- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Network Analyst
- :
- ArcGIS Network Analyst Questions
- :
- Massive OD Cost Matrix
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Massive OD Cost Matrix
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I need to run a 900,000 x 240 OD Cost Matrix (not by choice!) and I'm looking for the most efficient way of getting this done. I'm using the StreetMap dataset, my destinations are spread throughout North Carolina and most of my origins are in NC, but not all are. I do have a limit of 180 min of travel time.
I recently did a 300,000 x 240 matrix by running subsets of 50,000 x 240. Each subset took about 2 weeks to process on a desktop dedicated to this (64 bit, 8GB RAM, windows 7, ArcGIS v10.1). The good news is I didn't run into any out of memory errors, the bad news is we could have had a power outage minutes before completion and I would have lost 2 weeks. Also, I did this manually and it was a bit of a hassle to keep track of the different subsets (I had several false starts and stops and I have 3 different desktops dedicated to this, which are living in different offices)
So, the question is, how best to tackle the 900,000 x 240 matrix (minimizing my time as well as computer time):
1) use the 50,000 origin subset concept since it worked before
2) automate a loop that runs much smaller subsets, say 1,000x240 - but this leaves me with lots and lots of files to merge together.
3) instead of subsetting the origins, subset the destinations (i.e. 900,000 x 10 and then run this 24 times)
4) other reasonable options? (Not doing it isn't an option).
Thanks for any ideas,
Heather
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Sounds like you have your hands full, but I think there are some options to speed up this process.
How familiar are you with Model Builder and Python? If not very familiar, the good news is there are plenty of tutorials to get you started.
Since you have done this before for a smaller dataset then you're already halfway there. Hopefully you remember all of your steps and settings.
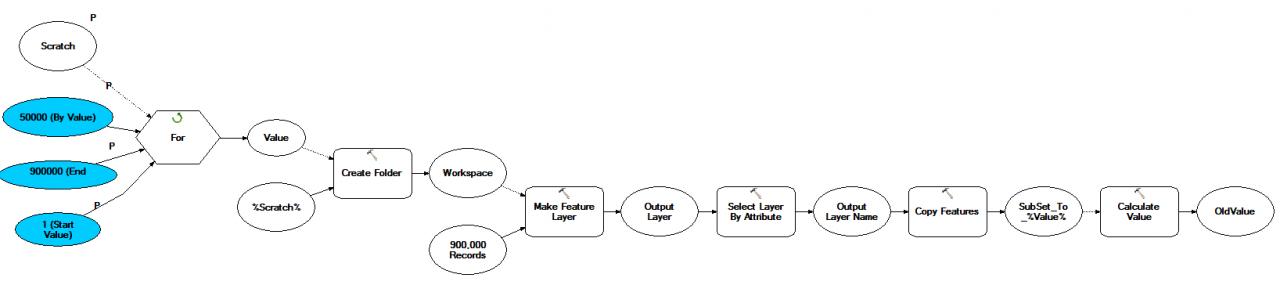
First, when you did your 50,000 subsets, you must have used a field to create the subsets (perhaps even the OBJECTID field). I would use Model Builder or Python to create the subsets for your 900,000. I would create a scratch folder for processing, and sub-scratch folders for each 50,000 subset. The model to do that would look like this:
[ATTACH=CONFIG]21345[/ATTACH]
The selection by attribute expression would look like this: "OBJECTID" <= %Value% AND "OBJECTID" >= %OldValue%
The OldValue takes the current value of OldValue (starting at 1) and adds 50000 to it at the end of each iteration.
This would create 18 subset folders with a shapefile in each one. Of course, you could have the outputs be feature classes in geodatabases if you prefer that work environment.
The next step would be to create a model using the OD Cost Matrix. Add your network, and go through all of the settings. From here you can export the model to a python script. Making sure each subset is still only creating layers within their own subset folders, you can copy/paste the python code, just changing the input locations to a new subset.
You can call python scripts through a batch file, which you can set to run all of your python scripts (one for each subset).
Ex.
start "scratch_file_path\subset_scratch_folder\pythonscript1.py > "scratch_file_path\log.txt" start "scratch_file_path\subset_scratch_folder\pythonscript2.py >> "scratch_file_path\log.txt" ... start "scratch_file_path/subset_scratch_folder/pythonscript18.py >> "scratch_file_path\log.txt"
If you do not use the /wait variable then all 18 will run at once.
Obviously, this is a very in-depth approach and involves some upfront work (and perhaps some learning of new things). However, for large jobs like yours, using scripts to do the processing can really reduce the amount of processing time (and headaches).
Hopefully some of this is helpful. I think it is very beneficial when analysts learn a bit of scripting. It definitely has it's benefits.
Happy Geoprocessing!
Chris B.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Heather,
Obviously, this is a very in-depth approach and involves some upfront work (and perhaps some learning of new things). However, for large jobs like yours, using scripts to do the processing can really reduce the amount of processing time (and headaches).
Hopefully some of this is helpful. I think it is very beneficial when analysts learn a bit of scripting. It definitely has it's benefits.
Happy Geoprocessing!
Chris B.
Hi Chris,
Thanks for the in-depth reply. I should have stated that I have a model to run the OD cost matrix process and exports the travel times to a geodatabase file. Though, in the past, I manually created the subsets (which doesn't take much time) and I haven't set up the model to run all the subsets consecutively, so your approach would save a bit of my intervention, but I didn't see how it would speed up the actual processing time - my guess is it would still take 2 weeks to run each subset or am I missing something?
Heather
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Rather than running each subset one after another, you could export the model scripts out to python, and run all of the python scripts through a batch file. If you simply put in the batch file:
start "full\path\to\your\python\file1.py" start "full\path\to\your\python\file2.py" ... start "full\path\to\your\python\file18.py"
Then all 18 python scripts would run at the same time. So 2 weeks for all of your processes, not just one.
It is just very important you are not processing each subset in the same directory, or you will probably get schema locks.
Hope this clears up any confusion.
All the best,
Chris B.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Heather
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am just curious what is the application, why do you have so many points ? I would appreciate if you could give the problem a context.
regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This work is for a health care access grant. So my origins are patients, destinations are facilities that provide a particular service. I'm doing this for different areas of the country. I am hoping that the 900,000x240 is my largest OD cost matrix, but won't know until all the data comes in.
I've got my python queries set and managed to run a very small sample as a batch and all worked great - thanks Chris. However, now I'm wondering how best to optimize this process (for minimum processing time - I worry that if I leave a process running for 2 weeks, we will have a power outage and I'll have to start over). I currently have it set up to do 18 subsets of 50,000 origins each. But would it run quicker with 36 subsets of 25,000 or would this just overload the CPU? It is hard to test this out since everything takes so long, so if anyone has experience in this, it would be great to know as I sense there are a lot of OD Cost Matrices in my future.
Thanks for the advice, really appreciate it,
Heather
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I spread my 18 subsets over 3 machines with Xeon processors, started the batches last night and I came in this morning and voila they were done. Didn't believe it could work so quickly and sadly, it didn't. The results in the OD Cost Matrix table look correct (I've only tested a few as of yet), however, it didn't solve for all the Origins. I had subsets of 50,000 origins and in one set, it only solved the first 1,443 origins, in another the first 9000 - and these were run on the same machine, in the same batch. The OD Cost Matrices ended up with vastly different numbers of rows. For example, in one batch, one matrix had 6,594,231 rows, another 1,021,000 and 155,000 (there were 2 more in this batch that I haven't looked at yet).
I'm doing all the processing in file geodatabases, one for each subset, so I don't think I'm bumping up against any size limits. Each GDB is in a separate folder - although all of these folders are subsumed in one folder.
I have 48GB of RAM and gobs of harddrive space, so I don't think that is the issue.
Anyone have any idea what is going on? Or how I can log error messages so I might have a clue as to what is going on?
Thanks,
Heather
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Heather
I'm not sure about if this is the problem, but when I manually load locations and solve the process use to loose a lot of locations.
I after loading I reload again the locations then the solving runs over all origins and locations.
I don't know whats the problem but seems tha the SOURCEID is not loaded at first run, means that don't link the point to the network. The Od matrix seems that really uses the position in the road as a location. When I reload then the SOURCEID appears at the attribute table.
My problem is 37256x37256 -USA cities-, so I need to iterate a model with low origins and all destinations. When runds 1 to 37256 takes 5 minutes to load and 1:40 min to compute all the routes.
Any idea like the 'Chris's one would be appreciated.
Thanks
Ferran
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello Heather,
I'm facing the same issue with massive OD matrix calculations, but not as massive as yours: 34,000+ incidents x 79 destinations, which is even smaller than your subsets. Yet my workstation seems to have run out of memory after running my Py script for the first time on such *big* data (works ok on smaller sets of data).
What is/was your desktops' average hardware settings (RAM, CPU, ...)?
Thanks for your hints,
- Yann