- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Enterprise
- :
- High Availability and Disaster Recovery Questions
- :
- GeoEvent and High Availibility
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
GeoEvent and High Availibility
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This would be our Portal and ArcGIS Server high availability deployment.
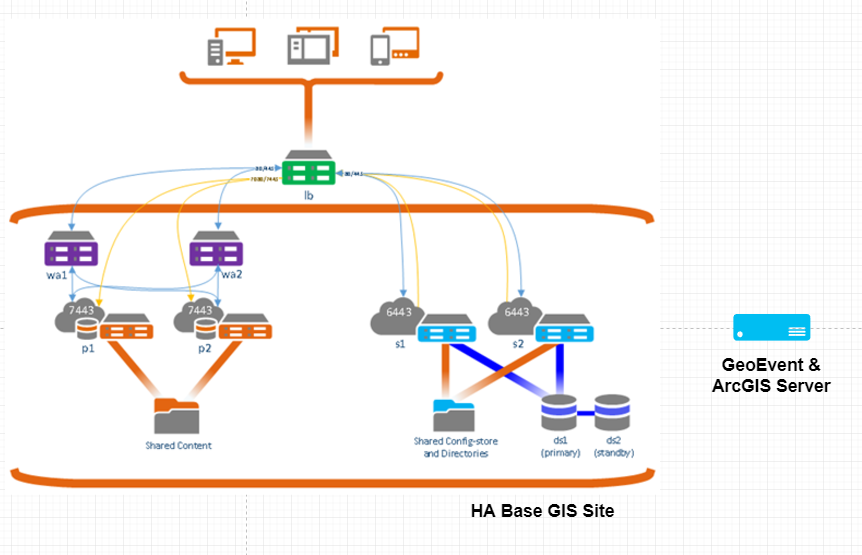
We want to add a HA GeoEvent Server to this architecture. What would be the best solution based on the following limitations/recommendations?
1- Don't use multi-machine sites with GeoEvent
2- Don't install GeoEvent in your base GIS site
If we create two independent GeoEvent site, we should sync them manually? Any better solution?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the useful pointers. The conversation (at 10.6) focuses on SCALABILITY to cope with:
- high message volumes resulting from accumulation from multiple sources
- where the recommendation appears to be to use multiple single-machine sites
- so that different sites can consume messages from different sources
- where the recommendation appears to be to use multiple single-machine sites
- high message volumes from large single sources
- where the recommendation appears to be to use a multiple-machine site (perhaps waiting first for a patch!)
- so that the messages can be load-balanced across machines
- where the recommendation appears to be to use a multiple-machine site (perhaps waiting first for a patch!)
However, what about solution AVAILABILITY, which could manifest as a requirement even when consuming very low message volumes, but where the business criticality of the solution is high?
I assume that this is best met using a multiple-machine site (once patched)? There appears to be a recommendation, however, that multiple-machine sites should have a minimum of 3 GeoEvent Servers. This could feel a bit excessive where message volumes are low. QUESTION 1: Is there a good reason why a multiple-machine site can't just have 2 GeoEvent Servers?
Another caveat with a multiple-machine site appears to be that outputs cannot include Stream Services. As such, there will be a need to store geoevents prior to displaying them in a client, and the client will need to poll a feature service to retrieve them. QUESTION 2: Is that assumption correct?
That then gives rise to the question of whether the spatiotemporal data store (with a potentially higher-cost, multi-node deployment) is overkill for low volume messages. QUESTION 3: Do you have any recommendations as to when to consider deployment of the spatiotemporal data store? (e.g. a threshold level of throughput).
That's probably enough questions for one post... 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello David –
>> However, what about solution AVAILABILITY, which could manifest as a requirement even when consuming very low message volumes, but where the business criticality of the solution is high? I assume that this is best met using a multiple-machine site (once patched)?
Perhaps … there are multiple considerations which is why I recommend folks who are looking at scaling out real-time solutions work with their Esri Technical Advisor or contract with Esri Professional Services for consultation. I’ll try to answer you briefly here however.
Depending on the type of input you are using, a multiple-machine architecture might provide the failover you are looking for. Our testing when using an input which polls an external source for data was very positive. If one machine in a multi-machine site were to go off-line we’ve confirmed that another machine will “adopt” and being running the input so that event ingest doesn’t terminate with the one machine.
If you’re using an input like a JSON REST receiver, or the TCP/Text input, to push data to GeoEvent, then the burden is on the data provider to specify which machine, endpoint, port, (etc.) to push the data to. The challenge here is that there is no built-in way to signal an external data provider that a particular GeoEvent Server instance has gone off-line, so it is difficult to know when to direct data to a different machine or endpoint. In this case a multi-machine setup is probably not going to help; a significant amount of custom development would be required on your part as a solution architect.
I might recommend, for the case where you have low event velocity / volume but message data is critical, that you set up multiple independent GeoEvent Server instances to provide basic redundancy. Process the critical inbound data in parallel across multiple redundant instances and write the resulting feature records out to parallel feature services. The challenge, then, is advising consuming clients when to use the primary feature layer and when to switch to a failover.
Please keep in mind that GeoEvent Server, at a fundamental level, was architected with the assumption that data from sensor networks would be both frequent and periodic. If a reported temperature reading is missed or dropped it’s not a big deal because another will come along from the sensor momentarily.
This assumption is not entirely compatible with stipulations that every event record is critical, neither frequent nor periodic, and data loss cannot be tolerated. If GeoEvent Server receives the data the system will reliability process and disseminate event and feature records. Network stability, datababase failure, feature service availability and recycling … there are many different points at which a system which distributes capability across multiple components might result in a loss of data. System architecture and solution design can address these, but I do not want to take this discussion into one of general “high availability” which often means different things to different customers in different contexts.
>> There appears to be a recommendation, however, that multiple-machine sites should have a minimum of 3 GeoEvent Servers. This could feel a bit excessive where message volumes are low. Is there a good reason why a multiple-machine site can't just have 2 GeoEvent Servers?
Yes, and it has more to do with general computer science principals than anything specific to GeoEvent Server. If two nodes are receiving input and one goes off-line, when it comes back there is no majority or quorum to stipulate that the node coming back on-line is out-of-date. You are left with two peers, each thinking they have the latest state. When you have three (or more) nodes and one fails, upon recovery the other two can establish for the node coming back on-line what “latest” looks like. So, the recommendation for three GeoEvent Server instances is to avoid a “split-brain” condition.
>> Another caveat with a multiple-machine site appears to be that outputs cannot include Stream Services. As such, there will be a need to store geoevents prior to displaying them in a client, and the client will need to poll a feature service to retrieve them. Is that assumption correct?
No, you should be able to leverage stream services in either a single-machine or a multi-machine deployment.
We did find a bug in 10.6 where consumers subscribing to web socket endpoints exposed by machines in a multiple machine deployment would sometimes not receive any feature records. The reason was that the web socket they subscribed to was not actually broadcasting any data. If the client were a web map, for example, a few manual “F5” refresh requests would eventually have the client subscribe via the server instance that actually published the stream service, which was the only one whose web socket was actually broadcasting feature records.
We’ve addressed that issue and the “primary” stream service is now using the message bus to “fan out” and send feature records to the other stream service instances so that a client can subscribe to any machine’s web socket and get all of the feature records processed across the multiple machines – regardless of which machine received an event record and which machine actually processed the event record. This fix will be included in our first patch for the 10.6 release.
>> Do you have any recommendations as to when to consider deployment of the spatiotemporal data store? (e.g. a threshold level of throughput).
To quote an associate, you know you’re dealing with big data when your traditional methods and tools begin to fail. Many folks successfully leverage feature services backed by a traditional relational database (RDBMS) and use the Portal’s hosting server’s managed database to persist their feature records.
Where reliance on an RDBMS begins to fail is when you need to persist more than about 200 events each second. There is a lot of overhead to the REST requests GeoEvent Server has to make on a feature service’s add (or update) feature endpoint to initiate a transaction with a relational data store. Depending on network and database tuning you may discover that transactional latency allows you to persist fewer event records each second. This is the primary reason to consider switching and being using the spatiotemporal big data store.
GeoEvent Server discovers, through Portal and the Portal hosting server, credentials needed to open a socket connection directly to Elasticsearch (the no-SQL database behind the spatiotemporal big data store). Avoiding REST requests means that feature records can be persisted at much higher velocity into the database.
A second reason to consider using the spatiotemporal big data store is that Elasticsearch natively provides data replication across multiple nodes when you establish a data ring by installing ArcGIS Data Store (and selecting the spatiotemporal big data store capability) on multiple machines.
If you include three nodes of the spatiotemporal big data store in your architecture – again, trying to avoid the potential of a split-brain condition – and one of your database server machines were to fail, only one node of the data ring would go off-line. Client requests for data will be redirected to surviving instances. Replicas of your feature records, created automatically and managed by Elasticsearch, will be returned to requesting clients.
Hope this information helps –
RJ
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Josh - I couldn't have asked for a more comprehensive reply!
Just 2 further questions arise from your response:
1/ Is there a scheduled release date (or approximate ETA) for the 10.6 patch?
2/ In a multiple-machine site (minimum 3 nodes), should we expect to have to license each and every node with a GeoEvent Server license? (i.e. pay for 3 licenses)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Actually, I have another...:-)
If you’re using an input like a JSON REST receiver, or the TCP/Text input, to push data to GeoEvent, then the burden is on the data provider to specify which machine, endpoint, port, (etc.) to push the data to.
I take it from this that a multiple-machine site exposes no single endpoint for receipt of an http request (whether POST or GET)? If that's the case, then I guess a suitable load balancer needs to be added up-front which can health-check each machine in order to distribute such requests only to healthy ones? Which could just as easily be done with a suite of single-machine sites, for inputs of this nature, provided no gap detection, geo-fencing or similar is required?
For "guaranteed" receipt, the onus would then just remain on the sender (or middleware) to re-send if no 200 OK response is received from GeoEvent Server?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>> Is there a scheduled release date (or approximate ETA) for the 10.6 patch?
We are working now to determine what will be committed for a 10.6.1 final release, what portion of that will be ported back for 10.6 Patch 1 … and if anything critical must be released as part of the patch which cannot be committed to 10.6.1 (not a configuration we desire, but sometimes have to do).
I would look for 10.6 Patch 1 to be released by UC in July, but it may come out earlier, as soon as 10.6.1 is handed off to the Esri Release Team for final certification and testing.
>> In a multiple-machine site (minimum 3 nodes), should we expect to have to license each and every node with a GeoEvent Server license? (i.e. pay for 3 licenses)
Yes, every deployment / installation of GeoEvent Server must be licensed using (at least) the GeoEvent Server license for that server role. Optionally you can also apply an ArcGIS Server standard / advanced license to the machine you’ve deployed GeoEvent Server, if you want enable the full capability of the ArcGIS Server on that machine – but it is sufficient to license both the ArcGIS Server and GeoEvent Server using a GeoEvent Server license role if you only want the real-time capabilities on that machine.
The same, by the way, is not true for ArcGIS Data Store. With a single ArcGIS Enterprise license you can install ArcGIS Data Store on as many machines as you like, configuring each as a node of the spatiotemporal big data store registered with the Portal’s hosting GIS Server, without having to purchase additional licenses for the instances of ArcGIS Data Store you are deploying.
>> I take it from this that a multiple-machine site exposes no single endpoint for receipt of an http request (whether POST or GET)? If that's the case, then I guess a suitable load balancer needs to be added up-front which can health-check each machine in order to distribute such requests only to healthy ones?
That is correct. Nothing related to the GeoEvent Gateway, GeoEvent Server, or ArcGIS Server components provide a single endpoint (in a multiple-machine architecture) to which a data provider can direct data when actively pushing data to GeoEvent Server. Yes, you can probably configure a load balancer with a “sticky session” to establish affinity with a particular instance of GeoEvent Server, using one of the monitoring endpoints in the GeoEvent Server Admin API to determine if that instance is still available. But I’m not the one to advise you on how to do that – I’ve no experience in that area of system architecture.
>> Which could just as easily be done with a suite of single-machine sites, for inputs of this nature, provided no gap detection, geo-fencing or similar is required?
Yes, as I understand load balancing technology, you could use a LB to route event records to a single-machine “silo’d” instance of GeoEvent Server just as easily as you could an instance participating in a multi-machine configuration. The drawback would be that the single machine instance would not have any peers to which it could further distribute event records for real-time event processing. Also, as you note, if the LB did not guarantee that all tracked assets (those with a given TRACK_ID) were routed to the same machine, real-time analytics like Track Gap Detection, Incident Detection, and spatial operations such as ENTER and EXIT will not work consistently as one machine's "state" (i.e. knowledge of a prior event record) is not propagated or shared between machines in a multi-machine site. Geofencing would work, as long as you had explicitly loaded a consistent set of geofences to each GeoEvent Server instance (in a single-machine "silo'd" configuration).
>> For "guaranteed" receipt, the onus would then just remain on the sender (or middleware) to re-send if no 200 OK response is received from GeoEvent Server?
No, unfortunately that won’t work. An HTTP / 200 response does not imply success in constructing or handling of an event record.
Every inbound connector has two components: an adapter and a transport. It is the transport’s responsibility to receive a payload (think “raw bytes”) and confirm with the data provider that the data was successfully received. That’s all the HTTP / 200 response means.
It is the adapter’s job to reference a schema (e.g. GeoEvent Definition) and construct an event record from the payload provided by its associated transport. That’s why you can configure new connectors to, say, receive JSON over TCP – when out-of-the-box there is only a receive delimited Text over TCP – without writing any code. You are just configuring a new inbound connector paring an out-of-the-box transport with an adapter.
The HTTP / 200 returned from an inbound connector, by its transport, does not mean that the inbound connector’s adapter was successfully able to instantiate an event record for processing, that the event record was successfully processed by a GeoEvent Service (configuration errors in a processor might end up throwing exceptions) or that an output was able to disseminate the event record’s data.
- RJ
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Again RJ, thanks for a very comprehensive reply. (And sorry for calling you Josh before!)
Just one point has confused me a little. In suggesting use of a Load Balancer (LB) to act as a single endpoint for inputs that are actively sent to GeoEvent Server (such as http requests - with input data packaged in a POST / GET), I was imagining that the LB would distribute those requests across machines in a multiple-machine site. As all machines in such a site share the same configuration, any one of them can presumably handle the input?
Your suggestion that a "sticky session" might be required leads me to believe there might be a problem with my original understanding, and makes me wonder what the point would be of having the LB in the first place?
I do appreciate, however, that where stateful processing is required (Track Gap Detection, Incident Detection, and spatial operations such as ENTER and EXIT), use of an LB in this fashion would not be suitable, as multiple-machine sites don't share a track's last-known state across machines.
My summary understanding:
A multiple-machine GeoEvent Server site offers:
- shared configuration (input/output connectors, processors etc) - provided by Zookeeper
- event distribution - provided by Kafka
... but does NOT offer:
- shared track state (a site-level understanding of a track's last-known state)
- a single endpoint to which inputs can actively be sent
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
David Martin - I think your summary / take-away is accurate. A load balancer could be used to simply round-robin event records to available machines because, yes, the inputs on all the machines are configured the same. Doing this may not be optimal as the Kafka event distribution at 10.6 will still attempt to do *its* job and distribute event records with a given TRACK_ID to a single server ... with fail-over to another server only if the primary goes off-line.
To clarify, as long as all machines remain up and running, the fact that "state" is not shared between machines does not matter. Kafka is handling event distribution according to TRACK_ID and is sending event records with a given TRACK_ID to a consistent server. It is only when a machine fails and Kafka has to choose a another machine to process event records with that TRACK_ID that event records previously handled by the machine that failed may produce false positive analytics ... since the secondary machine (which has never seen event records with *these* TRACK_ID values before) has to begin to accumulate a history of the event records it is now receiving.
The point I was trying to make is that -- if you elect to handle event distribution yourself, using a round-robin approach across multiple independent "silo'd" instances -- Track Gap Detection, Incident Detection, and spatial operations such as ENTER and EXIT are not going to work because event records with a given TRACK_ID are not being routed to a consistent machine.
Also, the real purpose of the load balancer is not traditional load balancing. The purpose in this case would be to expose a single receiving endpoint (the URL of the LB) to data providers and obscure (from data providers) the fact that multiple endpoints are available. This potentially provides your solution some resiliency when a given machine fails ... ingest does not come to a screeching halt when data providers continue trying to send data to the failed machine's endpoint(s). Your LB, through a "sticky session", would choose which machine should act as the primary ingest node for a given inbound data stream and fail-over to a secondary machine only if the first machine became unavailable.
- RJ
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Now I get it. I hadn't fully appreciated the extent of the event distribution role that Kafka was performing in allocating events with a common TRACK_ID to an individual server, with failover for resilience. It's presumably a reason to be careful about how (/if?) you populate TRACK_ID on your events, as unless you actually need to maintain track state, it could otherwise reduce the effectiveness of event distribution in a multiple-machine site?
Thank you, rsunderman-esristaff. I couldn't have asked for better support.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi RJ Sunderman
I am interested in continuing the discussion that David Martin started and wondered if there have been any more developments with 10.7 with regards to using a multi-machine single site deployment of GeoEvent Server for stream services?
We would like to deploy a multi-GeoEvent Server machine site to subscribe to a number of JMS endpoints, process the feeds and provide 1+ Stream and feature services to Web clients. Are there any deployment patterns that Esri recommend as we are getting mixed messages from the documentation regarding stream services.
10.6.1 High Availability Tutorial (Page 23): Stream services only run on a single machine.
Thanks
Nick
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Nick -
The reference you highlight, that stream services only run on a single machine, is intended to convey that the JVM used to run GeoEvent Server is the container used to run stream services (unlike traditional map/feature services which have multiple instances and are run by SOC components managed by ArcGIS Server). So the server machine used to publish a stream service is the machine whose GeoEvent Server JVM is running the stream service. However, as I mention above, copies of the Esri Feature JSON records a stream service broadcasts are forwarded to other GeoEvent Server instances in an ArcGIS Server site. This “fan out” allows web clients to subscribe to any machine’s stream service and get all of the feature records processed across a single site, multiple machine solution – regardless of which machine received an event record and which machine actually processed the event record.
A bug (BUG-000114373) with the "fan out" mechanism was addressed with the 10.6.1 release and ported back for release as part of ArcGIS GeoEvent Server 10.6 Patch 2.
The 10.7 release does not include any specific changes that, I think, should influence an system architect to choose a "silo" approach (where multiple independent instances of GeoEvent Server are run, each in their own ArcGIS Server site) vs. a "site" approach whose architecture deploys multiple GeoEvent Server instances configured as part of a single ArcGIS Server site.
If scalability is your primary objective, I would probably recommend the "silo" approach. The solution you architect would need to include an external Apache Kafka (or similar message broker) to handle event record distribution across the multiple independent ArcGIS Server / GeoEvent Server instances. Adopting and maintaining your own Kafka solution introduces its own technical burden, but I think we are finding that, for scalability, this approach lends itself to a system that is easier to maintain and administer overall.
If reliability and fault-tolerance is your primary objective (I really dislike using the term high-availability) then a "site" approach is an option. The solution you architect could deploy multiple ArcGIS Server / GeoEvent Server instances in a single site and rely on the Apache Kafka and Zookeeper built-in to the GeoEvent Gateway to mitigate individual machine failures. But a reliability objective can also be addressed with an an active / active approach using multiple independent instances of GeoEvent Server to build redundancy into a distributed solution for fault-tolerance.
There are advantages to going with the single site, multiple machines approach for resiliency. Specifically when your solution relies on GeoEvent Server polling external web servers / web services for data (which you mentioned), we have observed that the GeoEvent Gateway reliably mitigates the failure of a single node -- which had been the node polling for input -- by allowing another node to "adopt" the input and begin handling the data polling activity.
There are also significant system complexity and administration disadvantages to the "site" approach, which is why I recommend folks who are considering multiple machine, distributed architectures for real-time solutions work with their Esri Technical Advisor or contract with Esri Professional Services for consultation. Only after discussing specific objectives and weighing both the pros and cons can a recommendation be made as to which approach your solution ought to take.
- RJ