- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Pro
- :
- ArcGIS Pro Questions
- :
- Normalizing Data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Normalizing Data
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
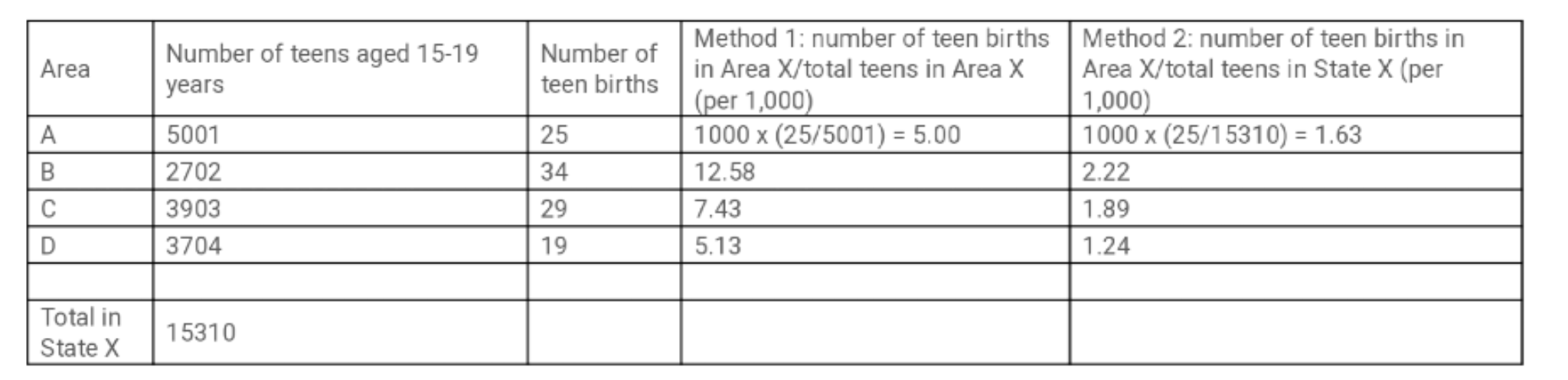
While I recognize that data can be normalized in multiple ways, using these two methods: I've attached a hypothetical table that summarizes the number of teen births in four areas (A, B, C, D), and let’s assume that these four areas make-up the entirety of State X. For each area, the number of teens and number of births is provided in addition to two different methods of normalizing the data to provide a teen birth rate:
Method 1: divide the number of births in Area X by the total teens in Area X (per 1,000) Method 2: divide the number of births in Area X by the total teens in State X (per 1,000)
Method 1: The interpretation under Method 1 is that there are 5 births that occur for every 1,000 teens in Area A. Often there is a need to standardize a rates when making comparisons to account for varying age distribution in the population. However, for teen births, this type of standardization is not necessary. I also recognize that the reliability of estimates may require some additional analyses, and in some situations using Bayesian hierarchical models for small area estimation may be more appropriate to apply.
Method 2: While the second method is one way to normalize the data, it is not a method classically used to depict the rate of teen births in local areas and inaccurate to refer to this as the teen birth rate by Area. The interpretation under Method 2 is that, for every 1,000 teens in State X, 1.33 births occur in Area A.
Questions:
- Which method would you use for presenting teen birth rates by Area?
- When presenting these data, can you speak to appropriateness of displaying an Area level rate as a point? For an example, there were 25 teen births that occurred in Area A. If the X-Y coordinates were available for each of the teen births that occurred in Area A, is it appropriate to display all 25 teen birth locations labeled with the value 1.63 (per 1,000)?
- In a performing a hot-spot analysis, is it appropriate to use the Area level rate values as input values for the X-Y coordinate points for teen births (as described in follow-up question 2). My understanding is that the Gedis-Ord gi statistic is used for areal data?
{kind=link}