- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Spatial Analyst
- :
- ArcGIS Spatial Analyst Questions
- :
- Transforming slope raster with relative direction ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Transforming slope raster with relative direction to produce negative/positive slope values representing increase and decrease in slope, respectively.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have two 'base' line features that are somewhat parallel to each other, which are connected by vectors (also line features) [Check attached photo - underlying raster layer is not the DEM].
I want to use the vectors connecting the two 'base' lines to extract slope values calculated from a DEM. In other words, the vectors connecting the two 'base' lines are spatial sampling units, which will be used to extract topographic information to describe the movement from one base line to the next. This is obviously problematic, since ArcGIS's slope tool only calculates slope directionality in terms of a convolution 3x3 kernel, which in turn, gives an output in degrees or percent rise....So. When I use the vectors to extract the slope values along each one (individual vectors), there are obviously no negative values, when in reality, these vectors all have some sort of mixture of negative and positive slopes ( because many of the vectors from base line 1 to base line 2, go up and then down slope, or vice-versa).
My question - What algorithms can I use to transform the slope values based on some relative starting point of each vector, so that once I extract the slope values from each vector line - it will illustrate whether that vector was going predominantly downhill (negative slope) or uphill ( positive slope)?
Thank you for your time. Any thoughts, comments, or recommendations are greatly appreciated. 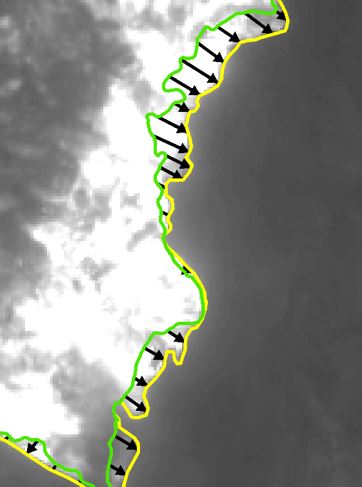
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Gavin... use the Advanced Editor after clicking on the main thread title.... Attach should show in the bottom right, so you can attach the file
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan, did the elevation profile text doc work out for you?
thanks,Gav
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
got distracted... have them now
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Gavin
a work through for one sample .
I just want to check on the logic
- take a profile which has a bunch of locations recorded in relative mode so only distance is needed (first_dist field) Z_st_end is the elevation at that point
- suck the data out of the file and form it so that you pull out the elevation profile on a per-profile basis
- from the profile calculate the incremental slope... the slope between elevation points
- next step
- determine whether the profile is dominantly increasing or decreasing by analysing the incremental slope profile
Sound about right?
Let me know and I can finish it off and set up a script that will just read a text file and do the work for you if you need to do it again. … yes it will include the 'magic' stuff so you don't need to do it manually
a6 = a_s[5] # profile number 6
art.frmt_rec(a6) # ---- don't worry about the 'magic' stuff
--n-- profile z_st_end first_dist
-----------------------------------
000 6 737.58 0.00
001 6 736.88 9.73
002 6 736.11 19.47
003 6 735.29 29.20
004 6 734.18 38.94
005 6 733.10 48.67
006 6 733.20 58.41
007 6 733.60 68.14
008 6 739.97 77.88
009 6 747.30 87.61
010 6 755.42 97.35
011 6 763.70 107.08
012 6 772.18 116.82
013 6 779.69 126.55
014 6 784.51 136.28
015 6 784.58 146.02
016 6 782.32 155.75
017 6 778.54 165.49
a6_f = a6[q].view(np.float).reshape(len(a6), 2) # ---- more magic
array([[737.58, 0. ],
[736.88, 9.73],
[736.11, 19.47],
[735.29, 29.2 ],
[734.18, 38.94],
[733.1 , 48.67],
[733.2 , 58.41],
[733.6 , 68.14],
[739.97, 77.88],
[747.3 , 87.61],
[755.42, 97.35],
[763.7 , 107.08],
[772.18, 116.82],
[779.69, 126.55],
[784.51, 136.28],
[784.58, 146.02],
[782.32, 155.75],
[778.54, 165.49]])
delta = a6_f[1:] - a6_f[:-1] # ---- produce the differences in Z and X
array([[-0.7 , 9.73],
[-0.77, 9.73],
[-0.82, 9.73],
[-1.11, 9.73],
[-1.08, 9.73],
[ 0.1 , 9.73],
[ 0.4 , 9.73],
[ 6.38, 9.73],
[ 7.32, 9.73],
[ 8.12, 9.73],
[ 8.28, 9.73],
[ 8.49, 9.73],
[ 7.51, 9.73],
[ 4.82, 9.73],
[ 0.06, 9.73],
[-2.25, 9.73],
[-3.78, 9.73]])
dz_dx = delta[:,0]/delta[:,1] # --- dZ/dX
dz_dx # ---- as a ratio
array([-0.07, -0.08, -0.08, -0.11, -0.11, 0.01, 0.04, 0.65, 0.75, 0.83,
0.85, 0.87, 0.77, 0.49, 0.01, -0.23, -0.39])
dz_dx * 100 # ---- as a percentage
array([ -7.16, -7.94, -8.4 , -11.44, -11.09, 1.08, 4.07, 65.5 , 75.23,
83.42, 85.06, 87.19, 77.15, 49.49, 0.65, -23.13, -38.83])
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dan, this is SO awesome! Pretty much exactly what I'm trying to get at...I'm going to keep experimenting with the code here, and I'll get back to you shortly.
Thanks, again!
Gav
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I will put a package together tonight Gavin... with the result for the 31 profiles and code to process new text files...
Do you need to graph these? (ie I can whip in some matplotlib graphing capabilities if you need it... I have code done for all kinds of those
Don't reinvent the wheel 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Attached is the script and the sample results.
Here is an example
Basically all you need to do is modify these 3 lines of code if you want to use a new text file.
And on that point... fix your column names and save as a *.csv file to make things easier to read.
You should test the code for readability.
if __name__ == "__main__":
"""make your changes to this section then `run` the script
"""
f = r"C:\Temp\elevation_profiles\elevation_profiles_dan.csv"
f_names = ['profile', 'z_st_end', 'first_dist']
f_types = ['int', 'float', 'float']
#
# ---- don't modify this
a, a_s, a_f, deltas, dz_dxs = process(f, f_names, f_types) # Neil A. magic sectionHere are two examples... as you can see, ID=29 is all downhill, ID=30, less so
ID 29
Xs [ 0.000 8.705 17.409 26.114 34.818]
Zs [ 902.513 900.543 896.635 891.272 883.877]
dX [ 8.705 8.705 8.705 8.705]
dZ [-1.969 -3.908 -5.364 -7.394]
dX/dZ [-0.226 -0.449 -0.616 -0.849]
down slopes [1 1 1 1]
down slope ratio 1.0000
ID 30
Xs [ 0.000 9.445 18.891 28.336 37.781 47.226 56.672 66.117 75.562 85.007]
Zs [ 871.432 878.691 885.234 892.904 902.854 907.207 905.885 900.993 893.996 886.938]
dX [ 9.445 9.445 9.445 9.445 9.445 9.445 9.445 9.445 9.445]
dZ [ 7.259 6.543 7.670 9.950 4.353 -1.321 -4.892 -6.996 -7.058]
dX/dZ [ 0.769 0.693 0.812 1.053 0.461 -0.140 -0.518 -0.741 -0.747]
down slopes [0 0 0 0 0 1 1 1 1]
down slope ratio 0.4444you can also do the change in the change and whatever, all the data are easily processed
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Dan,
Thanks so much for all of this...I'll be sure to let you know if I have any questions. I originally tried to take your methodology and apply it to my own code, but of course, I ran into a couple bugs. So in other words, thanks for the fully functioning code and output from the first set of profiles!
gav
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Mark it closed Gavin, so people know that one of these was an answer. keep me posted if you have issues
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »