- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Data Management Questions
- :
- Script for creating line network intersection poin...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Script for creating line network intersection points
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have created a script for creating line network intersection points. It can process over 120,000 lines to create over 96,000 intersection points in approximately 2 minutes and 15 seconds.
It creates a single unique point feature at any given location no matter how many line From or To ends meet at the point. It uses the provided line name/ID field's values to define a sorted unique list of names/IDs that connect at each point. The point also includes fields for its X and Y coordinates, a concatenation of the X and Y coordinates that uniquely identifies the point location and that can be used as a join field, a field listing a total line count that meets at the intersection point and a list of counts of each name ordered to match the name/ID list order.
Hopefully the code comments are clear and will show you where you can customize the code to fit your preferences. By default the name/ID values that are blank strings or Null value are excluded from the name list and counts, which can make the point where the unnamed line intersects a named line appear to be a pseudo-node. The comment explain how you can change that behavior if you like.
The output points can be used to identify true intersections where two or more different name/ID values meet at a point (any points where the names list field has a closing and opening separator in it or any separator in it if a single character separator is used). It also includes fields that make it possible to identify points where a single line end has no other line connected at that point, which are located at a network boundary, cul-de-sac, stub, inlet, outlet, or dangle topology error (any point where the total lines count field is 1). Finally, it includes fields that make it possible to identify attribute pseudo-nodes where only a single name/ID value occurs where two or more lines join together (any point which has a total lines count greater than 1 and the name list field has no closing and opening separator in it or no separator at all if a single character separator is used). These different classes of points can be selected and exported to create separate point feature classes if you like.
Here is the code:
# ---------------------------------------------------------------------------
# Created on: 2014-09-25
# Author: Richard Fairhurst
# Description: This code is designed to create intersection points, end
# points and/or pseudo-node points based on a name/ID attribute that are
# derived from an input line network. Only line end points are used
# to form intersections, unmatched line ends, or pseudo-nodes.
# High precision topology is typically required to ensure that line ends snap
# together with sufficient accuracy to be connsidered part of the same
# intersection point.
# ---------------------------------------------------------------------------
import arcpy
import os
from arcpy import env
from time import strftime
print "Start script: " + strftime("%Y-%m-%d %H:%M:%S")
# Customize the workspace path to fit your data
env.workspace = r"C:\Users\Owner\Documents\ArcGIS\Centerline_Edit.gdb"
env.overwriteOutput = True
# Customize the name of the field that contains networks line names/IDs
name_field = "STNAME"
# Customize the output field names for the line names list, coordinates,
# concatenated coordinates, total line count, and names count list
names_list_field = "STNAMES"
X_field = "X_COORD"
Y_field = "Y_COORD"
XY_field = "LINK_X_Y"
total_count_field = "WAYS_COUNT"
names_count_list_field = "STNAME_WAYS"
# Customize the separators for concatenated coordinate keys and lists
opening_separator = "{"
closing_separator = "}"
# Customize the input to your feature class, shapefile or layer
inputdata = r"CENTERLINE"
inputfilefull = env.workspace + "\\" + inputdata
# Customize the output feature class or layer to fit your network
outputfile = r"CL_INTERSECTION_POINTS"
outputfilefull = env.workspace + "\\" + outputfile
# Makes a dictionary of unique string coordinate keys from both line ends
# with values in a list holding a dictionary of intersecting names with
# their counts, coordinates, and a total line count
valueDict = {}
with arcpy.da.SearchCursor(inputdata, [name_field, "SHAPE@"]) as searchRows:
for searchRow in searchRows:
name = searchRow[0]
geometry = searchRow[1]
From_X = geometry.firstPoint.X
From_Y = geometry.firstPoint.Y
To_X = geometry.lastPoint.X
To_Y = geometry.lastPoint.Y
# Customize string coordinate keys for the line From and To ends
# For Latitude and Longitude change the formating below to
# "%(OSep1)s%(FY)012.8f%(CSep1)s%(OSep2)s%(FX)012.8f%(CSep2)s" % {'OSep1': opening_separator, 'FY': From_Y, 'CSep1': closing_separator, 'OSep2': opening_separator, 'FX': From_X, 'CSep2': closing_separator}
keyValueFrom = "%(OSep1)s%(FX)012.4f%(CSep1)s%(OSep2)s%(FY)012.4f%(CSep2)s" % {'OSep1': opening_separator, 'FX': From_X, 'CSep1': closing_separator, 'OSep2': opening_separator, 'FY': From_Y, 'CSep2': closing_separator}
keyValueTo = "%(OSep1)s%(TX)012.4f%(CSep1)s%(OSep2)s%(TY)012.4f%(CSep2)s" % {'OSep1': opening_separator, 'TX': To_X, 'CSep1': closing_separator, 'OSep2': opening_separator, 'TY': To_Y, 'CSep2': closing_separator}
# Intersection names normally exclude unnamed and Null name lines
# Optional: If you want unnamed lines to create intersection points
# comment out the next line and dedent the if clause regions below
if name <> " " and name != None:
# add new From coordinate into dictionary
if not keyValueFrom in valueDict:
valueDict[keyValueFrom] = [{}, From_X, From_Y, 1]
valueDict[keyValueFrom][0][name] = 1
# add new name into names dictionary of known From coordinate
elif not name in valueDict[keyValueFrom][0].keys():
valueDict[keyValueFrom][0][name] = 1
valueDict[keyValueFrom][3] += 1
# increment counts when the From coordinate and name are known
else:
valueDict[keyValueFrom][0][name] += 1
valueDict[keyValueFrom][3] += 1
# add new To coordinates into dictionary
if not keyValueTo in valueDict:
valueDict[keyValueTo] = [{}, To_X, To_Y, 1]
valueDict[keyValueTo][0][name] = 1
# add new name into names dictionary of known To coordinate
elif not name in valueDict[keyValueTo][0].keys():
valueDict[keyValueTo][0][name] = 1
valueDict[keyValueTo][3] += 1
# increment counts when the To coordinate and name are known
else:
valueDict[keyValueTo][0][name] += 1
valueDict[keyValueTo][3] += 1
print "Finished dictionary creation: " + strftime("%Y-%m-%d %H:%M:%S")
# Determine if the outputfilefull exists already
if arcpy.Exists(outputfilefull):
# Process: Delete outputfilefull...
arcpy.Delete_management(outputfilefull, "FeatureClass")
# Process: Create Point Feature Class and use the input spatial reference...
arcpy.CreateFeatureclass_management(env.workspace, outputfile, "POINT", "", "DISABLED", "DISABLED", inputfilefull, "", "0", "0", "0")
# Process: Add names_list_field Field (customize the field length if you need to)...
arcpy.AddField_management(outputfilefull, names_list_field, "TEXT", "", "", "150", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add X_field Field...
arcpy.AddField_management(outputfilefull, X_field, "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Y_field Field...
arcpy.AddField_management(outputfilefull, Y_field, "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add XY_field Field (customize the field length if you need to)...
arcpy.AddField_management(outputfilefull, XY_field, "TEXT", "", "", "28", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add total_count_field Field...
arcpy.AddField_management(outputfilefull, total_count_field, "LONG", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add names_count_list_field Field (customize the field length if you need to)...
arcpy.AddField_management(outputfilefull, names_count_list_field, "TEXT", "", "", "20", "", "NULLABLE", "NON_REQUIRED", "")
print "Finished feature class creation: " + strftime("%Y-%m-%d %H:%M:%S")
# Create an insert cursor for a table specifying the fields that will
# have values provided
fields = [names_list_field, X_field, Y_field, XY_field, total_count_field, names_count_list_field, 'SHAPE@XY']
insertcursor = arcpy.da.InsertCursor(outputfilefull, fields)
# sort the string coordinate keys and process their values
for keyValue in sorted(valueDict.keys()):
# create a list of names and their counts with separator characters
# reset variables to hold new lists of names and their counts
names = ""
counts = ""
# sort the names dictionary and create the names and counts lists
for name in sorted(valueDict[keyValue][0].keys()):
if name == "":
# Optional: Change separator configuration
names = opening_separator + name + closing_separator
counts = opening_separator + str(valueDict[keyValue][0][name]) + closing_separator
else:
# Optional: Change separator configuration
names = names + opening_separator + name + closing_separator
counts = counts + opening_separator + str(valueDict[keyValue][0][name]) + closing_separator
row = (names, valueDict[keyValue][1], valueDict[keyValue][2], keyValue, valueDict[keyValue][3], counts, (valueDict[keyValue][1], valueDict[keyValue][2]))
insertcursor.insertRow(row)
# create output feature classes/shapefiles
# two names separated by "}{" are a real intersection
# if closing_separator + opening_separator in names:
# write to text file
# f.write('"' + names + '",' + str(valueDict[keyValue][1]) + ',' + str(valueDict[keyValue][2]) + ',"' + keyValue + '",' + str(valueDict[keyValue][3]) + ',"' + counts + '"\n' )
# one name with a total line count of 1 is an unmatched line end, which
# may be a stub, a cul-de-sac, or a topology error for a road network
# one name with a total line count > 1 is a pseudo node for the name
print "Finished inserting rows: " + strftime("%Y-%m-%d %H:%M:%S")
Here is a picture of what the field data looks like for the code as written:
| OBJECTID * | Shape * | STNAMES | X_COORD | Y_COORD | LINK_X_Y | WAYS_COUNT | STNAME_WAYS |
| 50676 | Point | {MADRONO CT} | 6296418.904414 | 2243614.433358 | {6296418.9044}{2243614.4334} | 1 | {1} |
| 50867 | Point | {10TH ST} | 6297064.90509 | 2243667.729839 | {6297064.9051}{2243667.7298} | 2 | {2} |
| 50889 | Point | {10TH ST}{WOLFSKILL AVE} | 6297145.870479 | 2243668.425376 | {6297145.8705}{2243668.4254} | 2 | {1}{1} |
| 50997 | Point | {BELL AVE}{WOLFSKILL AVE} | 6297360.565588 | 2243670.268876 | {6297360.5656}{2243670.2689} | 3 | {1}{2} |
| 51160 | Point | {MAGNOLIA AVE}{WOLFSKILL AVE} | 6297781.153002 | 2243671.327601 | {6297781.1530}{2243671.3276} | 4 | {2}{2} |
| 51407 | Point | {HANSEN AVE}{WOLFSKILL AVE} | 6298405.94145 | 2243672.728517 | {6298405.9415}{2243672.7285} | 4 | {2}{2} |
| 51724 | Point | {6TH ST}{WOLFSKILL AVE} | 6299040.417543 | 2243674.151414 | {6299040.4175}{2243674.1514} | 4 | {2}{2} |
| 52871 | Point | {5TH ST}{WOLFSKILL AVE} | 6301563.821945 | 2243679.94635 | {6301563.8219}{2243679.9464} | 4 | {2}{2} |
| 53020 | Point | {MIKE LN}{WOLFSKILL AVE} | 6301904.892129 | 2243680.73211 | {6301904.8921}{2243680.7321} | 3 | {1}{2} |
| 53164 | Point | {HAVENHURST DR}{WOLFSKILL AVE} | 6302189.418463 | 2243681.387948 | {6302189.4185}{2243681.3879} | 3 | {1}{2} |
| 53355 | Point | {WOLFSKILL AVE} | 6302528.110371 | 2243682.16813 | {6302528.1104}{2243682.1681} | 2 | {2} |
| 53469 | Point | {BLUEBONNET RD}{WOLFSKILL AVE} | 6302822.667853 | 2243682.846935 | {6302822.6679}{2243682.8469} | 3 | {1}{2} |
| 53637 | Point | {POPPY RD}{WOLFSKILL AVE} | 6303293.806346 | 2243683.932563 | {6303293.8063}{2243683.9326} | 3 | {1}{2} |
| 53810 | Point | {4TH ST}{CORSO ALTO AVE}{WOLFSKILL AVE} | 6303774.846395 | 2243684.940106 | {6303774.8464}{2243684.9401} | 3 | {1}{1}{1} |
| 50553 | Point | {MADRONO CT}{YUCCA AVE} | 6295970.886609 | 2243832.745913 | {6295970.8866}{2243832.7459} | 3 | {1}{2} |
| 50586 | Point | {10TH ST}{YUCCA AVE} | 6296116.882052 | 2244123.025844 | {6296116.8821}{2244123.0258} | 4 | {2}{2} |
| 50779 | Point | {WILDFIRE CIR} | 6296733.251882 | 2244238.88388 | {6296733.2519}{2244238.8839} | 1 | {1} |
| 50638 | Point | {WILDFIRE CIR}{YUCCA AVE} | 6296284.789853 | 2244458.484163 | {6296284.7899}{2244458.4842} | 4 | {2}{2} |
| 50332 | Point | {10TH ST}{ARMANDO DR} | 6295320.524393 | 2244504.723572 | {6295320.5244}{2244504.7236} | 3 | {2}{1} |
| 50534 | Point | {WILDFIRE CIR} | 6295917.833565 | 2244566.072531 | {6295917.8336}{2244566.0725} | 1 | {1} |
| 53872 | Point | {YUCCA AVE} | 6303868.692664 | 2244646.38405 | {6303868.6927}{2244646.3840} | 2 | {2} |
| 53854 | Point | {4TH ST}{YUCCA AVE} | 6303843.885627 | 2244649.336472 | {6303843.8856}{2244649.3365} | 4 | {2}{2} |
| 50223 | Point | {10TH ST}{LAKEVIEW AVE} | 6294916.12986 | 2244698.551596 | {6294916.1299}{2244698.5516} | 4 | {2}{2} |
| 53027 | Point | {MIKE LN} | 6301917.13784 | 2244702.955131 | {6301917.1378}{2244702.9551} | 1 | {1} |
| 50855 | Point | {DEBBIE LN} | 6297012.336626 | 2244807.570407 | {6297012.3366}{2244807.5704} | 1 | {1} |
| 50737 | Point | {DEBBIE LN}{WOLFGRAM DR}{YUCCA AVE} | 6296566.133122 | 2245018.051942 | {6296566.1331}{2245018.0519} | 4 | {1}{1}{2} |
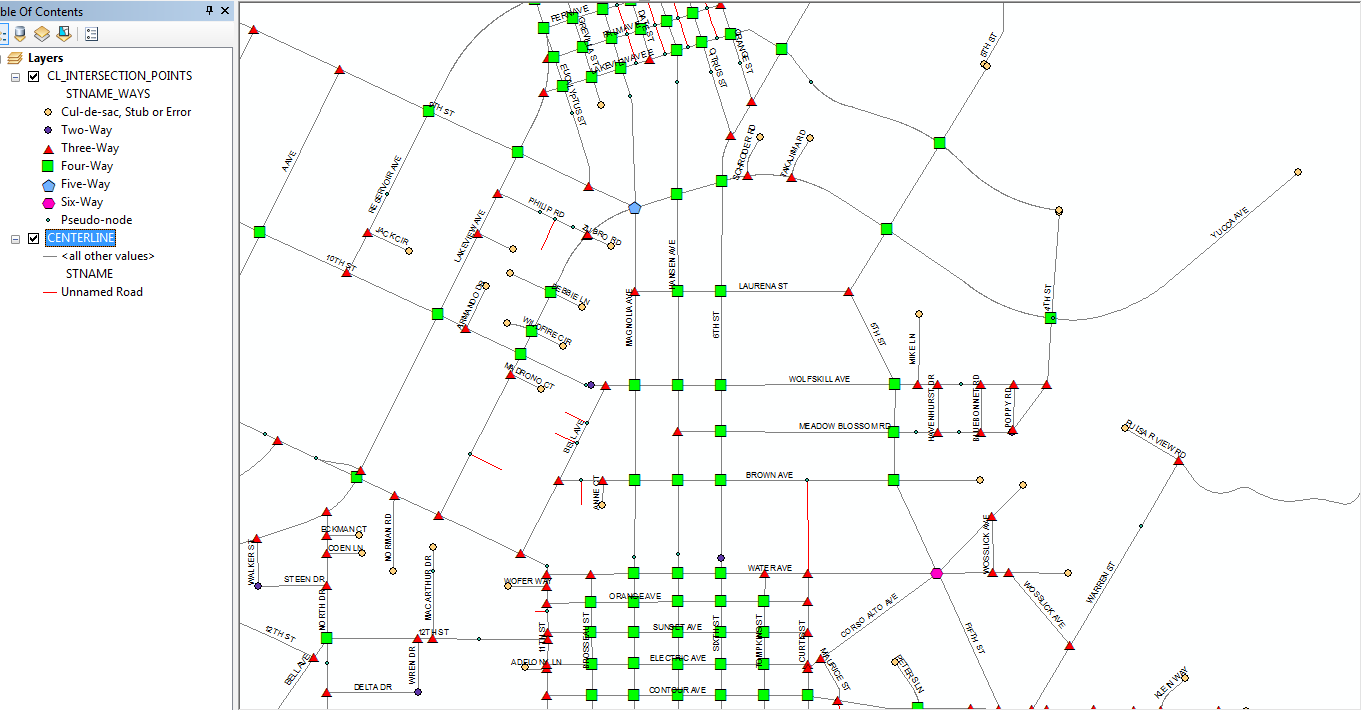
Here is a picture of one of the ways this data can displayed:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Which version of the script are you running? The one from the first post? I just created a brand new file geodatabase that matched the workspace path and name in the script, copied a polyline feature class into it named Centerline which had a field named STNAME containing all of the street names and ran the script from start to finish with no other set up and no problems.
Based on that there is no reason for you to think that a workaround is necessary if the set up is all correct, since the code is doing nothing unusual that should break in any version of ArcMap. Your workspace must be a file geodatabase where all of your inputs and outputs will be stored, since the code was only designed to work with data in that workspace type. Are you sure that the script is set up correctly for your file geodatabase workspace, feature class names and field names? Check to see if there is a CL_INTERSECTION_POINTS point feature class in your output workspace.
There could be issues if your inputs or outputs are in a feature dataset within the file geodatabase, since extra steps may have to be taken to make sure the outputs exactly match the spatial reference, coordinate domain, resolution, tolerances, etc of the feature dataset. Of course, since this is a standalone script, the script should only be run when you are sure that you don't have any active ArcMap or ArcCatalog sessions open that may point to any of the data in the output workspace, since the script needs to have exclusive lock rights to the workspace while it is running.
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »