- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Enterprise
- :
- ArcGIS Enterprise Questions
- :
- ArcGIS Server: Missing layers in services... Clear...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
ArcGIS Server: Missing layers in services... Cleared Rest Cache Fixed Issue (v10.3.1)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
FYI only... posting to community in case others run into the issue...
Problem:
Every once in a while (month or two) we get reports from users that some layers in some services are missing. Our monitoring does not catch this condition since its very sporadic. Here is an example of the available layers in a service (normally):
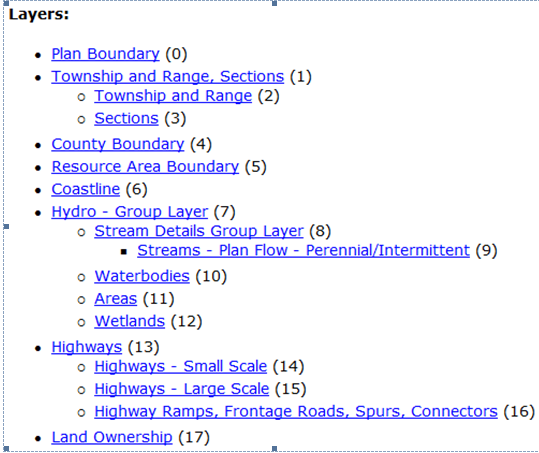
The layers as they looked today during this condition:

Resolution:
Bottom line... Clearing the rest-cache in the admin API resolved our issue:
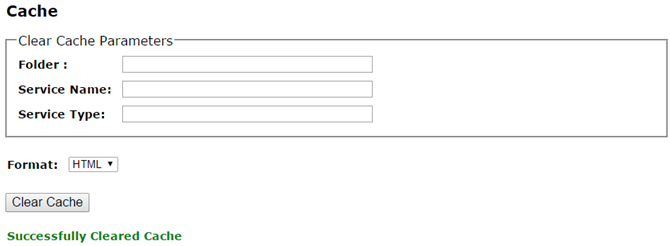
Background:
We have quite a few ArcGIS Server (AGS) deployments. A mix of web-tier and token based security... This problem has occurred on both (confirmed v10.3.0 using token and v10.3.1 using web-tier). All AGS deployments are Virtual Machines (VM's) running WIN Server 2008 R2 and configured with access from web-adaptors hosted in IIS. Not federated with portal (stand-alone).
We have our config-store/directories on a dedicated file server (running multi-machine sites)... and configure the arcgis server to use a DFS path (we have had to move it around a few times... and this makes it really easy for us to move it).
We normally publish web-services with the source data in a File Geodatabase (FGDB) residing on disk, mapped with a DFS path as well (but those are usually on a different file server).
User-store is configured to use "Windows Domain" and role-store is built-in.
We are doing basic host based monitoring (every 60 seconds) using the IPSwitch Whats Up Gold (WUG) product based on standard PING, windows services (ArcGIS Server) and some HTTP Content monitors (for some high-use services and the root on the rest-endpoint over port 6443)
Further Thoughts:
I really do not like relying on server/service reboots to solve our issues... Our servers are already rebooted too often (mostly for patches being applied) and I think that is what ultimately caused this issue. I would prefer to find the 'component' degraded and fix that individually without an aggressive reboot. The site impacted today has 2 back-end AGS hosts, both of which went offline for ~6 min around 3:30am:
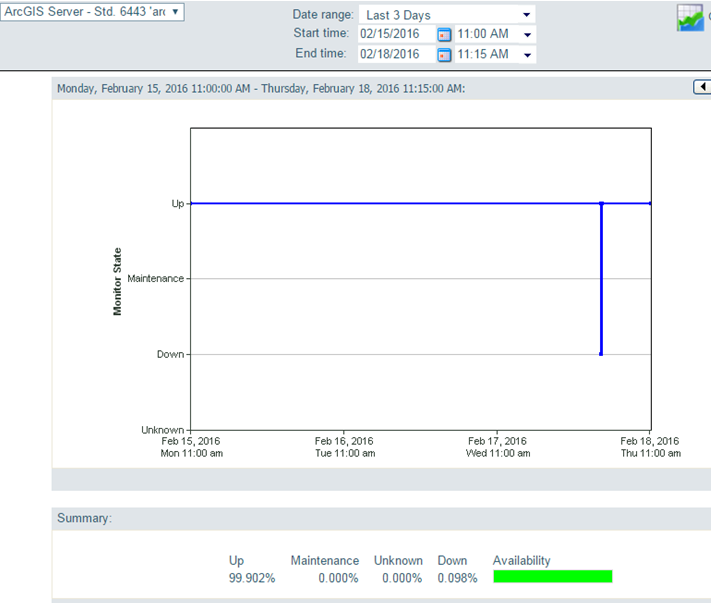
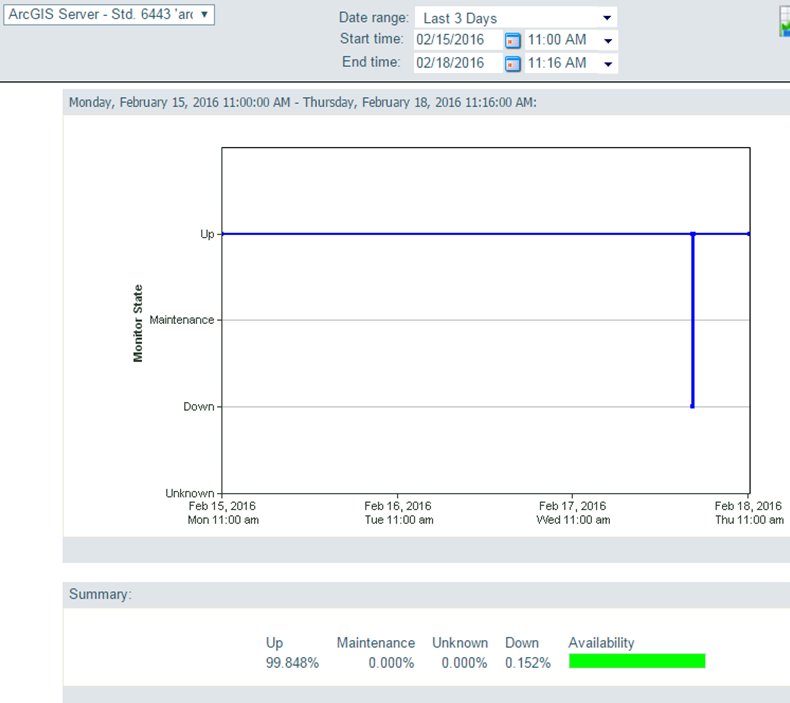
The back-end file servers (both config-store/directories and FGDB hosting) were still online during this time period:
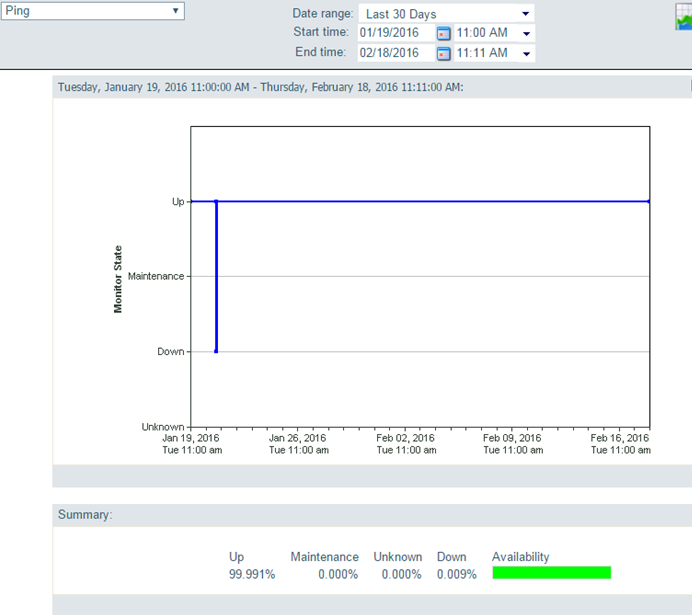
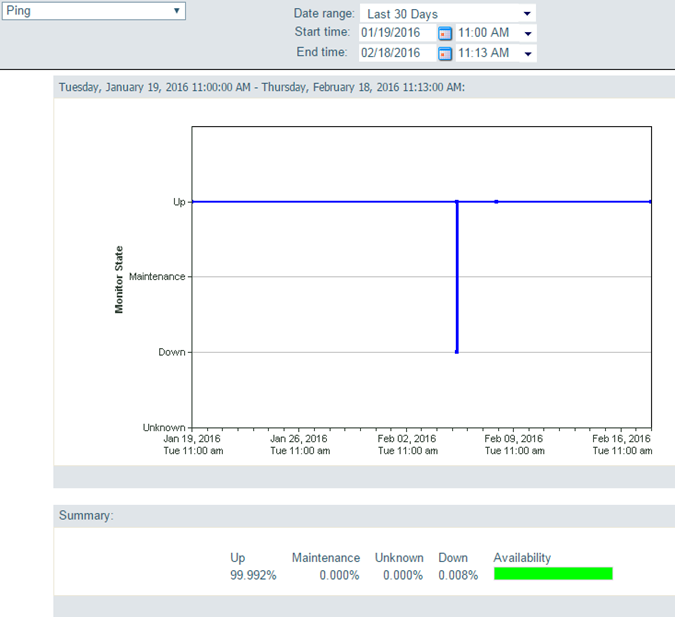
Before clearing the rest cache... I stopped both of the machines from the AGS manager (web-based). I watched all the ArcSOC.exe's go away and it left a handful of .exe's behind including 1 javaw.exe. Starting both machines back up brought back all ArcSOC.exe, but testing from multiple machines showed the missing layers still. I did not execute a windows service re-start, and suspect the issue would have been resolved that route (since all .exe's would have disappeared).
If this continues to be a problem we will most likely script a REST cache clear for all the ArcGIS Server deployments and schedule run in the early morning. This is a hard condition to identify since we have so many services hosted and IT does not know what layers are in what services (that is managed by the GIS users).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Patrick,
Thank you for posting your item.
FYI part two here, and I'll post in a geonet discussion too.
Today we noticed similar "missing layers" is some ArcGIS Server 10.4.1 map services and found that the SQL Server windows services for our enterprise geodatabase that are set to start automatically did not start after a maintenance reboot last night.
Starting the windows services manually works fine but some of the GIS map services were still only showing partial list of layers.
Those SQL services are now changed from Automatic to Automatic (Delayed Start)
I think they used to be set to Automatic (Delayed Start) but a recent SQL Server back in November to update from SQL 2008 R2 to SQL 2014 to get compliant with ArcGIS 10.4.1 probably set them back to default of just Automatic.
We hadn't rebooted the SQL Server during the holidays until a couple weeks ago and thought the services not auto-starting was just a fluke.
We'll see if the Automatic (Delayed Start) works during the next maintenance window.
The troubleshooting led us to this Microsoft Bug: 59557
It seems because our servers are now virtual on fast SSD drives, they boot too fast for service domain #user accounts to get authenticated.
This Microsoft article outlines a work-around registry edit we can also try.
-Bill
ServicesPipeTimeout #Service_Does_Not_Start_Automatically
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The logs should give you a good indication of what's going on when the layers can't be accessed. Do you see any errors? It'd be interesting to see if they coincide with the recycling time of the service. A good tool to use would be ProcMon to see exactly what the problem is when the Server is trying to reach the data and can't. You'll likely need to use a lot of filters and clear out the ProcMon log every so often as it could grow quite large in size.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Where is the ArcGIS Enterprise configuration to automatically e-mail such logs to system administrators?
Example:
1) Portal for ArcGIS / GIS Server / Web Adaptor service stopped/started or not responding
2) ArcGIS Server site lost communication to ArcGIS Data Store xyz and these registered data locations
3) ArcGIS Data Store xyz is now in read-only mode due to full-disk drive
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Unfortunately, there's no built-in mechanism to send emails when WARNING or SEVERE logs appear. The approach would be to run a script at a prescribed time to query the logs for specific messages or codes and send emails if necessary. We're know that such a system is necessary, though, so it's something we'll be looking at for later releases.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
We use this same configuration and run into these issues occasionally. When the SQL server reboots, but the ArcGIS Servers don't, the quickest fix is generally to restart the ArcGIS Server services on the servers one at a time. I always patch in waves and ensure the ArcGIS Servers reboot last and not at the same time, this generally fixes the issues that occur after patching. We are investigating monitoring systems options, since defining this stuff in Solar Winds would be a fulltime job for someone. ESRI has a monitoring package that uses mongoDB booked though Consulting services, and vestra and latitude have products for this as well.