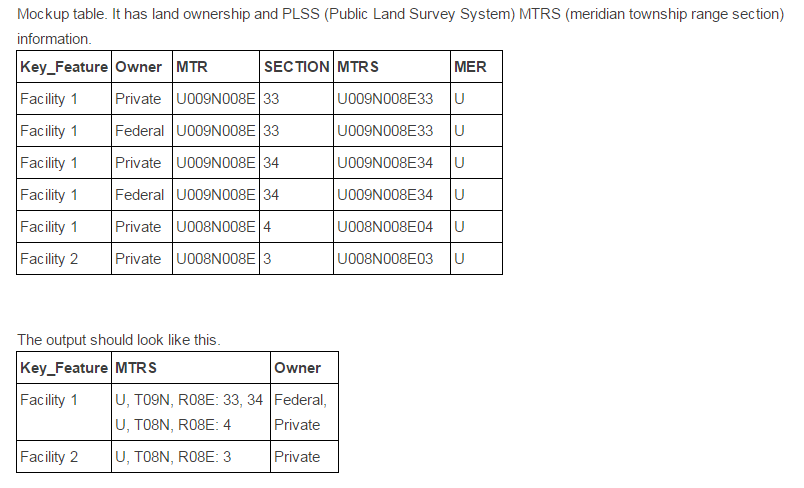
I need to make a script tool that will consolidate attributes from many rows into to one across a number of columns. The tool will need to be able to let the user select the field "key" field as well as the fields that will be consolidated. I made a quick mockup table as my input table (it has been processed with spatial sort so that parts of the key features that are spatially adjacent to each other are also in adjacent rows in the table).
Mockup table. It has land ownership and PLSS (Public Land Survey System) MTRS (meridian township range section) information.
| Key_Feature | Owner | MTR | SECTION | MTRS | MER |
| Facility 1 | Private | U009N008E | 33 | U009N008E33 | U |
| Facility 1 | Federal | U009N008E | 33 | U009N008E33 | U |
| Facility 1 | Private | U009N008E | 34 | U009N008E34 | U |
| Facility 1 | Federal | U009N008E | 34 | U009N008E34 | U |
| Facility 1 | Private | U008N008E | 4 | U008N008E04 | U |
| Facility 2 | Private | U008N008E | 3 | U008N008E03 | U |
The output should look like this.
| Key_Feature | MTRS | Owner |
| Facility 1 | U, T09N, R08E: 33, 34 U, T08N, R08E: 4 | Federal, Private |
| Facility 2 | U, T08N, R08E: 3 | Private |
The question: I would like input on the best method to get the result. And if there are any out of the box Arc tools that I could leverage...
My first pass at this was to use arcpy.da.SearchCursor and iterate over the input table and check to see if the current row's key feature is the same as the previous row's key feature. If so, then add it to a string variable. When the key features do not match write the string variable and other fields to the output file. The MTRS roll up is a little more complex because sections needs to rolled up for each unique MTR associated with the key feature. It feels a little wired because you are always looking back in rows as you iterate over the table. So, I used a number of temp_last variables for key features, MTRS, etc. I was thinking that it would be better to read the whole table into a list of lists and then use that to generate the output. That way I could use indexing to look at the next and last rows without having to use the temp_last variables.
The below code I made for a similar one off.
import arcpy
import os
arcpy.env.overwriteOutput = True
in_path = r"xxxx"
out_path ="xxxx"
def tsv_write(tsv_row):
for item in tsv_row:
tsv.write(item + "\t")
tsv.write("\n")
def rollup(rollup_list):
rollup_list = set(rollup_list)
rollup_list = list(rollup_list)
rollup_list.sort()
rollup_str = ""
for sec in rollup_list:
rollup_str = rollup_str + str(sec) + ", "
rollup_str = rollup_str[:-2]
return rollup_str
def from_to_fix(x):
x = round(x, 1)
x = str(x)
return x
search_cursor = arcpy.da.SearchCursor(in_path, ["Main_LandOwnership_MTRS_Mbook_Meridian",
"Main_LandOwnership_MTRS_Mbook_Town_Range",
"Main_LandOwnership_MTRS_Mbook_SECTION",
"Main_LandOwnership_MTRS_Mbook_F_MP",
"Main_LandOwnership_MTRS_Mbook_T_MP",
"Main_LandOwnership_MTRS_Mbook_Index_Order",
"Main_LandOwnership_MTRS_Mbook_ROW_Designation"])
tsv = open(out_path, "w")
meridian_last = None
township_last = None
f_mile_last = None
t_mile_last = None
owner_last = None
township_list = []
township_section_list = []
first_row_flag = True
township_append_flag = True
section_list = []
index_order_list = []
for row in search_cursor:
meridian = row[0]
township = row[1]
section = row[2]
f_mile = row[3]
t_mile = row[4]
index_order = row[5]
owner = row[6]
if first_row_flag:
township_last = township
f_mile_last = f_mile
t_mile_last = t_mile
owner_last = owner
first_row_flag = False
if township == township_last:
township_append_flag = True
section_list.append(int(section))
else:
township_append_flag = False
section_rollup = rollup(section_list)
township_section_list.append(township_last + ": " + section_rollup)
section_list = []
section_list.append(int(section))
if f_mile == f_mile_last:
index_order_list.append(int(index_order))
else:
index_order_rollup = rollup(index_order_list)
write_flag = True
for trs in township_section_list:
if write_flag:
write_flag = False
print [from_to_fix(f_mile_last), from_to_fix(t_mile_last), trs, owner_last, index_order_rollup]
tsv_write([from_to_fix(f_mile_last), from_to_fix(t_mile_last), trs, owner_last, index_order_rollup])
else:
print ["", "", trs, "", ""]
tsv_write(["", "", trs, "", ""])
township_section_list = []
index_order_list = []
index_order_list.append(index_order)
if meridian != meridian_last:
print meridian
tsv_write([meridian])
print ["From MP", "To MP", "MTRS", "Ownership", "Map Book Sheet"]
tsv_write(["From MP", "To MP", "MTRS", "Ownership", "Map Book Sheet"])
meridian_last = meridian
township_last = township
f_mile_last = f_mile
t_mile_last = t_mile
owner_last = owner
if not township_append_flag:
township_section_list.append(township_last + ": " + str(int(section)))
index_order_rollup = rollup(index_order_list)
write_flag = True
for trs in township_section_list:
if write_flag:
write_flag = False
print [from_to_fix(f_mile_last), from_to_fix(t_mile_last), trs, owner_last, index_order_rollup]
tsv_write([from_to_fix(f_mile_last), from_to_fix(t_mile_last), trs, owner, index_order_rollup])
else:
print ["", "", trs, "", ""]
tsv_write(["", "", trs, "", ""])
township_section_list = []
index_order_list = []
index_order_list.append(index_order)
tsv.close()
Thanks for any input!
Forest
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I think this will work for you:
from collections import defaultdict
tbl = # path to table
flds = "Key_Feature Owner MTRS".split() # list of string field names
rollup_tbl = arcpy.CreateTable_management("in_memory", "rollup")
for fld in flds:
arcpy.AddField_management(rollup_tbl, fld, "TEXT")
kf_dict = defaultdict(lambda:{'owner':set(), 'mtrs':defaultdict(set)})
with arcpy.da.SearchCursor(tbl, flds) as cur:
for kf, owner, mtrs in cur:
kf_dict[kf]['owner'].add(owner)
kf_dict[kf]['mtrs'][mtrs[:-2]].add(mtrs[-2:])
with arcpy.da.InsertCursor(rollup_tbl, flds) as cur:
for k,v in kf_dict.items():
kf = k
owner = ",".join(v['owner'])
mtrs = ["{}, T{}, R{}: {}".format(mtr[0],
mtr[2:5],
mtr[6:9],
",".join(sec))
for mtr,sec
in v['mtrs'].items()]
cur.insertRow([kf, owner, "\n".join(mtrs)])The code above relies on nested defautldict to do the aggregation. It turns out the aggregation is much simpler than formatting the MTRS output the way you want it. The code creates an in-memory table for storing the results. Since I put a newline character to break up the different MTRS items, you won't see everything on the single row when looking at the table in ArcMap. If you print the results or create a report, it will all be there.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Can you put some cell boundaries around your output table to make it more clear what is in what row? Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I did try. They show up fine in the edit space but once it is posted the borders disappear 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
How can the aggregated Facility 2 have Section 4 when that section is associated with a row for Facility 1.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Because I went too fast when making the mockup. Sorry for the confusion. I fixed it up.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
How would the results of the output change if if the fourth line in the original table was removed? If a single record for Facility X has either Private or Federal, does Private or Federal show up in the output table regardless of how many of the other types of ownership are present?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Joshua Bixby wrote:
How would the results of the output change if if the fourth line in the original table was removed?
The output would be the same. I think of it in this way. I have a facility polygon layer that is intersected with an MTRS polygon and then also with a land ownership polygon. This cuts the facility polygon into many pieces. Then for each facility, we want to report its MTRS and land ownership. But we only want to list the facility once in the final table.
Joshua Bixby wrote:
If a single record for Facility X has either Private or Federal, does Private or Federal show up in the output table regardless of how many of the other types of ownership are present?
Not sure if I understand your question... But with that said. If Facility X has a row that reports it is on Federal then Federal should be included in the output no matter what other land ownership types are in other rows.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I think this will work for you:
from collections import defaultdict
tbl = # path to table
flds = "Key_Feature Owner MTRS".split() # list of string field names
rollup_tbl = arcpy.CreateTable_management("in_memory", "rollup")
for fld in flds:
arcpy.AddField_management(rollup_tbl, fld, "TEXT")
kf_dict = defaultdict(lambda:{'owner':set(), 'mtrs':defaultdict(set)})
with arcpy.da.SearchCursor(tbl, flds) as cur:
for kf, owner, mtrs in cur:
kf_dict[kf]['owner'].add(owner)
kf_dict[kf]['mtrs'][mtrs[:-2]].add(mtrs[-2:])
with arcpy.da.InsertCursor(rollup_tbl, flds) as cur:
for k,v in kf_dict.items():
kf = k
owner = ",".join(v['owner'])
mtrs = ["{}, T{}, R{}: {}".format(mtr[0],
mtr[2:5],
mtr[6:9],
",".join(sec))
for mtr,sec
in v['mtrs'].items()]
cur.insertRow([kf, owner, "\n".join(mtrs)])The code above relies on nested defautldict to do the aggregation. It turns out the aggregation is much simpler than formatting the MTRS output the way you want it. The code creates an in-memory table for storing the results. Since I put a newline character to break up the different MTRS items, you won't see everything on the single row when looking at the table in ArcMap. If you print the results or create a report, it will all be there.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks, Bixby! That is so much better than the way I was doing it.
I have one more question: how do you suggest creating the default dict dynamically when the number of input keys is not known? For example, the user may want to roll up just mtrs, mtrs and owner, mtrs, owner, and mapbook page, etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If you are using ArcGIS 10.4.x or newer, than Python Data Analysis Library — pandas: Python Data Analysis Library is really the way to go. Here is my original code reworked using pandas:
from pandas import DataFrame
from collections import defaultdict
tbl = # path to table
flds = "Key_Feature Owner MTRS".split() # list of string field names
rollup_tbl = arcpy.CreateTable_management("in_memory", "rollup")
for fld in flds:
arcpy.AddField_management(rollup_tbl, fld, "TEXT")
index_field = flds[0]
with arcpy.da.SearchCursor(tbl, flds) as cur:
df = DataFrame.from_records(cur, columns=cur.fields)
rollup = df.groupby(index_field).aggregate(lambda x: set(x))
with arcpy.da.InsertCursor(rollup_tbl, flds) as cur:
for index, groups in rollup.to_dict('index').items():
row = [index]
for fld in flds[1:]:
if fld.upper() == "MTRS":
split = ((i[0], i[2:5], i[6:9], i[9:]) for i in groups[fld])
secs = defaultdict(set)
for mer, twn, rng, sec in split:
mtr = "{}, T{}, R{}: ".format(mer, twn, rng)
secs[mtr].add(sec)
row.append("; ".join(i for
i in
(k + ", ".join(v) for k,v in secs.items())))
else:
row.append(", ".join(i for i in groups[fld]))
cur.insertRow(row)The re-worked code is dynamic. It will take a list of fields and use the first field as the index and group by the other fields in the list. Outside of MTRS, I assumed the values could just be concatenated together with commas.