- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Pro
- :
- ArcGIS Pro Questions
- :
- Re: Generate clustered random point data with set ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Generate clustered random point data with set number of points
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am working on a simulation to compare different models' estimates of population counts in areas with known total observations. I am using a preset amount of points (e.g. 50,000) to represent observations within my study area, and run models using line transects that overlap with those points.
I currently have a spatially balanced point feature class that acts as a uniform distribution, and another with point clustering based on land-cover type (stationary). I am trying to figure out a way to generate a third point feature class of 50,000 non-stationary randomly clustered points.
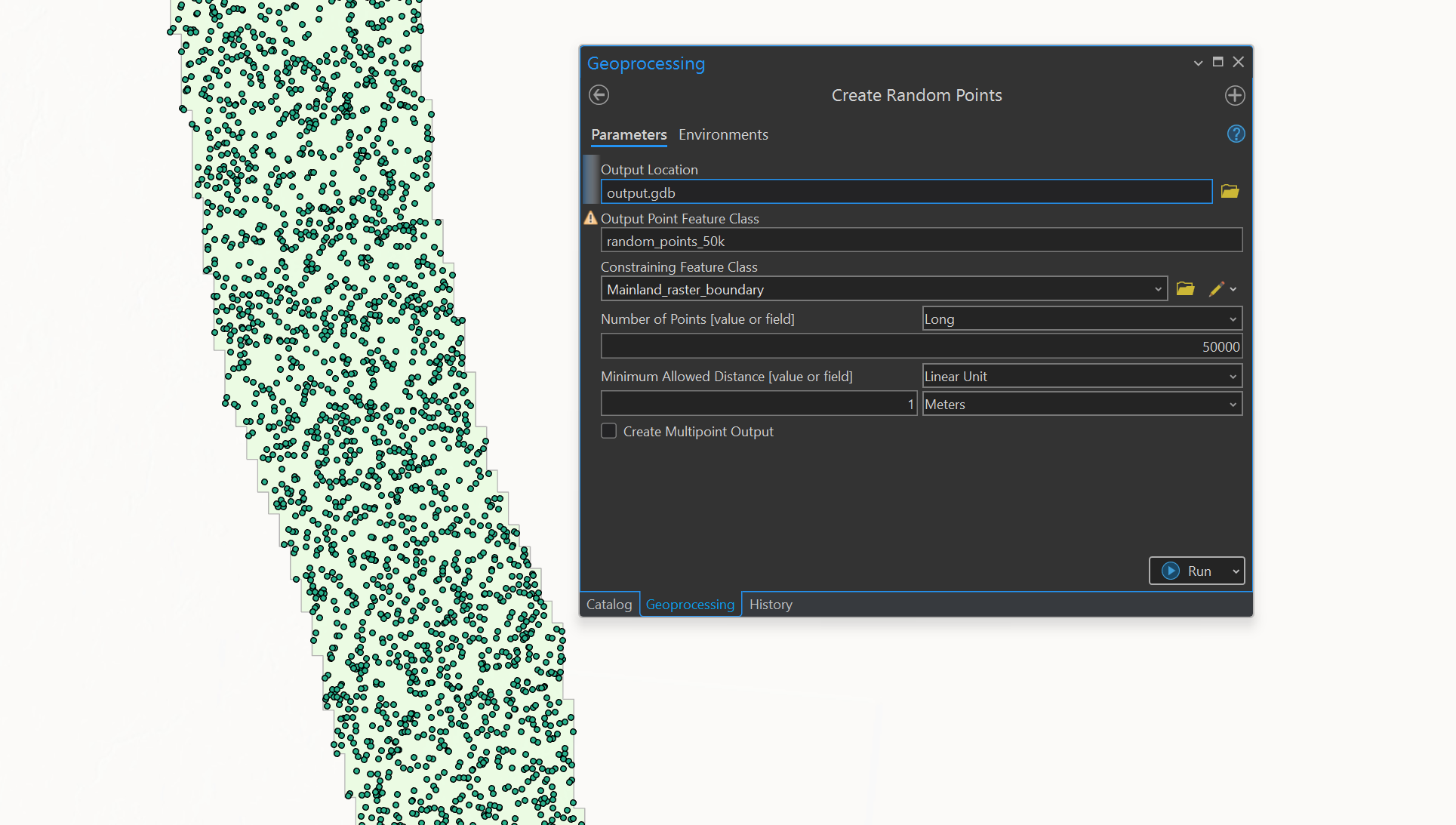
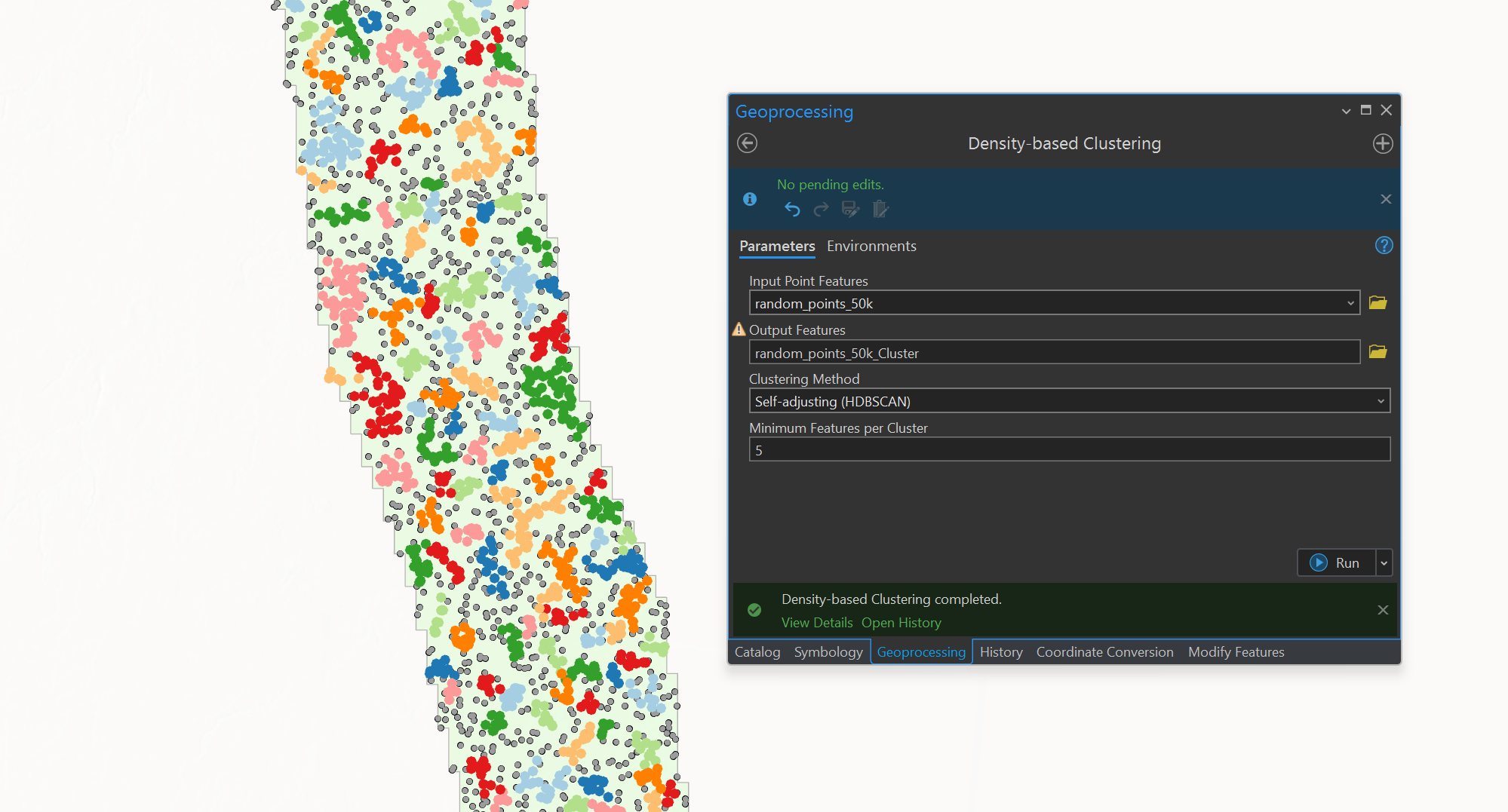
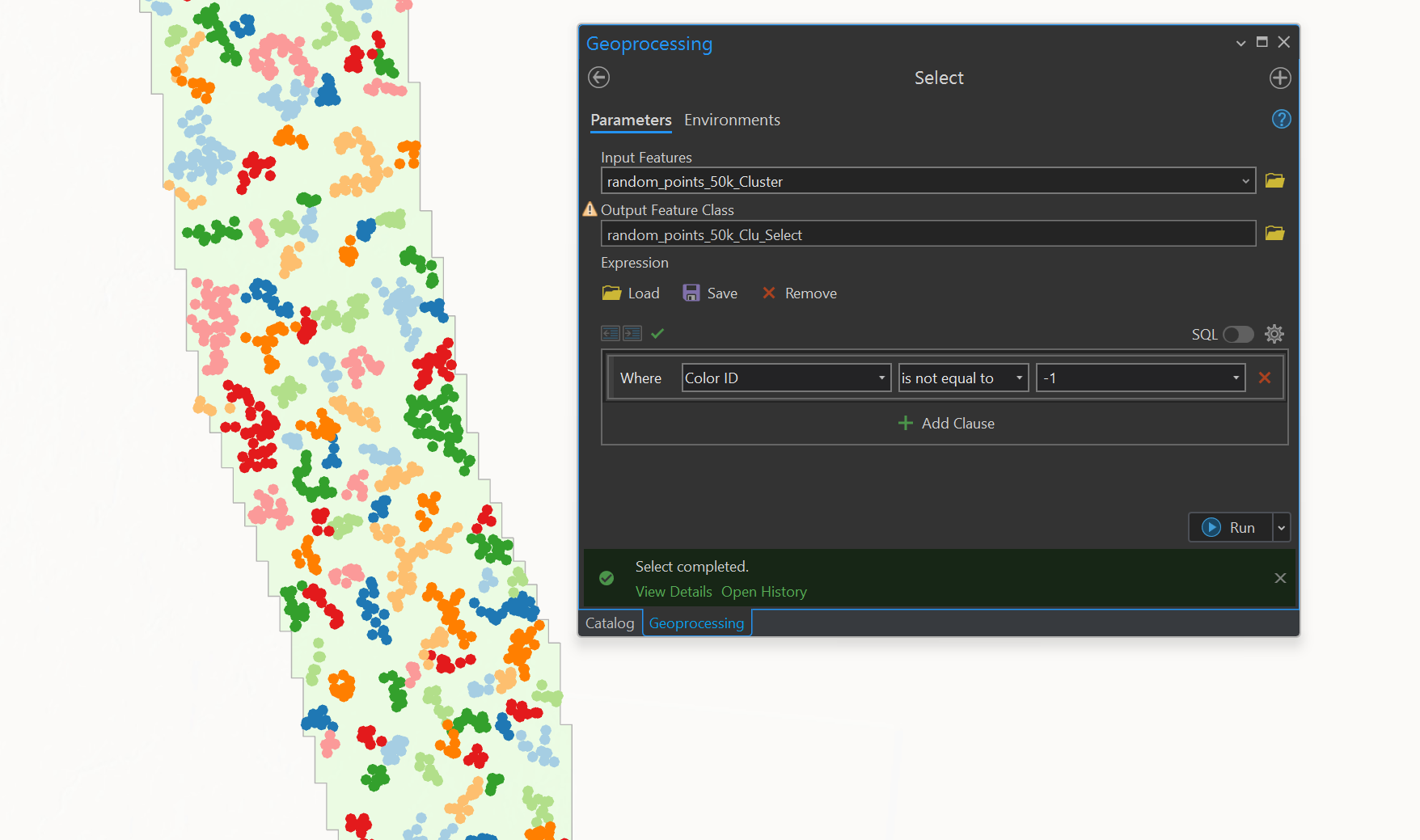
What I've tried so far is using the "Generate Random Points" tool to generate 50,000 points within my boundary, and set a low minimum allowed distance (e.g. 1 meter). Then I used the "Density-based clustering" tool to detect areas of clustered points and copied them to a new feature class. This leaves me with the clustered areas and no noise points. However with the noise subtracted I am left with far less than the desired amount of points. The output looks good but I would like to set the total number of points to be clustered. See screenshots for reference.
I could use a higher count of random points and use trial and error to end up with a clustered set around 50,000 but this wouldn't be ideal as I wouldn't have an exact count and it probably wouldn't be very replicable.
I assume this has been done before but I haven't been able to find how. Is there a way to achieve this using other geoprocessing tools or perhaps arcpy?
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
A naive approach:
- create clusters with random point counts until you reach 50k points
- create random center points for the clusters
- create buffers with random radii around the cluster centers
- use these buffers as constraining fc for the Random Points tool
Script:
import arcpy
import random
# tool parameters
output_folder = ""
output_name = "RandomPointClusters"
constraining_fc = "TestPolygons"
num_of_points = 50000
min_points_in_cluster = 20
max_points_in_cluster = 100
min_cluster_radius = 500
max_cluster_radius = 1500
min_point_distance = 1
# randomly distribute the points into clusters
rest = num_of_points
clusters = []
while rest > 0:
num = random.randint(min_points_in_cluster, max_points_in_cluster)
num = min(num, rest)
clusters.append(num)
rest -= num
print(f"{len(clusters)} clusters will be created.")
# randomly create the cluster centers
cluster_centers = arcpy.management.CreateRandomPoints("memory", "ClusterCenters", constraining_fc, None, len(clusters), min_point_distance)
# randomly create the cluster buffers
sr = arcpy.Describe(constraining_fc).spatialReference
cluster_buffers = arcpy.management.CreateFeatureclass("memory", "ClusterBuffers", "POLYGON", spatial_reference=sr)
arcpy.management.AddField(cluster_buffers, "NumOfPoints", "LONG")
with arcpy.da.InsertCursor(cluster_buffers, ["SHAPE@", "NumOfPoints"]) as i_cursor:
with arcpy.da.SearchCursor(cluster_centers, ["SHAPE@", "OID@"]) as s_cursor:
for cluster_center, cluster_id in s_cursor:
cluster_radius = random.randint(min_cluster_radius, max_cluster_radius)
cluster_buffer = cluster_center.buffer(cluster_radius)
num = clusters[cluster_id - 1]
i_cursor.insertRow([cluster_buffer, num])
# clip the cluster buffers with the constraining fc
cluster_boundaries = arcpy.analysis.Clip(cluster_buffers, constraining_fc, "memory/ClusterBoundaries")
# randomly distribute the points inside the cluster boundaries
arcpy.management.CreateRandomPoints(output_folder, output_name, cluster_boundaries, None, "NumOfPoints", min_point_distance)


This would be better with irregular cluster boundaries, as now it's very noticeable that they are circles. A random offset for each point could do the trick, too.
Have a great day!
Johannes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
A naive approach:
- create clusters with random point counts until you reach 50k points
- create random center points for the clusters
- create buffers with random radii around the cluster centers
- use these buffers as constraining fc for the Random Points tool
Script:
import arcpy
import random
# tool parameters
output_folder = ""
output_name = "RandomPointClusters"
constraining_fc = "TestPolygons"
num_of_points = 50000
min_points_in_cluster = 20
max_points_in_cluster = 100
min_cluster_radius = 500
max_cluster_radius = 1500
min_point_distance = 1
# randomly distribute the points into clusters
rest = num_of_points
clusters = []
while rest > 0:
num = random.randint(min_points_in_cluster, max_points_in_cluster)
num = min(num, rest)
clusters.append(num)
rest -= num
print(f"{len(clusters)} clusters will be created.")
# randomly create the cluster centers
cluster_centers = arcpy.management.CreateRandomPoints("memory", "ClusterCenters", constraining_fc, None, len(clusters), min_point_distance)
# randomly create the cluster buffers
sr = arcpy.Describe(constraining_fc).spatialReference
cluster_buffers = arcpy.management.CreateFeatureclass("memory", "ClusterBuffers", "POLYGON", spatial_reference=sr)
arcpy.management.AddField(cluster_buffers, "NumOfPoints", "LONG")
with arcpy.da.InsertCursor(cluster_buffers, ["SHAPE@", "NumOfPoints"]) as i_cursor:
with arcpy.da.SearchCursor(cluster_centers, ["SHAPE@", "OID@"]) as s_cursor:
for cluster_center, cluster_id in s_cursor:
cluster_radius = random.randint(min_cluster_radius, max_cluster_radius)
cluster_buffer = cluster_center.buffer(cluster_radius)
num = clusters[cluster_id - 1]
i_cursor.insertRow([cluster_buffer, num])
# clip the cluster buffers with the constraining fc
cluster_boundaries = arcpy.analysis.Clip(cluster_buffers, constraining_fc, "memory/ClusterBoundaries")
# randomly distribute the points inside the cluster boundaries
arcpy.management.CreateRandomPoints(output_folder, output_name, cluster_boundaries, None, "NumOfPoints", min_point_distance)
This would be better with irregular cluster boundaries, as now it's very noticeable that they are circles. A random offset for each point could do the trick, too.
Have a great day!
Johannes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Johannes,
Thank you for your response, this is a neat way of doing it!
I experimented a bit and it looks like using a high cluster radius (~max 5000) with a low cluster point count (~max 50) distributes the points nicely across the study area. The overlapping makes it look a bit more natural too.
I agree the irregular boundaries would be less obvious than circles, would you be able to elaborate on how would I go about randomly offsetting the points?
Thanks again,
Matthew

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Replace line 50 above with line 2 below (it just stores the result in a variable), move the offset parameters to the rest of the parameters for ease of access.
# randomly distribute the points inside the cluster boundaries
out_fc = arcpy.management.CreateRandomPoints(output_folder, output_name, cluster_boundaries, None, "NumOfPoints", min_point_distance)
# randomly offset each point
min_offset = 0
max_offset = 2000
with arcpy.da.UpdateCursor(out_fc, ["SHAPE@XY"]) as u_cursor:
for p in u_cursor:
x, y = p
dx = random.randint(min_offset, max_offset) * random.sample([-1, 1], 1)[0]
dy = random.randint(min_offset, max_offset) * random.sample([-1, 1], 1)[0]
new_p = [x + dx, y + dy]
u_cursor.updateRow([new_p])
before:

after (with quite high offset values):

Have a great day!
Johannes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Regarding irregular cluster shapes:
This would be an easy way to generate irregular (but always convex) buffer shapes:
def irregular_buffer(point_geometry, min_dist, max_dist, num_points):
points = []
for i in range(num_points):
angle = random.randint(0, 359)
dist = random.randint(min_dist, max_dist)
points.append(point_geometry.pointFromAngleAndDistance(angle, dist).firstPoint)
multipoint = arcpy.Multipoint(arcpy.Array(points), spatial_reference=point_geometry.spatialReference)
return multipoint.convexHull()
The num_points argument controls how much the buffer shapes resemble a circle. Higher value -> more circle-like.
num_points = 5:

num_points = 10:

num_points = 30:

To use this method, replace lines 41-42 in my original answer with this:
cluster_buffer = irregular_buffer(cluster_center, min_cluster_radius, max_cluster_radius, 5)
Which indeed results in more irregular clusters:

{kind=link}
{kind=link}
{kind=link}
And you can still add a random offset at the end.
Have a great day!
Johannes
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is great, thanks again for your help!