- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Add rows to csv in python loop?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Add rows to csv in python loop?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi everyone,
I've created a loop that exports attached photos from a gdb. As part of the loop, it renames each of the attachments based on a field in the gdb, the date, and which photo it is (for example, if there are 2 photos associated with a row, it would put out something like "Account22_20200921_photo1.jpg" and "Account22_20200921_photo2.jpg." I would love to create a .csv file that mirrors this output. The first field would be the Account # ("Account22") and the second field would be the full file name ( "Account22_20200921_photo1.jpg"). I'm still pretty new to python, so please go easy on me. I would just like to add to my loop something that appends a csv with a row relating to each exported file. Here is the current section of my code that is doing this looping work:
#get the name of the gdb for work
for gdb in os.listdir(wdir):
if gdb.endswith(".gdb"):
gdb = gdb
#get the table in the gdb that references the photos
origTable = os.path.join(wdir, gdb, "Parcels_Needing_Photos")
#get the attach table
attachTable = "{}__ATTACH".format(origTable) # if no attachTable given, append __ATTACH to origTable
nameField = "AccountNo"# appropriate name field in origTable
dateField = "EditDate" #date field from the origtTable
#set the location for output photos
photofolder = r"C:\outputphotos"
origFieldsList = ["GlobalID", "OBJECTID", nameField, "CreationDate"] # GlobalID for linking, OBJECTID for renaming, nameField for renaming
# Use list comprehension to build a dictionary from a da SearchCursor
valueDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(origTable, origFieldsList)}
with arcpy.da.SearchCursor(attachTable, ['DATA', 'ATT_NAME', 'ATTACHMENTID', 'REL_GLOBALID']) as cursor:
for item in cursor:
attachment = item[0] # attachment data
filenum = "NA"
filename = filenum + str(item[1]) # this will be the filename if linking fails
# store the Join value of the row being updated in a keyValue variable
keyValue = item[3] # REL_GLOBALID
# verify that the keyValue is in the Dictionary
if keyValue in valueDict:
#filenum =str(item[2]) + "_"
filenum = 1
# transfer the values stored under the keyValue from the dictionary to the updated fields.
obID = valueDict[keyValue][0]
# remove invalid filename characters, replace spaces and periods, limit length
namefield = re.sub('[^0-9a-zA-Z]+', '_', valueDict[keyValue][1])[:18]
# convert the date-time into filename-appropriate format
time = valueDict[keyValue][2]
datefield = time.strftime("%Y%m%d")
# Create a unique filename ObjectID_AttachmentID_namefield.ext
ext = filename.rsplit('.', 1)[-1] # keep extension of original file
filename = "{}_{}_{}.{}".format(namefield, datefield ,str(item[1]),ext)
folder = photofolder #this needs to be the CAMA attachments directory
slash = "\\" #creating the joiner between msater director and subfolder
fileLocation = "{}{}{}".format(folder, slash , namefield, filenum) #set the output directory to match the account #
open(fileLocation + os.sep + filename, 'wb').write(attachment.tobytes())
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You can use something like DictWriter to create a csv file. However, I usually do something a bit more basic, usually using tab delimited files:
# before your loop, open a new file
fw = open("outputfile.txt", "w") # can be .csv
for item in some_loop:
# do things ...
path = "Account22"
filename = "Account22_20200921_photo1.jpg"
# write a line - \t = tab character and \n = new line
fw.writelines("{}\t{}\n".format(path, filename))
# after the loop, close the file
fw.close()Your code would be a bit easier to read with formatting. See: Code Formatting... the basics++
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
To add code to your post and have it get syntax highlighted, click the ellipse button (if there is one):
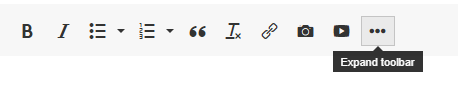
Then click the More drop-down and select syntax highlighter:
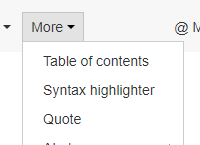
That will let you add your code and it will look like this:
#get the name of the gdb for work
for gdb in os.listdir(wdir):
if gdb.endswith(".gdb"):
gdb = gdb
#get the table in the gdb that references the photos
origTable = os.path.join(wdir, gdb, "Parcels_Needing_Photos")
#get the attach table
attachTable = "{}__ATTACH".format(origTable) # if no attachTable given, append __ATTACH to origTable
nameField = "AccountNo"# appropriate name field in origTable
dateField = "EditDate" #date field from the origtTable
#set the location for output photos
photofolder = r"C:\outputphotos"
origFieldsList = ["GlobalID", "OBJECTID", nameField, "CreationDate"] # GlobalID for linking, OBJECTID for renaming, nameField for renaming
# Use list comprehension to build a dictionary from a da SearchCursor
valueDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(origTable, origFieldsList)}
with arcpy.da.SearchCursor(attachTable, ['DATA', 'ATT_NAME', 'ATTACHMENTID', 'REL_GLOBALID']) as cursor:
for item in cursor:
attachment = item[0] # attachment data
filenum = "NA"
filename = filenum + str(item[1]) # this will be the filename if linking fails
# store the Join value of the row being updated in a keyValue variable
keyValue = item[3] # REL_GLOBALID
# verify that the keyValue is in the Dictionary
if keyValue in valueDict:
#filenum =str(item[2]) + "_"
filenum = 1
# transfer the values stored under the keyValue from the dictionary to the updated fields.
obID = valueDict[keyValue][0]
# remove invalid filename characters, replace spaces and periods, limit length
namefield = re.sub('[^0-9a-zA-Z]+', '_', valueDict[keyValue][1])[:18]
# convert the date-time into filename-appropriate format
time = valueDict[keyValue][2]
datefield = time.strftime("%Y%m%d")
# Create a unique filename ObjectID_AttachmentID_namefield.ext
ext = filename.rsplit('.', 1)[-1] # keep extension of original file
filename = "{}_{}_{}.{}".format(namefield, datefield ,str(item[1]),ext)
folder = photofolder #this needs to be the CAMA attachments directory
slash = "\\" #creating the joiner between msater director and subfolder
fileLocation = "{}{}{}".format(folder, slash , namefield, filenum) #set the output directory to match the account #
open(fileLocation + os.sep + filename, 'wb').write(attachment.tobytes())First, I want to point out that it seems like you have either overlooked something or not implemented something you were planning to. In:
fileLocation = "{}{}{}".format(folder, slash , namefield, filenum) #set the output you have three sets of braces but 4 inputs to format. Personally, I don't like using format and, if it's path items, I would implement os.path and use os.path.join like:
implement os.path
output = os.path.join(folder, namefield+str(filenum))or, if I'm absolutely going to use format, I always add the numbers so I'm clear what's going where like:
filename = "{0}_{1}_{2}.{3}".format(namefield, datefield ,item[1],ext)You also don't need to add the str funciton as format does that automatically. The only reason I would do format was if I wanted to actually ensure a specific string format (like two-decimal place or a percentage). I wouldn't use format to just concatenate. I would just write:
filename = namefield+"_"+datefield+"_"+str(item[1])+"."+ext
#vs
filename = "{}_{}_{}.{}".format(namefield,datefield,item[1],ext)Not only is it less to type, but it's simpler (imo) and I'm pretty sure it's faster to compute.