I had made reference before of using numpy and arcpy together to perform particular tasks. Sometimes the combination of the two enables the user to do things they wouldn't otherwise be able to do. This ditty presents a very simple way to sort a dataset and produce a permantly sorted version while maintaining the original feature identification numbers. So to begin with, I will remind/introduce the reader to the arcpy data access module's functions as well as comparable ones in numpy.
On the arcmap side, the user should become familiar with:
- arcpy.Describe
- arcpy.Sort
- arcpy.da.FeatureClassToNumPyArray and
- arcpy.da.NumPyArrayToFeatureClass.
From the numpy side:
- np.setprintoptions
- np.arange and
- np.sort
The latter performs the same work as arcpy.Sort, but it doesn't have any license restrictions as the Sort tool does. It also allows you to produce a sequential list of numbers like the oft used Autoincrement field calculator function.
The script will perform the following tasks:
- import the required modules,
- specify the input file,
- the spatial reference of the input,
- the fields used to sort on, in the order of priority,
- a field to place the rank values, and
- specify the output file.
One can add the field to place the ranks into ahead of time or add a line of code to do it within the script (see arcpy.AddField_management).
import numpy as np
import arcpy
np.set_printoptions(edgeitems=4,linewidth=75,precision=2,
suppress=True,threshold=10)
arcpy.env.overwriteOutput = True
input_shp = r'c:\!Scripts\Shapefiles\RandomPnts.shp'
all_fields = [fld.name for fld in arcpy.ListFields(input_shp)]
SR = arcpy.Describe(input_shp).spatialReference
sort_fields = ['X','Y']
order_field = 'Sort_id'
output_shp = r'c:\!Scripts\Shapefiles\SortedPnts.
arr = arcpy.da.FeatureClassToNumPyArray(input_shp, "*", spatial_reference=SR)
arr_sort = np.sort(arr, order=sort_fields)
arr_sort['Sort_id'] = np.arange(arr_sort.size)
arcpy.da.NumPyArrayToFeatureClass(arr_sort, output_shp, ['Shape'], SR)
print('\nInput file: {}\nField list: {}'.format(input_shp,all_fields))
print('Sort by: {}, ranks to: {}'.format(sort_fields,orderfield))
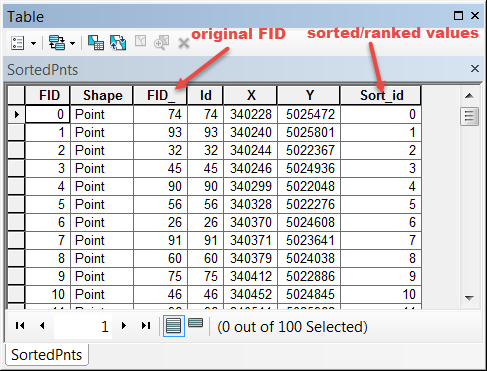
result
Input file: c:\!Scripts\Shapefiles\RandomPnts.shp
Field list: [u'FID', u'Shape', u'Id', u'X', u'Y', u'Sort_id']
Sort by: ['X', 'Y'], ranks to: Sort_id
Give it a try with your own files.