- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Network Analyst
- :
- ArcGIS Network Analyst Questions
- :
- Re: Geographically splitting a problem into smalle...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Geographically splitting a problem into smaller chunks, produces lower total impedance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
We are trying to create a fixed number of facilities across a region to service a bunch of demand points.
After we ran the problem we summed the total amount of length in the problem.
We then ran the problem again but with the facilities and demand points broken up into smaller regions.
The problem is: when the total length in all of the smaller problems is summed together the result is lower than in the single larger problem.
Our premise that makes us think this is a problem is: the larger problem contains the solutions of the smaller problems, so the algorithm should be at be able to at least match the solution.
Is our premise wrong, or is there some limitation of the algorithm that we are not aware of?
Many thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
What solver are you using? Location-Allocation? If yes, it uses heuristics to solve the problem. If you change problem space, you may get a slightly different answer. From your post, it is not clear how you model it "broken into smaller parts". Are the number of candidates still the same? Are cutoffs still the same? How different are the results?
Jay Sandhu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
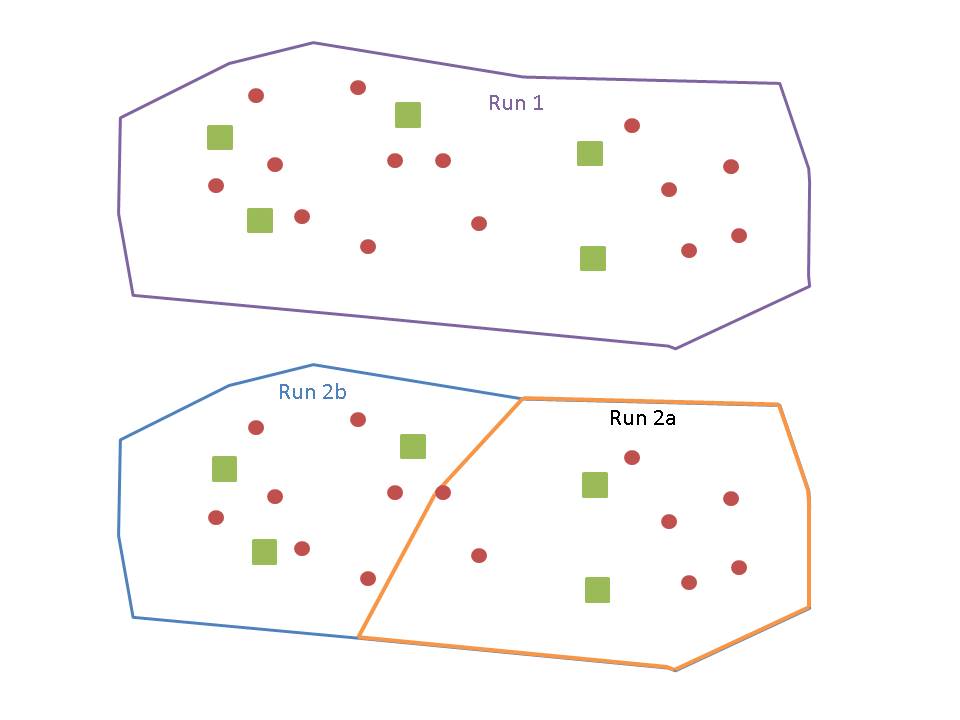
Hi Jay,
Thanks for taking the time to reply to my question.
I've tried to make a picture that explains what I mean.
I'm using location allocation (I've tried both maximise capacitated coverage and minimise impedance), I keep all the parameters the same between runs (this is being run in a Python script so is easy to do).
The results are approximately 5% worse in scenarios without the breakdown (at this point we have tried quite a few runs with different setups).
Hope this helps you understand our position.
Thanks again,
Jake
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I see the picture with the subset. It is solving quite a bit different problem so there is no guarantee the solution will be the same. However I am not sure you will consistently see an improvement by doing subsets. So given the above picture, you are solving for 2 and then in the subset you are solving for 1 each?
How are you comparing the results? What metric? Do you take the chosen facilities from the subsets and make them required in the whole and resolve to compare?
Do note that Maximize capacitated coverage has a different objective then minimize impedance. Sometimes they give the same answer. (for coverage the goal is to cover the most demand within the cutoff honoring facility capacities).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Jay,
The total number of facilities chosen is the same between run 1 and run 2 (so yes, for example in run 1 we would solve for two, then run 2 we would solve for 1 in a and 1 in b).
We are checking the sum of the impedance and the average impedance in run 1 vs run 2 (both are improved in the subsets).
No we are not fixing any of the facilities at any point (not sure what this would show?).
I think I understand the differences between the two problem types, for the sake of understanding lets stick to minimize impedance. (we are not setting an impedance cutoff, so were hoping that maximise capacitated coverage would be optimising purely the impedance whilst honouring capacity caps).
As of yet, every run we have done has seen an improvement in the subset (which is why we are confused).
Many thanks,
Jake
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In location-allocation minimize impedance type, we minimize the sum of weighted impedance. That is, demand weight multiplied by the impedance to the facility. So you should only compare weighted impedance. If demand weight is all one's, then you can compare sum of impedance.
>No we are not fixing any of the facilities at any point (not sure what this would show?).
Go to the whole solution. Make the chosen facilities from Run2a and Run2b "required" and solve. Now you are taking the solution found in the subset and solving in the whole. You can now compare the solution quality found in the subsets with the one from running whole. That is, compare the sum of weighted impedance before and after you made the facilities required. This will give you a way to compare the results of the subsets with the whole.
Jay Sandhu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
For purposes of discuss lets assume we are using sum of weighted impedance (we are actually doing some post-processing to make things easier in our BI tool).
I see where you are coming from with regards to fixing the facilities to make the solutions comparable. The reason this doesn't solve our issue is that we don't actually care what the facility locations are.
Our actual objective is to determine the performance impact if the real world operation was/was not segmented (namely the difference in impedance).
Thanks for all your help,
Jake
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
>Our actual objective is to determine the performance impact if the real world operation was/was not segmented (namely the difference in impedance).
In that case, you need to carefully determine a way to measure the real world operation to compare between different simulations. For example, Location-Allocation may be used to locate warehouses, but then the Vehicle Routing Problem (VRP) solver is used to make the actual daily deliveries from the chosen warehouse. In that case one would measure the performance (on-time, minimize costs, etc) from the delivery operations for a few days runs to see if the locations are good. But I know you understand what you are measuring. Regards,
Jay Sandhu