- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Enterprise
- :
- ArcGIS Enterprise Questions
- :
- Portal for ArcGIS 10.5.1 HA Failing
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Portal for ArcGIS 10.5.1 HA Failing
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
We setup Portal for ArcGIS 10.5.1 in high-availability (active-passive) environment. It was running fine until a fail over happened, it recovered by switching from primary to standby site. The site came back with in stipulated time of 5-6 minutes but after recovering the performance of the portal degraded. Following the error message in portal log
- "HA: error in HA plugin. The semaphore timeout period has expire”.
- Cannot read from directory path <> Please check that the location is valid and that the Portal service account has permissions to the location. (Please refer file attachment)
For the second error message above > Confirmed the location and permissions
Some weird behavior:
1) Primary site shows status Health Check successful, the portal is ready
Secondary portal site shows Error Site is not ready yet Code: 500
2) Primary site shows status shows Error Site is not ready yet Code: 500
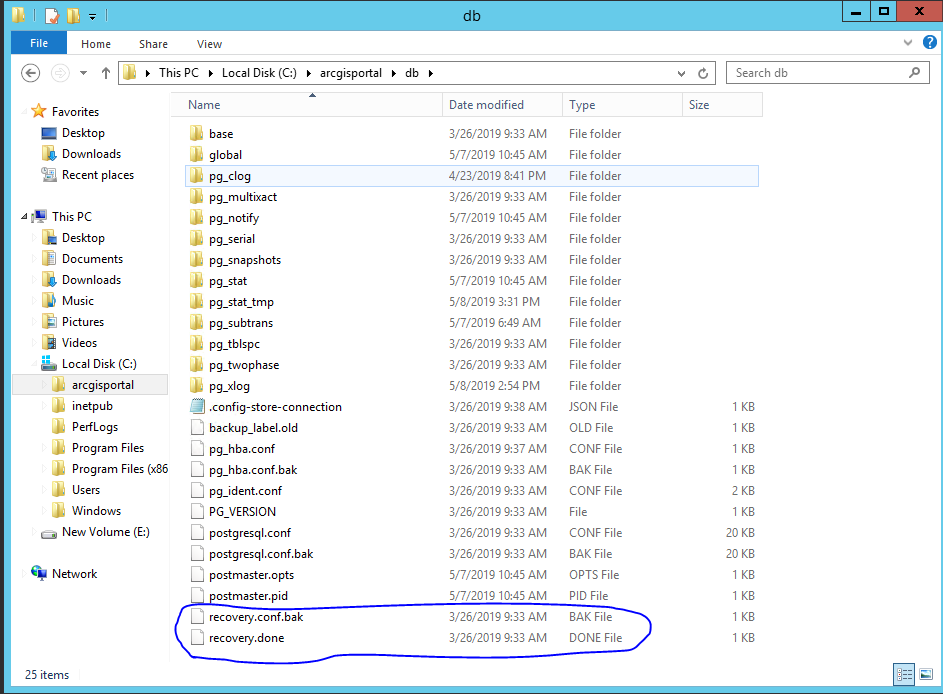
In this scenario, ideally switch over should happen and secondary site should be updated as Primary but it is not happening. If you refer the db directory from standby machine it shows "recovery,done" file (latest one), even there is a "recovery.done" file (old one) in the primary site (Please refer the attachments)
3) Sometimes both primary and secondary are active and shows “Health Check successful, the portal is ready”
Some message in standby portal log (hope this makes sense) "HA: The primary server <Machine Name> is identical to the master <Machine Name)"
Performance has degraded badly, even the service listing in ArcGIS REST Services Directory is very slow. Enough RAM is available and CPU usage is also low in server.
Restarted Portal in following order:
- Stopping Portal Order: Stop first the standby Portal, then stop primary Portal.
- Starting Portal order: Start first the primary portal, then start standby Portal.
Attached screen captures of following:
- Portal Log
- Primary and secondary portal folder
- Primary and secondary db folder
Highly appreciate any suggestion as this production environment is down @Jonathan Quinn
Thank You
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm not sure what The semaphore timeout period has expire means, but a quick Google search turns up a lot of instances of that type of error.
A couple things to do:
1) Check that the account used to run the Portal service has access to the shared content directory. You can log onto the machine with that account to verify.
2) Remove the recovery.conf from the primary machine. It should only exist on standby.
None of those should cause permissions problems, but they are they easiest things to get out of the way before addressing the performance problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank You Jonathan,
Appreciate your suggestions, shall implement and keep you posted.
Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Jonathan,
1) We checked, the account has access to shared content directory and even logged onto the machine successfully.
2) Removed the recovery.conf from the primary machine.
While browsing through the content directory discovered that the size has grown to 29 GB and out of which 27 GB are of files from a particular date (Sept 2018). We are not sure what is the reason?
We even tried successfully re-registering the standby site, but no change in performance.
Do you think re-federating the server site is good option? Believe there will be good amount of rework for portal contents.
Appreciate your help and support!
Thank You
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So if you were able to log onto the machine and access the shared content directory, there shouldn't be a problem with Portal doing the same thing. I assume you're still seeing the "Cannot read from directory path" error?
I'm not sure why the content would have grown so large. You should identify what files were created during that time, search for the itemID within Portal, and identify who created the items.
No, re-federating isn't a solution and will cause more problems. How long does it take for https://portal.domain.com:7443/arcgis/sharing/rest/portals/self to return a response?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The response was fast (within second) while accessing https://portal.domain.com:7443/arcgis/sharing/rest/portals/self
One observation, the property of content folder on the shared network drive shows "size" as 744 MB and "size on disk" as 29.3 GB (attached is the screen capture), however when we copied the content folder on a local drive the "size" and "size on disk" is same i.e 744 MB. The intention copying content folder to other location was to edit the content directory path but it failed with error "Unable to unzip the portal content". Please let us know if it is acceptable for you if we share the logs to or you require any particular information? Appreciate your time and support.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm not sure why those values would be so different.
Updating the content directory doesn't unzip any data. In fact, you have to move the content directory yourself prior to updating the directory path in Portaladmin.
Performance problems are difficult to troubleshoot via Geonet. I'd suggest you open a case with Tech Support to continue working on this.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank You Jonathan, Appreciate your help and support on this issue. Shall keep you posted about the resolution.