- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: 5 million Point buffer analysis
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi,
I have 5 million points and I would like to generate buffer and find the points that falls in each buffer region and perform some calculation.
I have tried with Spatial join and getting out of memory exception and finally I am trying with Multiprocessing.
I would like to know, Is there any other way we can do this more efficiently in python or any other method.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The tool 'Generate Near Table' (BTW: only available at the ArcInfo license level) would also work for something like this... Basically it builds a distance-based one-to-many association table. A warning that the resulting output table is often many orders of magnitude larger than the number of input features - the explanation being that one house can be within 100 miles of many different restaurants. Be sure to apply a search radius! As a experiment, you might 1st apply a very small search radius (< 1 mile) so as to see the format of the output data you will be dealing with.... before you accidently end up with an output table that is 300 million records.
If you are running out of RAM, consider installing the 64-bit background geoprocessor: Background Geoprocessing (64-bit)—Help | ArcGIS for Desktop
Not sure exactly what you are doing here, but I think initially if I were doing this in a script, I would just loop through the restaurants, and select the houses, gather their stats, and write out some result. Something like:
foodPnts = r"C:\temp\test.gdb\restaurants"
housePnts = r"C:\temp\test.gdb\houses"
arcpy.MakeFeatureLayer_management(housePnts, "fl")
searchRows = arcpy.da.SearchRows(foodPnts, ["SHAPE@", "RESTAURANT_ID"])
for searchRow in searchRows:
shapeObj, restaurantId = searchRow
arcpy.SelectLayerByLocation_management("fl", "INTESECT", shapeObj, "100 MILES")
recordCount = int(arcpy.GetCount_management("fl").getOutput(0))
print("There are " + str(recordCount) + " houses within 100 miles of restaurant #" + str(restaurantId))
#using the selected features/records in "fl", you now have a hook so as to get their names, incomes, etc.
#blah, blah...
del searchRow, searchRows
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
how many buffers? the obvious thing would be to spatially tile your data since it will be apparent which points can possibly fall within each buffer. multiprocessing, hadoop ( Esri GitHub | Open Source and Example Projects from the Esri Developer Platform ) will probably not be the way to go, since the problem needs to be formed within a different spatial context
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan, thanks for the quick reply.
Below is the sample image, The layer has 5Million points and i have to generate 5 Million buffers. After Generating buffer i have to perform spatial query similar point layer which has same amount of data.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
that is the point I am not clear on...you say you have 5 million points that you want to buffer and then you want to do a spatial query with 5 million other(?) buffers?
- where are those buffers?
- what is the purpose of the buffer?
- are you looking for some kind of density map? or a proximity map?
- do you have access to the spatial analyst?
- can you show an example using a smaller data set of what you are trying to do since the problem needs clarification
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
have a look at kernel density Kernel Density—Help | ArcGIS for Desktop
point density Point Density—Help | ArcGIS for Desktop
optimized hotspot Optimized Hot Spot Analysis—Help | ArcGIS for Desktop
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan,
I am performing proximity overlay analysis to find the points within circle.
Here is the sample senario, I would like to find the houses that are around my restaurant using 100 mile buffer.
As per below image:
Green color point is my restaurant and brown color points are houses.
I have performed proximity analysis to find the houses around my restaurant in 100 mile radius.
Based on 100 mile radius buffer i will select the house and perform some additional calculations.
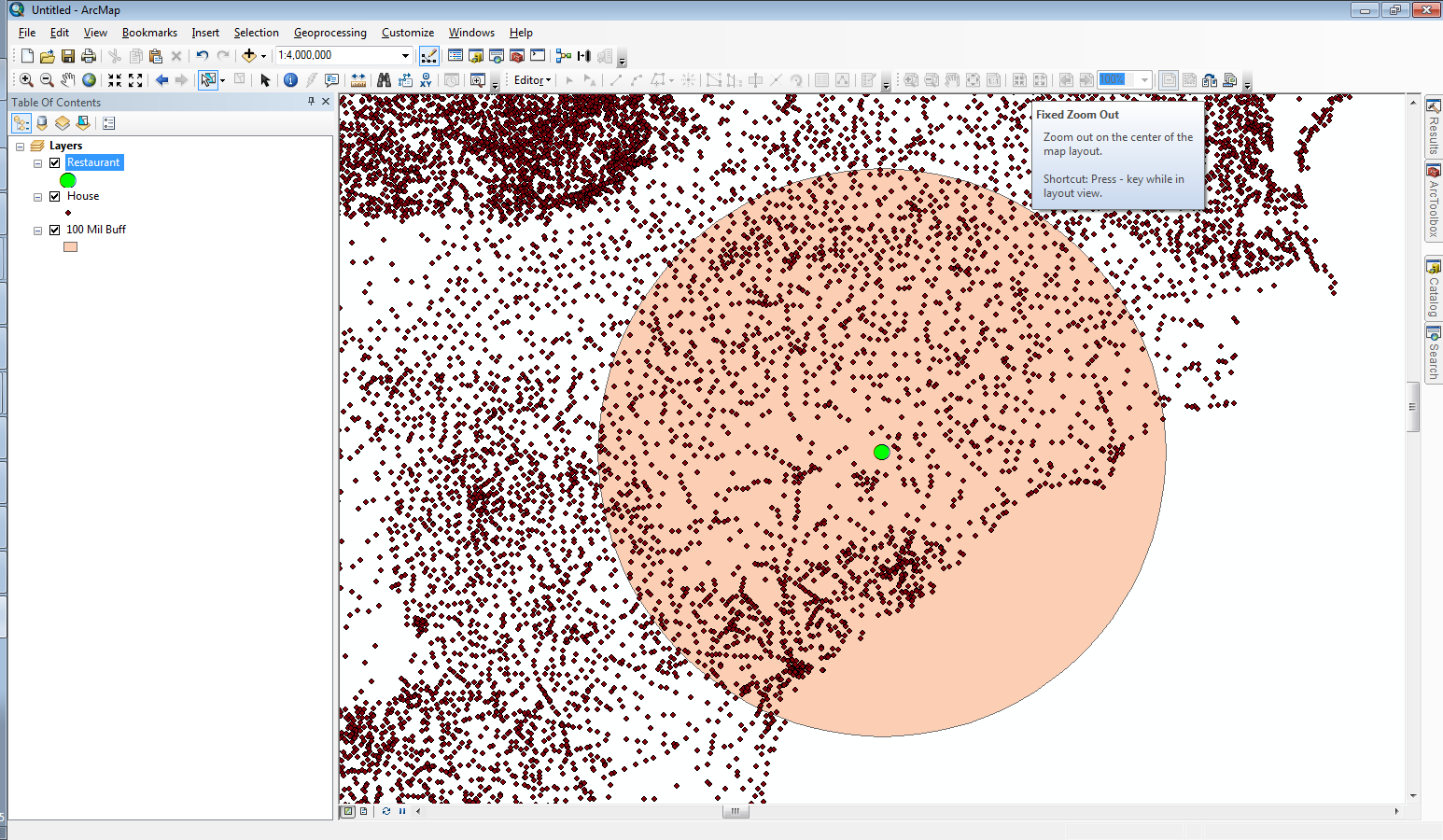
I am able to perform this analysis successfully with around 2 Million data using spatial join.
the problem is when I try to execute this analysis with 5 million data i am facing out of memory exception. Is there any other option to perform this proximity analysis more efficiently in large data.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
first, since you can see your buffer, you could do one of the following
- roughly draw a rectangle around your buffer using the selection tool to select the points that are within your buffer zone... selections are used when using most tools in ArcToolbox. That will limit the candidate sites.
- you could perform the same selection and save the results to a new file for further analysis
- you seem to be interested in euclidean distance and not network distance so that further simplifies the analysis.
- you can simply perform a select by spatial location using the previously rectangular area points using them as the target and the buffer circle as the selector. This will give you all the points that are within the buffer circle
- if you are really stuck on the idea of doing distance measurements, then determine the points that are within the buffer radius distance using numpy Before I forget ... # 16 ... NumPy vs SciPy... making a point this is extreme overkill and not needed.
In short... don't rely solely on the software to solve the problem...human brain intervention often simplifies problems to acceptable levels...since you can see the points that are within the buffer...select them roughly, then fine-tune the selection using arctoolbox tools...
- select by spatial location in the analysis,distance toolset
- the Point distance or Near tool if you have the advanced license
- or numpy, as per the solution in the link I provided.
So....
- limit your candidate sites in a quasi-interactive way or use tools which can handle large point masses, numpy can be used to substitute for tools that you don't have the necessary license for
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In addition to the previous long post...other aspects to consider
- what makes you think that people from 100 miles around are going to your restaurant as their primary destination? Perhaps, the target radius is too big. have you performed any analysis on-site that indicates that "people are coming from miles around"... and if so, how many?
- the target audience within a 100 mile buffer may bear no resemblence to those within the immediate neighbourhood of your restaurant. Are the socio-economic conditions uniform within the landscape? Will they all likely have the ability to dine out? are they willing to travel large distances?
- You are only considering euclidean distance currently... a good first step, however, the actual travel distance by road can be a totally different story.
So these non-distance characteristics can be further used to limit the candidates for the study, pruning them down by attribute and by spatial location making the problem more manageable.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
thanks for the reply. I have already tried to limit the candidate using following approaches
-used Fishnet (To find buffer regions)
-Creating bounding box around the circle
-Find an Identical location (to eliminate duplicate points(locations))
Currently, I am trying to find the points using Generate Near Table—Help | ArcGIS for Desktop Because it supports finding the more than one near features.
I am currently using arcpy.da.TableToNumPyArrayTableToNumPyArray—Data Access module | ArcGIS for Desktop to store the results in a separate table.
The use case which i explained was a sample one and we have similar different use cases with reasonable use stories.I will try all your above suggestions to restrict the points and will post the update once I am done.
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
after limiting the candidates either method should work. The numpy approach with calculating the distances can be completed using a np.where statement querying for only those locations that have a distance less than your threshold distance