- Home
- :
- All Communities
- :
- ArcGIS Topics
- :
- GIS Life
- :
- GIS Life Blog
- :
- Real-time Geodatabase Replication? Part 2
Real-time Geodatabase Replication? Part 2
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Setting up a Publication Server
First a little side-step to prepare our GIS table for replication. More on the caveats later!
In order to participate in replication a SQL table will need a column flagged as a ROWGUID column. In Dear GlobalID: I Hate You! Rants from an OCD data manager we talked about the Global ID Unique Identifier. We're going to use it to tell the Replication engine that this column is also used to manage changes between the Publisher database and any subscribers. There are two requirements for this column:
- It has to default to newsequentialid();
- It has to be flagged as a ROWGUID column.
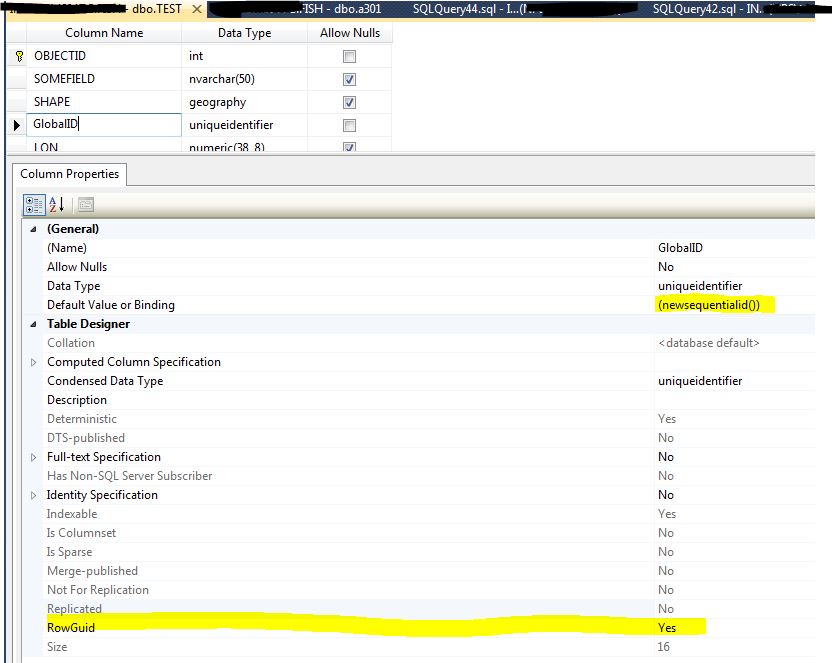
If you don't set the GlobalID to be the ROWGUID, when you create the publication a new ROWGUID column will be created for you, outside of the "ESRI stack", which will cause problems when you attempt to edit this feature class (as this new column has been created without the participation and consent of SDE).
In Microsoft SQL Merge Replication you first need a publication server, from which other SQL servers can "subscribe" to replication articles published by the publication server.
In SSMS launch the New Publication Wizard and select the Fish Database as the publication database. Select Merge Publication as the publication type.
Since we're using the Geography Storage type we don't need to publish any other table other than the "Test" base table. Select "Test" as the Object to Publish.
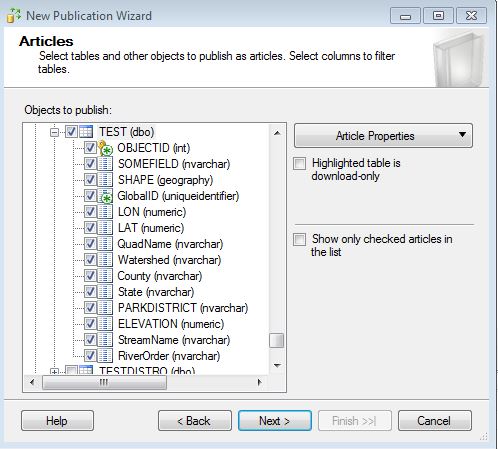
Instinctively you think we need more tables than that considering how Arc SDE manages data. The secret will be revealed in a few more posts. Don't filter any tables.
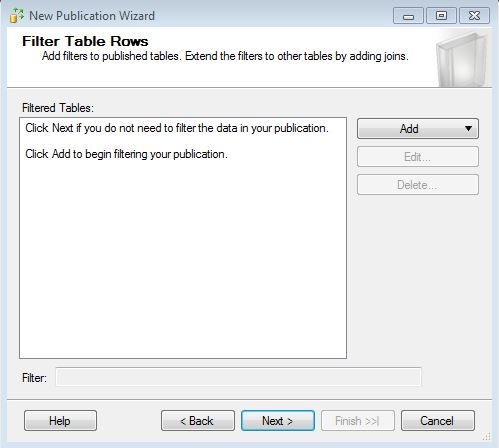
Configure the Snapshot Agent to run every hour (you can pick any schedule you like!).
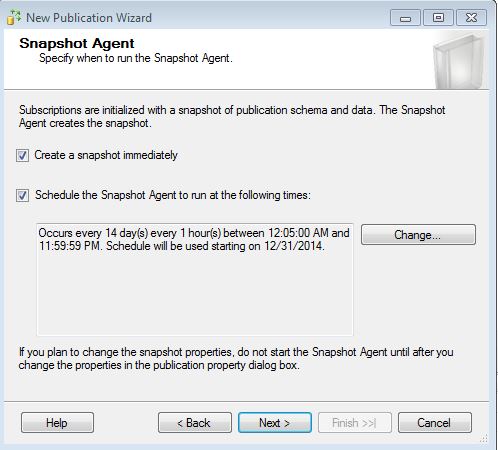
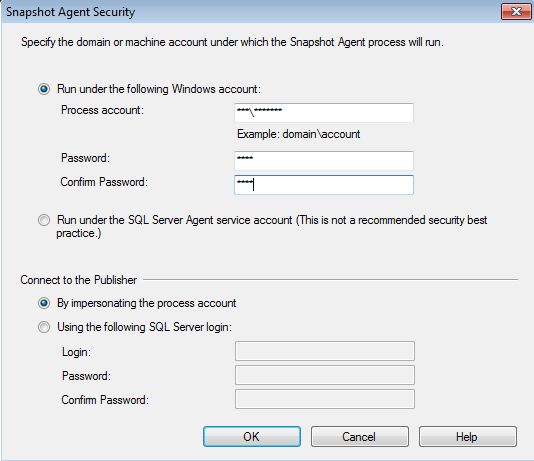
Set the Snapshot Agent to use a domain account (ideal).
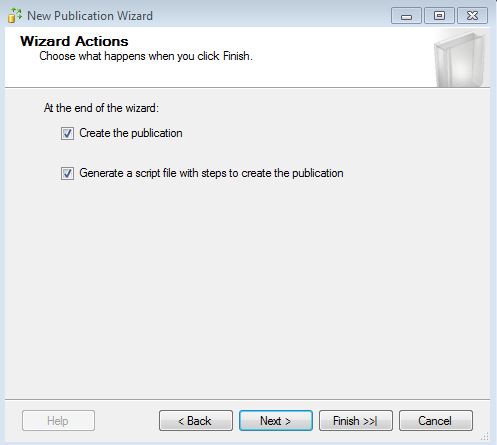
Then check Create the publication and Generate a script file. Not pictured, but one of the dialogues will ask you where the Snapshot files will go. Be sure to pick a network share that both servers will be able to access. It's very important that you check the box that asks if you want to create the script that will generate the Publication Agent!
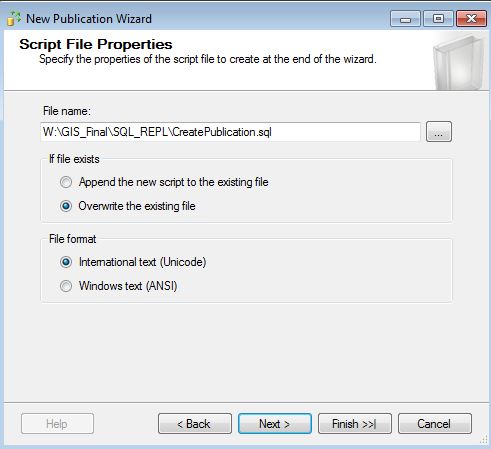
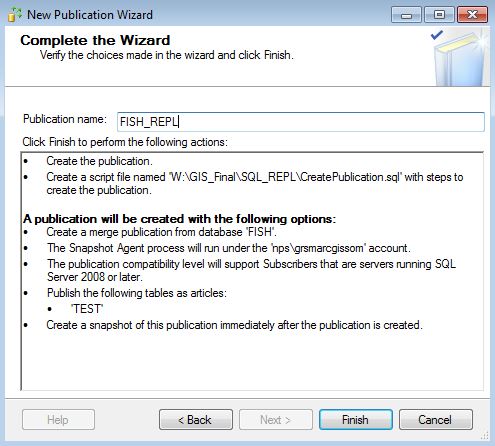
Make sure the Publication and Snapshot Agent is working by Launching Replication Monitor and starting the Agent. The directory you picked to host the replication articles should start filling up with some files.
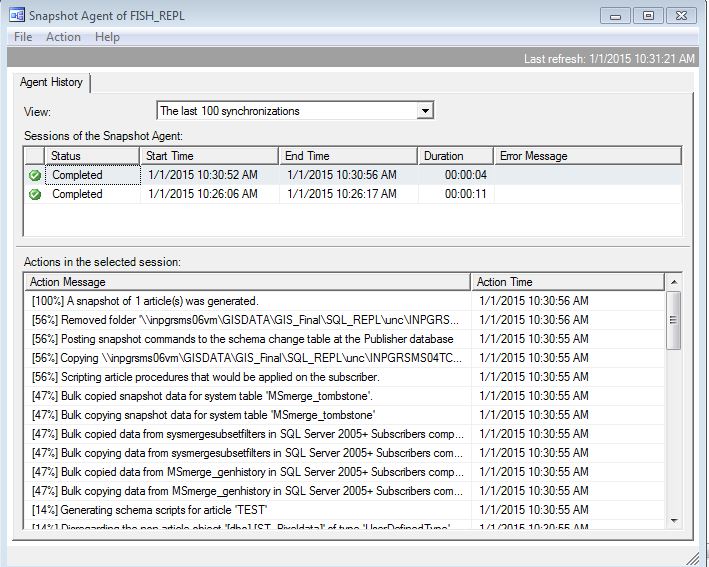
You should see a status of [100%] in the last action column.
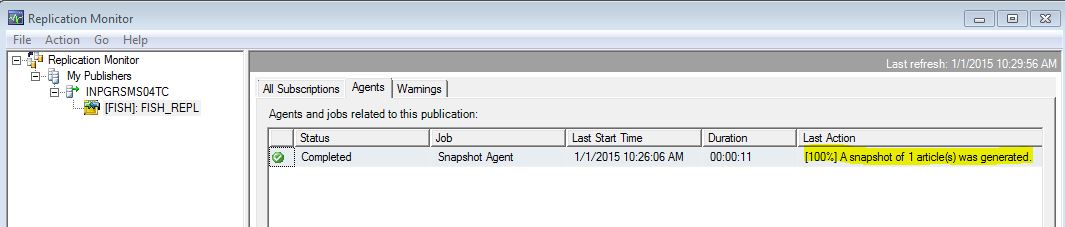
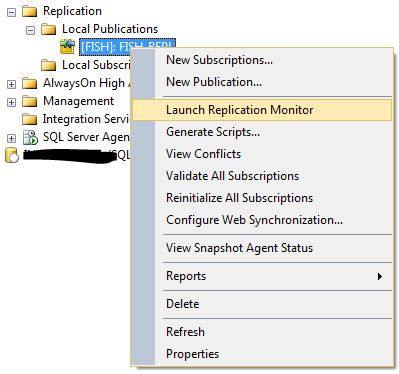
Double-click on the agent and select Action -> Start Agent. Wait a few minutes and select Action -> Refresh. You should see another successfully completed Agent job.
Now review the Publisher Properties. It's good that you see how all of the pieces are put together! In Replication Monitor in the left window pane select the Replication (FISH) and right-click -> Properties. You should see:
 Note here in the Location of Snapshot files that they are going to a UNC network share that the domain account used to run the agent has full access to.
Note here in the Location of Snapshot files that they are going to a UNC network share that the domain account used to run the agent has full access to.
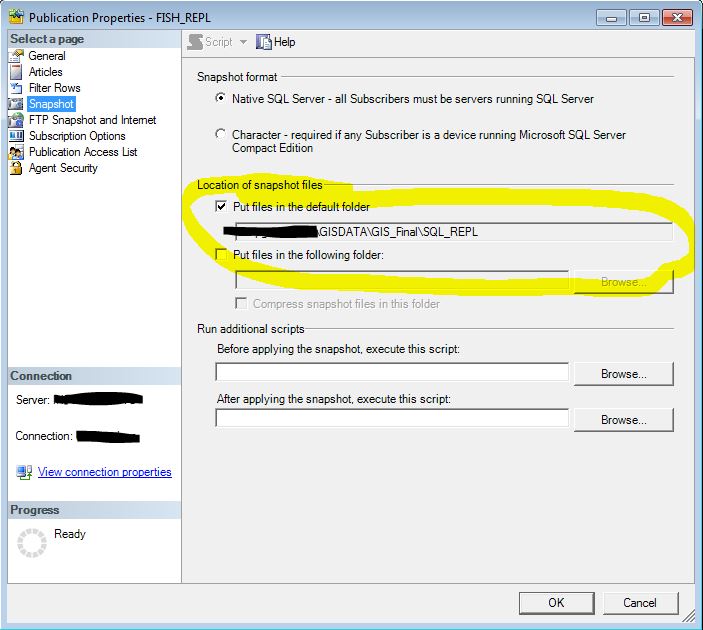
We need to make a few changes though.
Convert filestream to MAX data types is set to False by default. If you attempt to Subscribe to this publication any column data in a Geography or Geometry column will be converted to a string during the replication process. Not good for GIS data! The only way to correct this is to delete the publication and recreate it programmatically. However since you saved the script the created the publication all you have to do is edit two lines of that script and re-run it!
use [FISH] exec sp_replicationdboption @dbname = N'FISH', @optname = N'merge publish', @value = N'true' GO -- Adding the merge publication use [FISH] exec sp_addmergepublication @publication = N'FISH_REPL', @description = N'Merge publication of database ''FISH'' from Publisher ''INPGRSMS04TC''.', @sync_mode = N'native', @retention = 14, @allow_push = N'true', @allow_pull = N'true', @allow_anonymous = N'true', @enabled_for_internet = N'false', @snapshot_in_defaultfolder = N'true', @compress_snapshot = N'false', @ftp_port = 21, @ftp_subdirectory = N'ftp', @ftp_login = N'anonymous', @allow_subscription_copy = N'false', @add_to_active_directory = N'false', @dynamic_filters = N'false', @conflict_retention = 14, @keep_partition_changes = N'false', @allow_synctoalternate = N'false', @max_concurrent_merge = 0, @max_concurrent_dynamic_snapshots = 0, @use_partition_groups = null, @publication_compatibility_level = N'100RTM', @replicate_ddl = 1, @allow_subscriber_initiated_snapshot = N'false', @allow_web_synchronization = N'false', @allow_partition_realignment = N'true', @retention_period_unit = N'days', @conflict_logging = N'both', @automatic_reinitialization_policy = 0 GO exec sp_addpublication_snapshot @publication = N'FISH_REPL', @frequency_type = 4, @frequency_interval = 14, @frequency_relative_interval = 1, @frequency_recurrence_factor = 0, @frequency_subday = 8, @frequency_subday_interval = 1, @active_start_time_of_day = 500, @active_end_time_of_day = 235959, @active_start_date = 0, @active_end_date = 0, @job_login = N'domain\account', @job_password = null, @publisher_security_mode = 1 use [FISH] exec sp_addmergearticle @publication = N'FISH_REPL', @article = N'TEST', @source_owner = N'dbo', @source_object = N'TEST', @type = N'table', @description = null, @creation_script = null, @pre_creation_cmd = N'drop', -- Change 0x000000010C034FD1 to 0x000000000C034FD1 @schema_option = 0x000000010C034FD1, @identityrangemanagementoption = N'manual', @destination_owner = N'dbo', @force_reinit_subscription = 1, @column_tracking = N'false', @subset_filterclause = null, @vertical_partition = N'false', @verify_resolver_signature = 1, @allow_interactive_resolver = N'false', @fast_multicol_updateproc = N'true', @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N'true', @compensate_for_errors = N'false', -- Change true to false @stream_blob_columns = N'false', @partition_options = 0 GO
In the code above which was saved when the Publication Agent was first created @schema_option has been changed to 0x000000010C034FD1 and @stream_blob_columns has been set to false.
Run the script however note that you will have to re-generate the agent job that runs the article generation and synchronization process. Right click on the Publication in Replication Monitor and select Agent Security and configure the agent to run using a domain service account.
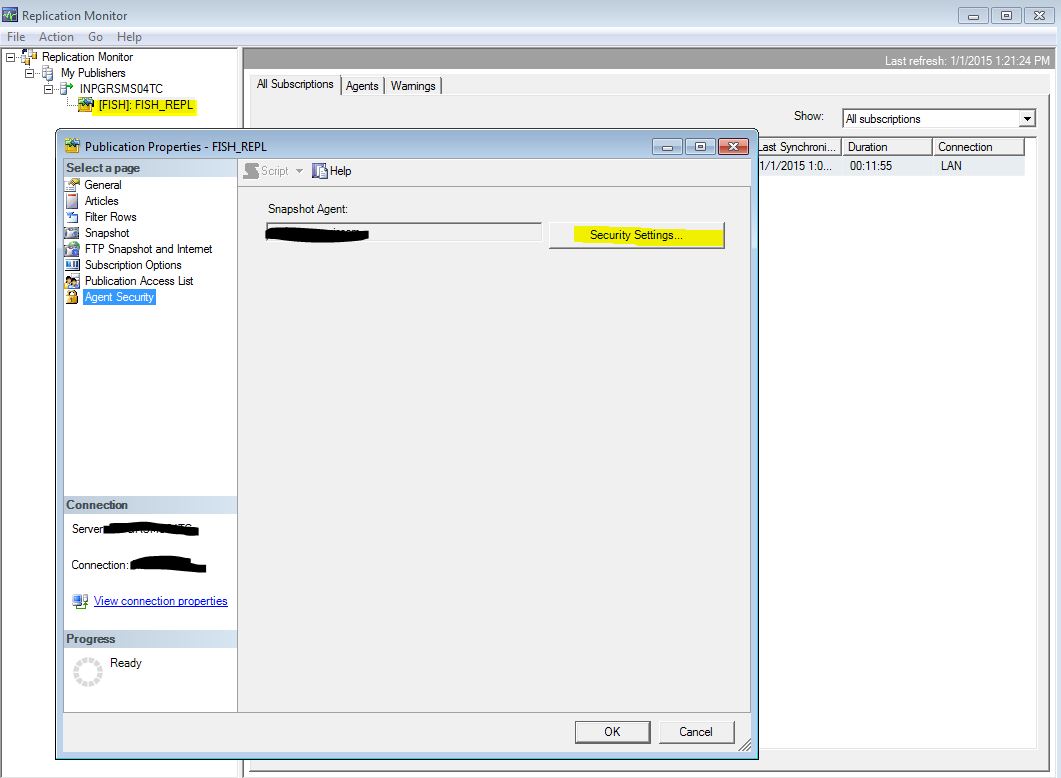
Instead of re-creating the Snapshot Agent you could just:
sp_changemergearticle 'PFMD_REPL', 'TRAILSIGN', 'schema_option','0x000000000C034FD1',1,1 GO sp_changemergearticle 'PFMD_REPL', 'TRAILSIGN', 'stream_blob_columns','false',1,1 GO
And then re-initialize the snapshot.
But it's a good idea to learn how to create the Publication using SQL.
Real-time Geodatabase Replication? Part 1
Real-time Geodatabase Replication? Part 2
Real-time Geodatabase Replication? Part 3
Real-time Geodatabase Replication? Part 4
Real-time Geodatabase Replication? Part 5
Real-time Geodatabase Replication? Part 6
This is a personal blog and does not recommend, endorse, or support the methods described above. Alteration of data using SQL outside of the ESRI software stack, of course, is not supported and should not be applied to a production database without a thorough understanding and disaster recovery plan.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.