- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Blog
- :
- Multiple Field Key to Single Field Key Tool - Rela...
Multiple Field Key to Single Field Key Tool - Relate Two Layers Based on More than One Field
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
I have created a Python toolbox tool that converts the set of unique key values found in multiple fields that relate two layers/tables into a set of related sequential numbers in a CASE_ID field populated in both layers/tables. This allows a user to create a standard join or relate between the two layers/tables on the CASE_ID field that is equivalent to creating a multi-field join or relate.
This tool was inspired by the ArcInfo Workstation's FREQUENCY command which could optionally add a numeric case field to the source and output that would maintain a single field relationship when the frequency was based on more than one case field. That capability was lost in the Desktop Frequency tool. However, the tool I have created is actually more flexible than what Workstation provided, since it can be applied to any pair of layers/tables, even when the Frequency tool had nothing to do with how they were created or related.
The two zipped python toolboxes attached are designed for ArcGIS 10.3 (Field Match Tools.pyt.zip) and ArcGIS 10.2 (Field Match Tools v10.2.pyt.zip) . The toolboxes should be placed in the "%APPDATA%\ESRI\Desktop10.[3]\ArcToolbox\My Toolboxes" folder to show up in your My Toolbox under ArcCatalog (modify the items in brackets to fit your Desktop version).
I use python lists and itertools to get my sorted unique list of multiple field key values and to generate the sequential numbers associated with each key, but I convert the list into a dictionary prior to running the updateCursor so that I gain the speed or dictionary random access matching when I am writing the Case ID number values back to the data sources. Dictionary key matching is much faster than trying to locate matching items in a list. Here is the interface:
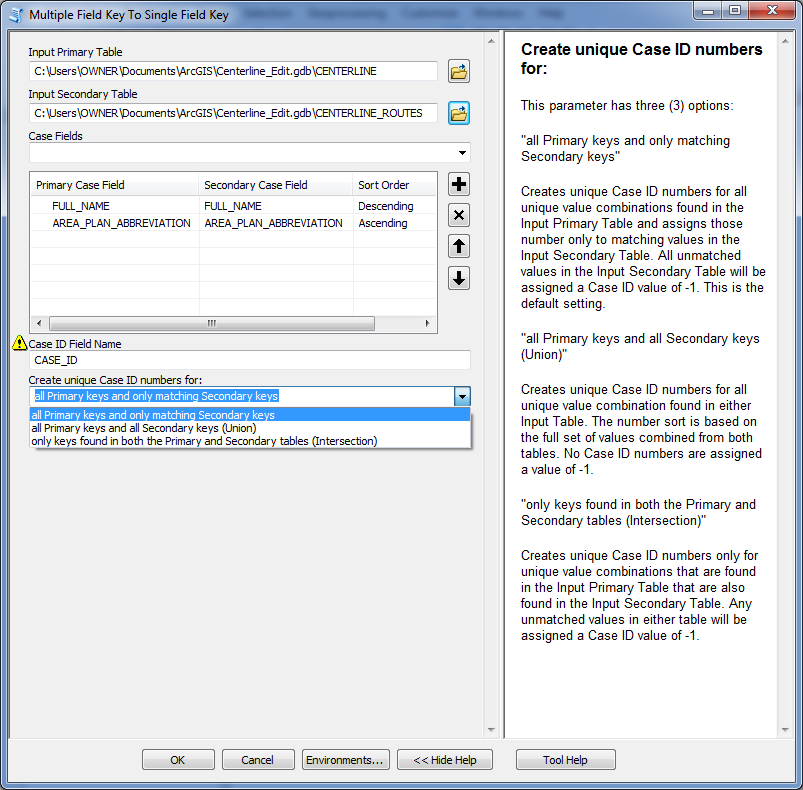
The validation works to make sure that the two input data sources are not the same and that the fields used in the case field list are actually in both sources. The user can choose as many fields as they want to make up their unique multiple field case value keys. The field names do not have to be the same in both data sources. The position of the fields in the list will control the sort priority of the Case Fields (highest priority = top field) and the Sort Order column controls whether the values in each field are sorted in Ascending or Descending order. The sort order of the Case field values controls the Case ID number sequencing. The arrangement of the fields can be different from the field arrangement actually used in the sources.
There are three options for creating sequential numbers in the CASE_ID field output. The first operates like a standard Join, where all unique key values in the Primary table are numbered, but only matching key values in the Secondary table are numbered. All unmatched values in the Secondary table are given a CASE_ID of -1. The second option is an union, where the sequential numbers are based on the complete set of key values in the combination of the Primary and Secondary layers/tables. The third option is an intersection, where only key values found in both layers/tables receive positive sequential numbers. All unmatched values of either table not found in the other table received a CASE_ID of -1.
The 10.3 version tool works the best and has the best features, However, I have provided a 10.2 version, but in order for the tool to work under the limitations of 10.2, the tool has fewer capabilities and a somewhat less intuitive interface. The 10.2 version of the tool does not support controlling the sort order of the fields, so their sequential number values are always based on the use of an ascending order for the field values. To match the fields in the two layers/tables you must click on fields in two lists, but those fields only appear in the separate field string text box when you click somewhere outside of the field lists. The tool sidebar help provides more detail on how to use it.
Here is my code for the 10.3 version of the tool:
import arcpy
class Toolbox(object):
def __init__(self):
"""Define the toolbox (the name of the toolbox is the name of the
.pyt file)."""
self.label = "Field Match Tools"
self.alias = "FieldMatchTools"
# List of tool classes associated with this toolbox
self.tools = [MultiToSingleFieldKey, InsertSelectedFeaturesOrRows]
class MultiToSingleFieldKey(object):
def __init__(self):
"""Define the tool (tool name is the name of the class)."""
self.label = "Multiple Field Key To Single Field Key"
self.description = ""
self.canRunInBackground = False
def getParameterInfo(self):
"""Define parameter definitions"""
# First parameter
param0 = arcpy.Parameter(
displayName="Input Primary Table",
name="in_prim_table",
datatype="DETable",
parameterType="Required",
direction="Input")
# Second parameter
param1 = arcpy.Parameter(
displayName="Input Secondary Table",
name="in_sec_table",
datatype="DETable",
parameterType="Required",
direction="Input")
# Third parameter
param2 = arcpy.Parameter(
displayName="Case Fields",
name="case_fields",
datatype="GPValueTable",
parameterType="Required",
direction="Input")
param2.columns = [['GPString', 'Primary Case Field'], ['GPString', 'Secondary Case Field'], ['GPString', 'Sort Order']]
param2.filters[0].type="ValueList"
param2.filters[0].list = ["X"]
param2.filters[1].type="ValueList"
param2.filters[1].list=["x"]
param2.filters[2].type="ValueList"
param2.filters[2].list=["Ascending", "Descending"]
param2.parameterDependencies = [param0.name]
# Fourth parameter
param3 = arcpy.Parameter(
displayName="Case ID Field Name",
name="in_Case_ID_field",
datatype="GPString",
parameterType="Required",
direction="Input")
param3.value = "CASE_ID"
# Fifth parameter
param4 = arcpy.Parameter(
displayName="The created unique Case ID numbers form this Primary/Secondary relationship:",
name="case_key_combo_type",
datatype="GPString",
parameterType="Required",
direction="Input")
param4.filter.type = "valueList"
param4.filter.list = ["Left Join","Full Join","Inner Join"]
param4.value = "Left Join"
newField = arcpy.Field()
newField.name = param3.value
newField.type = "LONG"
newField.precision = 10
newField.aliasName = param3.value
newField.isNullable = "NULLABLE"
# Sixth parameter
param5 = arcpy.Parameter(
displayName="Output Primary Table",
name="out_prim_table",
datatype="DETable",
parameterType="Derived",
direction="Output")
param5.parameterDependencies = [param0.name]
param5.schema.clone = True
param5.schema.additionalFields = [newField]
# Seventh parameter
param6 = arcpy.Parameter(
displayName="Output Secondary Table",
name="out_sec_table",
datatype="DETable",
parameterType="Derived",
direction="Output")
param6.parameterDependencies = [param1.name]
param6.schema.clone = True
param6.schema.additionalFields = [newField]
# Eighth parameter
param7 = arcpy.Parameter(
displayName="String comparisons are Case:",
name="case_sensitive_combo_type",
datatype="GPString",
parameterType="Required",
direction="Input")
param7.filter.type = "valueList"
param7.filter.list = ["Insensitive","Sensitive"]
param7.value = "Insensitive"
# Ninth parameter
param8 = arcpy.Parameter(
displayName="String ends trimmed of whitespace:",
name="whitespace_combo_type",
datatype="GPString",
parameterType="Required",
direction="Input")
param8.filter.type = "valueList"
param8.filter.list = ["Both", "Left", "Right", "None"]
param8.value = "Both"
params = [param0, param1, param2, param3, param4, param5, param6, param7, param8]
return params
def isLicensed(self):
"""Set whether tool is licensed to execute."""
return True
def updateParameters(self, parameters):
"""Modify the values and properties of parameters before internal
validation is performed. This method is called whenever a parameter
has been changed."""
if parameters[0].value:
# Return primary table
tbl = parameters[0].value
desc = arcpy.Describe(tbl)
fields = desc.fields
l=[]
for f in fields:
if f.type in ["String", "Text", "Short", "Long", "Float", "Single", "Double", "Integer","OID", "GUID"]:
l.append(f.name)
parameters[2].filters[0].list = l
if parameters[1].value:
# Return secondary table
tbl = parameters[1].value
desc = arcpy.Describe(tbl)
fields = desc.fields
l=[]
for f in fields:
if f.type in ["String", "Text", "Short", "Long", "Float", "Single", "Double", "Integer","OID", "GUID"]:
l.append(f.name)
parameters[2].filters[1].list = l
if parameters[2].value != None:
mylist = parameters[2].value
for i, e in list(enumerate(mylist)):
if mylist[i][2] != "Descending":
mylist[i][2] = "Ascending"
parameters[2].value = mylist
return
def updateMessages(self, parameters):
"""Modify the messages created by internal validation for each tool
parameter. This method is called after internal validation."""
if parameters[3].value and parameters[0].value and parameters[1].value:
desc = arcpy.Describe(parameters[0].value)
fields = desc.fields
in_primary = False
is_primary_error = False
is_primary_uneditable = False
for f in fields:
if parameters[3].value.upper() == f.name.upper():
in_primary = True
if f.type != "Integer":
is_primary_error = True
elif not f.editable:
is_primary_uneditable = False
desc2 = arcpy.Describe(parameters[1].value)
fields2 = desc2.fields
in_secondary = False
is_secondary_error = False
is_secondary_uneditable = False
for f2 in fields2:
if parameters[3].value.upper() == f2.name.upper():
in_secondary = True
if f2.type != "Integer":
is_secondary_error = True
elif not f2.editable:
is_secondary_uneditable = False
newField = arcpy.Field()
newField.name = parameters[3].value
newField.type = "LONG"
newField.precision = 10
newField.aliasName = parameters[3].value
newField.isNullable = "NULLABLE"
fields1 = []
fields2 = []
order = []
for item in parameters[2].value:
fields1.append(item[0].upper())
fields2.append(item[1].upper())
order.append(item[2])
if str(parameters[0].value).upper() == str(parameters[1].value).upper():
parameters[1].setErrorMessage("The Input Secondary Table {0} cannot be the same as the Input Primary Table {1} ".format(parameters[1].value, parameters[0].value))
else:
parameters[1].clearMessage()
if in_primary and in_secondary:
if is_primary_error and is_secondary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in both the Input Primary and Secondary Tables".format(parameters[3].value.upper()))
elif is_primary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in the Input Primary Table".format(parameters[3].value.upper()))
elif is_secondary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in the Input Secondary Table".format(parameters[3].value.upper()))
elif parameters[3].value.upper() in fields1 and parameters[3].value.upper() in fields2:
parameters[3].setErrorMessage("{0} is used as a Case Field for both the Input Primary and Secondary Tables".format(parameters[3].value.upper()))
elif parameters[3].value.upper() in fields1:
parameters[3].setErrorMessage("{0} is used as a Case Field for the Input Primary Table".format(parameters[3].value.upper()))
elif parameters[3].value.upper() in fields2:
parameters[3].setErrorMessage("{0} is used as a Case Field for the Input Secondary Table".format(parameters[3].value.upper()))
elif is_primary_uneditable and is_secondary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in both the Input Primary and Secondary Tables".format(parameters[3].value.upper()))
elif is_primary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in the Input Primary Table".format(parameters[3].value.upper()))
elif is_secondary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in the Input Secondary Table".format(parameters[3].value.upper()))
else:
parameters[3].setWarningMessage("{0} will be overwritten in both the Input Primary and Secondary Tables".format(parameters[3].value.upper()))
elif in_primary:
parameters[6].schema.additionalFields = [newField]
if is_primary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in the Input Primary Table".format(parameters[3].value.upper()))
elif is_primary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in the Input Primary Table".format(parameters[3].value.upper()))
else:
parameters[3].setWarningMessage("{0} will be overwritten in the Input Primary Table".format(parameters[3].value.upper()))
elif in_secondary:
parameters[5].schema.additionalFields = [newField]
if is_secondary_error:
parameters[3].setErrorMessage("{0} exists and is not a Long Integer field in the Input Secondary Table".format(parameters[3].value.upper()))
elif is_secondary_uneditable:
parameters[3].setErrorMessage("{0} exists and is not editable in the Input Secondary Table".format(parameters[3].value.upper()))
else:
parameters[3].setWarningMessage("{0} will be overwritten in the Input Secondary Table".format(parameters[3].value.upper()))
else:
parameters[5].schema.additionalFields = [newField]
parameters[6].schema.additionalFields = [newField]
parameters[3].clearMessage()
return
def stringCaseTrim(self, parameters, value):
tempstr = None
if parameters[7].value.upper() == 'Sensitive'.upper():
tempstr = value
else:
tempstr = value.upper()
if parameters[8].value.upper() == 'None'.upper():
return tempstr
if parameters[8].value.upper() == 'Left'.upper():
return tempstr.lstrip()
if parameters[8].value.upper() == 'Right'.upper():
return tempstr.rstrip()
else:
return tempstr.strip()
def execute(self, parameters, messages):
"""The source code of the tool."""
try:
desc = arcpy.Describe(parameters[0].value)
fields = desc.fields
in_primary = False
for f in fields:
if parameters[3].value.upper() == f.name.upper():
in_primary = True
if not in_primary:
arcpy.AddField_management(parameters[0].value, parameters[3].value.upper(), "Long", 10)
arcpy.AddMessage("Added a Case ID field to the Input Primary Table")
desc2 = arcpy.Describe(parameters[1].value)
fields2 = desc2.fields
in_secondary = False
for f2 in fields2:
if parameters[3].value.upper() == f2.name.upper():
in_secondary = True
if not in_secondary:
arcpy.AddField_management(parameters[1].value, parameters[3].value.upper(), "Long", 10)
arcpy.AddMessage("Added a Case ID field to the Input Secondary Table")
tbl1 = parameters[0].value
tbl2 = parameters[1].value
fields1 = []
fields2 = []
order = []
for item in parameters[2].value:
fields1.append(item[0])
fields2.append(item[1])
order.append(item[2])
arcpy.AddMessage("Primary Case Fields are {0}".format(str(fields1)))
arcpy.AddMessage("Secondary Case Fields are {0}".format(str(fields2)))
arcpy.AddMessage("Sort Orders are {0}".format(str(order)))
import itertools
k = []
arcpy.AddMessage("Strings Comparisons Are {0}".format(parameters[7].value))
k = list(tuple([self.stringCaseTrim(parameters, value) if str(type(value)) in ("<class 'str'>", "<type 'unicode'>") else value for value in r]) for r in arcpy.da.SearchCursor(tbl1, fields1))
arcpy.AddMessage("Case Values have been read from the Input Primary Table")
if parameters[4].value == "Full Join":
j = []
j = list(tuple([self.stringCaseTrim(parameters, value) if str(type(value)) in ("<class 'str'>", "<type 'unicode'>") else value for value in r]) for r in arcpy.da.SearchCursor(tbl2, fields2))
k = k + j
j = None
arcpy.AddMessage("Case Values have been appended from the Input Secondary Table")
from operator import itemgetter
for i, e in reversed(list(enumerate(order))):
if order[i] == "Descending":
k.sort(key=itemgetter(i), reverse=True)
else:
k.sort(key=itemgetter(i))
k = list(k for k,_ in itertools.groupby(k))
if parameters[4].value == "Inner Join":
j = list(tuple([self.stringCaseTrim(parameters, value) if str(type(value)) in ("<class 'str'>", "<type 'unicode'>") else value for value in r]) for r in arcpy.da.SearchCursor(tbl2, fields2))
arcpy.AddMessage("Case Values have been read from the Input Secondary Table")
l = []
for item in k:
if tuple(item) in j:
l.append(item)
j = None
k = l
l = None
arcpy.AddMessage("Case Values have been matched to the Input Secondary Table")
arcpy.AddMessage("A list of sorted and unique Case Values has been created")
dict = {}
fields1.append(parameters[3].value)
fields2.append(parameters[3].value)
for i in xrange(len(k)):
dict[tuple(k[i])] = i + 1
k = None
arcpy.AddMessage("A dictionary of unique Case Value keys with Case ID number values has been created")
with arcpy.da.UpdateCursor(tbl1, fields1) as cursor:
for row in cursor:
caseinsensitive = tuple([self.stringCaseTrim(parameters, value) if str(type(value)) in ("<class 'str'>", "<type 'unicode'>") else value for value in row[0:len(fields2)-1]])
if caseinsensitive in dict:
row[len(fields1)-1] = dict[caseinsensitive]
else:
row[len(fields2)-1] = -1
cursor.updateRow(row)
del cursor
arcpy.AddMessage("{0} values have been updated for Input Primary Table".format(parameters[3].value))
with arcpy.da.UpdateCursor(tbl2, fields2) as cursor2:
for row2 in cursor2:
caseinsensitive = tuple([self.stringCaseTrim(parameters, value) if str(type(value)) in ("<class 'str'>", "<type 'unicode'>") else value for value in row2[0:len(fields2)-1]])
if caseinsensitive in dict:
row2[len(fields2)-1] = dict[caseinsensitive]
else:
row2[len(fields2)-1] = -1
cursor2.updateRow(row2)
del cursor2
arcpy.AddMessage("{0} values have been updated for Input Secondary Table".format(parameters[3].value))
except Exception as e:
messages.addErrorMessage(e.message)
return
class InsertSelectedFeaturesOrRows(object):
def __init__(self):
"""Define the tool (tool name is the name of the class)."""
self.label = "Insert Selected Features or Rows"
self.description = ""
self.canRunInBackground = False
def getParameterInfo(self):
"""Define parameter definitions"""
# First parameter
param0 = arcpy.Parameter(
displayName="Source Layer or Table View",
name="source_layer_or_table_view",
datatype="GPTableView",
parameterType="Required",
direction="Input")
# Second parameter
param1 = arcpy.Parameter(
displayName="Target Layer or Table View",
name="target_layer_or_table_view",
datatype="GPTableView",
parameterType="Required",
direction="Input")
# Third parameter
param2 = arcpy.Parameter(
displayName="Number of Copies to Insert",
name="number_of_copies_to_insert",
datatype="GPLong",
parameterType="Required",
direction="Input")
param2.value = 1
# Fourth parameter
param3 = arcpy.Parameter(
displayName="Derived Layer or Table View",
name="derived_table",
datatype="GPTableView",
parameterType="Derived",
direction="Output")
param3.parameterDependencies = [param1.name]
param3.schema.clone = True
params = [param0, param1, param2, param3]
return params
def isLicensed(self):
"""Set whether tool is licensed to execute."""
return True
def updateParameters(self, parameters):
"""Modify the values and properties of parameters before internal
validation is performed. This method is called whenever a parameter
has been changed."""
return
def updateMessages(self, parameters):
"""Modify the messages created by internal validation for each tool
parameter. This method is called after internal validation."""
if parameters[1].value:
insertFC = parameters[1].value
strInsertFC = str(insertFC)
if parameters[0].value and '<geoprocessing Layer object' in strInsertFC:
FC = parameters[0].value
strFC = str(FC)
if not '<geoprocessing Layer object' in strFC:
print("Input FC must be a layer if output is a layer")
parameters[0].setErrorMessage("Input must be a feature layer if the Output is a feature layer!")
else:
dscFCLyr = arcpy.Describe(FC)
dscinsertFCLyr = arcpy.Describe(insertFC)
# add the SHAPE@ field if the shapetypes match
if dscFCLyr.featureclass.shapetype != dscinsertFCLyr.featureclass.shapetype:
print("Input and Output have different geometry types! Geometry must match!")
parameters[0].setErrorMessage("Input and Output do not have the same geometry")
if dscFCLyr.featureclass.spatialReference.name != dscinsertFCLyr.featureclass.spatialReference.name:
print("Input and Output have different Spatial References! Spatial References must match!")
parameters[0].setErrorMessage("Input and Output do not have the same Spatial References! Spatial References must match!")
if parameters[2].value <= 0:
parameters[2].setErrorMessage("The Number of Row Copies must be 1 or greater")
return
def execute(self, parameters, messages):
"""The source code of the tool."""
try:
mxd = arcpy.mapping.MapDocument(r"CURRENT")
df = arcpy.mapping.ListDataFrames(mxd)[0]
FC = parameters[0].value
insertFC = parameters[1].value
strFC = str(FC)
strInsertFC = str(insertFC)
FCLyr = None
insertFCLyr = None
for lyr in arcpy.mapping.ListLayers(mxd, "", df):
# Try to match to Layer
if '<geoprocessing Layer object' in strFC:
if lyr.name.upper() == FC.name.upper():
FCLyr = lyr
if '<geoprocessing Layer object' in strInsertFC:
if lyr.name.upper() == insertFC.name.upper():
insertFCLyr = lyr
if FCLyr == None or insertFCLyr == None:
# Try to match to table if no layer found
if FCLyr == None:
tables = arcpy.mapping.ListTableViews(mxd, "", df)
for table in tables:
if table.name.upper() == strFC.upper():
FCLyr = table
break
if insertFCLyr == None:
tables = arcpy.mapping.ListTableViews(mxd, "", df)
for table in tables:
if table.name.upper() == strInsertFC.upper():
insertFCLyr = table
break
# If both layers/tables are found then process fields and insert cursor
if FCLyr != None and insertFCLyr != None:
dsc = arcpy.Describe(FCLyr)
selection_set = dsc.FIDSet
# only process layers/tables if there is a selection in the FCLyr
if len(selection_set) > 0:
print("{} has {} {}{} selected".format(FCLyr.name, len(selection_set.split(';')), 'feature' if '<geoprocessing Layer object' in strInsertFC else 'table row', '' if len(selection_set.split(';')) == 1 else 's'))
arcpy.AddMessage("{} has {} {}{} selected".format(FCLyr.name, len(selection_set.split(';')), 'feature' if '<geoprocessing Layer object' in strInsertFC else 'table row', '' if len(selection_set.split(';')) == 1 else 's'))
FCfields = arcpy.ListFields(FCLyr)
insertFCfields = arcpy.ListFields(insertFCLyr)
# Create a field list of fields you want to manipulate and not just copy
# All of these fields must be in the insertFC
manualFields = []
matchedFields = []
for manualField in manualFields:
matchedFields.append(manualField.upper())
for FCfield in FCfields:
for insertFCfield in insertFCfields:
if (FCfield.name.upper() == insertFCfield.name.upper() and
FCfield.type == insertFCfield.type and
FCfield.type <> 'Geometry' and
insertFCfield.editable == True and
not (FCfield.name.upper() in matchedFields)):
matchedFields.append(FCfield.name)
break
elif (FCfield.type == 'Geometry' and
FCfield.type == insertFCfield.type):
matchedFields.append("SHAPE@")
break
elif insertFCfield.type == "OID":
oid_name = insertFCfield.name
if len(matchedFields) > 0:
# Print the matched fields list
print("The matched fields are: {}".format(matchedFields))
arcpy.AddMessage("The matched fields are: {}".format(matchedFields))
copies = parameters[2].value
print("Making {} {} of each {}".format(copies, 'copy' if copies == 1 else 'copies', 'feature' if '<geoprocessing Layer object' in strInsertFC else 'table row'))
arcpy.AddMessage("Making {} {} of each {}".format(copies, 'copy' if copies == 1 else 'copies', 'feature' if '<geoprocessing Layer object' in strInsertFC else 'table row'))
oid_list = []
# arcpy.AddMessage(oid_name)
dscInsert = arcpy.Describe(insertFCLyr)
if '<geoprocessing Layer object' in strInsertFC:
oid_name = arcpy.AddFieldDelimiters(dscInsert.dataElement, oid_name)
else:
oid_name = arcpy.AddFieldDelimiters(dscInsert, oid_name)
rowInserter = arcpy.da.InsertCursor(insertFCLyr, matchedFields)
print("The output workspace is {}".format(insertFCLyr.workspacePath))
arcpy.AddMessage("The output workspace is {}".format(insertFCLyr.workspacePath))
if '<geoprocessing Layer object' in strInsertFC:
versioned = dscInsert.featureclass.isVersioned
else:
versioned = dscInsert.table.isVersioned
if versioned:
print("The output workspace is versioned")
arcpy.AddMessage("The output workspace is versioned")
with arcpy.da.Editor(insertFCLyr.workspacePath) as edit:
with arcpy.da.SearchCursor(FCLyr, matchedFields) as rows:
for row in rows:
for i in range(copies):
oid_list.append(rowInserter.insertRow(row))
else:
print("The output workspace is not versioned")
arcpy.AddMessage("The output workspace is not versioned")
with arcpy.da.SearchCursor(FCLyr, matchedFields) as rows:
for row in rows:
for i in range(copies):
oid_list.append(rowInserter.insertRow(row))
del row
del rows
del rowInserter
if len(oid_list) == 1:
whereclause = oid_name + ' = ' + str(oid_list[0])
elif len(oid_list) > 1:
whereclause = oid_name + ' IN (' + ','.join(map(str, oid_list)) + ')'
if len(oid_list) > 0:
# arcpy.AddMessage(whereclause)
# Switch feature selection
arcpy.SelectLayerByAttribute_management(FCLyr, "CLEAR_SELECTION", "")
arcpy.SelectLayerByAttribute_management(insertFCLyr, "NEW_SELECTION", whereclause)
print("Successfully inserted {} {}{} into {}".format(len(oid_list), 'feature' if '<geoprocessing Layer object' in strInsertFC else 'table row', '' if len(selection_set.split(';')) == 1 else 's', insertFCLyr.name))
arcpy.AddMessage("Successfully inserted {} {}{} into {}".format(len(oid_list), 'feature' if '<geoprocessing Layer object' in strInsertFC else 'table row', '' if len(selection_set.split(';')) == 1 else 's', insertFCLyr.name))
else:
print("Input and Output have no matching fields")
arcpy.AddMessage("Input and Output have no matching fields")
else:
print("There are no features selected")
arcpy.AddMessage("There are no features selected")
# report if a layer/table cannot be found
if FCLyr == None:
print("There is no layer or table named '{}' in the map".format(FC))
arcpy.AddMessage("There is no layer or table named '" + FC + "'")
if insertFCLyr == None:
print("There is no layer or table named '{}' in the map".format(insertFC))
arcpy.AddMessage("There is no layer or table named '{}' in the map".format(insertFC))
arcpy.RefreshActiveView()
return
except Exception as e:
# If an error occurred, print line number and error message
import traceback, sys
tb = sys.exc_info()[2]
print("Line %i" % tb.tb_lineno)
arcpy.AddMessage("Line %i" % tb.tb_lineno)
print(e.message)
arcpy.AddMessage(e.message)You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.