- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Data Management Questions
- :
- Script for creating line network intersection poin...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Script for creating line network intersection points
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have created a script for creating line network intersection points. It can process over 120,000 lines to create over 96,000 intersection points in approximately 2 minutes and 15 seconds.
It creates a single unique point feature at any given location no matter how many line From or To ends meet at the point. It uses the provided line name/ID field's values to define a sorted unique list of names/IDs that connect at each point. The point also includes fields for its X and Y coordinates, a concatenation of the X and Y coordinates that uniquely identifies the point location and that can be used as a join field, a field listing a total line count that meets at the intersection point and a list of counts of each name ordered to match the name/ID list order.
Hopefully the code comments are clear and will show you where you can customize the code to fit your preferences. By default the name/ID values that are blank strings or Null value are excluded from the name list and counts, which can make the point where the unnamed line intersects a named line appear to be a pseudo-node. The comment explain how you can change that behavior if you like.
The output points can be used to identify true intersections where two or more different name/ID values meet at a point (any points where the names list field has a closing and opening separator in it or any separator in it if a single character separator is used). It also includes fields that make it possible to identify points where a single line end has no other line connected at that point, which are located at a network boundary, cul-de-sac, stub, inlet, outlet, or dangle topology error (any point where the total lines count field is 1). Finally, it includes fields that make it possible to identify attribute pseudo-nodes where only a single name/ID value occurs where two or more lines join together (any point which has a total lines count greater than 1 and the name list field has no closing and opening separator in it or no separator at all if a single character separator is used). These different classes of points can be selected and exported to create separate point feature classes if you like.
Here is the code:
# ---------------------------------------------------------------------------
# Created on: 2014-09-25
# Author: Richard Fairhurst
# Description: This code is designed to create intersection points, end
# points and/or pseudo-node points based on a name/ID attribute that are
# derived from an input line network. Only line end points are used
# to form intersections, unmatched line ends, or pseudo-nodes.
# High precision topology is typically required to ensure that line ends snap
# together with sufficient accuracy to be connsidered part of the same
# intersection point.
# ---------------------------------------------------------------------------
import arcpy
import os
from arcpy import env
from time import strftime
print "Start script: " + strftime("%Y-%m-%d %H:%M:%S")
# Customize the workspace path to fit your data
env.workspace = r"C:\Users\Owner\Documents\ArcGIS\Centerline_Edit.gdb"
env.overwriteOutput = True
# Customize the name of the field that contains networks line names/IDs
name_field = "STNAME"
# Customize the output field names for the line names list, coordinates,
# concatenated coordinates, total line count, and names count list
names_list_field = "STNAMES"
X_field = "X_COORD"
Y_field = "Y_COORD"
XY_field = "LINK_X_Y"
total_count_field = "WAYS_COUNT"
names_count_list_field = "STNAME_WAYS"
# Customize the separators for concatenated coordinate keys and lists
opening_separator = "{"
closing_separator = "}"
# Customize the input to your feature class, shapefile or layer
inputdata = r"CENTERLINE"
inputfilefull = env.workspace + "\\" + inputdata
# Customize the output feature class or layer to fit your network
outputfile = r"CL_INTERSECTION_POINTS"
outputfilefull = env.workspace + "\\" + outputfile
# Makes a dictionary of unique string coordinate keys from both line ends
# with values in a list holding a dictionary of intersecting names with
# their counts, coordinates, and a total line count
valueDict = {}
with arcpy.da.SearchCursor(inputdata, [name_field, "SHAPE@"]) as searchRows:
for searchRow in searchRows:
name = searchRow[0]
geometry = searchRow[1]
From_X = geometry.firstPoint.X
From_Y = geometry.firstPoint.Y
To_X = geometry.lastPoint.X
To_Y = geometry.lastPoint.Y
# Customize string coordinate keys for the line From and To ends
# For Latitude and Longitude change the formating below to
# "%(OSep1)s%(FY)012.8f%(CSep1)s%(OSep2)s%(FX)012.8f%(CSep2)s" % {'OSep1': opening_separator, 'FY': From_Y, 'CSep1': closing_separator, 'OSep2': opening_separator, 'FX': From_X, 'CSep2': closing_separator}
keyValueFrom = "%(OSep1)s%(FX)012.4f%(CSep1)s%(OSep2)s%(FY)012.4f%(CSep2)s" % {'OSep1': opening_separator, 'FX': From_X, 'CSep1': closing_separator, 'OSep2': opening_separator, 'FY': From_Y, 'CSep2': closing_separator}
keyValueTo = "%(OSep1)s%(TX)012.4f%(CSep1)s%(OSep2)s%(TY)012.4f%(CSep2)s" % {'OSep1': opening_separator, 'TX': To_X, 'CSep1': closing_separator, 'OSep2': opening_separator, 'TY': To_Y, 'CSep2': closing_separator}
# Intersection names normally exclude unnamed and Null name lines
# Optional: If you want unnamed lines to create intersection points
# comment out the next line and dedent the if clause regions below
if name <> " " and name != None:
# add new From coordinate into dictionary
if not keyValueFrom in valueDict:
valueDict[keyValueFrom] = [{}, From_X, From_Y, 1]
valueDict[keyValueFrom][0][name] = 1
# add new name into names dictionary of known From coordinate
elif not name in valueDict[keyValueFrom][0].keys():
valueDict[keyValueFrom][0][name] = 1
valueDict[keyValueFrom][3] += 1
# increment counts when the From coordinate and name are known
else:
valueDict[keyValueFrom][0][name] += 1
valueDict[keyValueFrom][3] += 1
# add new To coordinates into dictionary
if not keyValueTo in valueDict:
valueDict[keyValueTo] = [{}, To_X, To_Y, 1]
valueDict[keyValueTo][0][name] = 1
# add new name into names dictionary of known To coordinate
elif not name in valueDict[keyValueTo][0].keys():
valueDict[keyValueTo][0][name] = 1
valueDict[keyValueTo][3] += 1
# increment counts when the To coordinate and name are known
else:
valueDict[keyValueTo][0][name] += 1
valueDict[keyValueTo][3] += 1
print "Finished dictionary creation: " + strftime("%Y-%m-%d %H:%M:%S")
# Determine if the outputfilefull exists already
if arcpy.Exists(outputfilefull):
# Process: Delete outputfilefull...
arcpy.Delete_management(outputfilefull, "FeatureClass")
# Process: Create Point Feature Class and use the input spatial reference...
arcpy.CreateFeatureclass_management(env.workspace, outputfile, "POINT", "", "DISABLED", "DISABLED", inputfilefull, "", "0", "0", "0")
# Process: Add names_list_field Field (customize the field length if you need to)...
arcpy.AddField_management(outputfilefull, names_list_field, "TEXT", "", "", "150", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add X_field Field...
arcpy.AddField_management(outputfilefull, X_field, "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Y_field Field...
arcpy.AddField_management(outputfilefull, Y_field, "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add XY_field Field (customize the field length if you need to)...
arcpy.AddField_management(outputfilefull, XY_field, "TEXT", "", "", "28", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add total_count_field Field...
arcpy.AddField_management(outputfilefull, total_count_field, "LONG", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add names_count_list_field Field (customize the field length if you need to)...
arcpy.AddField_management(outputfilefull, names_count_list_field, "TEXT", "", "", "20", "", "NULLABLE", "NON_REQUIRED", "")
print "Finished feature class creation: " + strftime("%Y-%m-%d %H:%M:%S")
# Create an insert cursor for a table specifying the fields that will
# have values provided
fields = [names_list_field, X_field, Y_field, XY_field, total_count_field, names_count_list_field, 'SHAPE@XY']
insertcursor = arcpy.da.InsertCursor(outputfilefull, fields)
# sort the string coordinate keys and process their values
for keyValue in sorted(valueDict.keys()):
# create a list of names and their counts with separator characters
# reset variables to hold new lists of names and their counts
names = ""
counts = ""
# sort the names dictionary and create the names and counts lists
for name in sorted(valueDict[keyValue][0].keys()):
if name == "":
# Optional: Change separator configuration
names = opening_separator + name + closing_separator
counts = opening_separator + str(valueDict[keyValue][0][name]) + closing_separator
else:
# Optional: Change separator configuration
names = names + opening_separator + name + closing_separator
counts = counts + opening_separator + str(valueDict[keyValue][0][name]) + closing_separator
row = (names, valueDict[keyValue][1], valueDict[keyValue][2], keyValue, valueDict[keyValue][3], counts, (valueDict[keyValue][1], valueDict[keyValue][2]))
insertcursor.insertRow(row)
# create output feature classes/shapefiles
# two names separated by "}{" are a real intersection
# if closing_separator + opening_separator in names:
# write to text file
# f.write('"' + names + '",' + str(valueDict[keyValue][1]) + ',' + str(valueDict[keyValue][2]) + ',"' + keyValue + '",' + str(valueDict[keyValue][3]) + ',"' + counts + '"\n' )
# one name with a total line count of 1 is an unmatched line end, which
# may be a stub, a cul-de-sac, or a topology error for a road network
# one name with a total line count > 1 is a pseudo node for the name
print "Finished inserting rows: " + strftime("%Y-%m-%d %H:%M:%S")
Here is a picture of what the field data looks like for the code as written:
| OBJECTID * | Shape * | STNAMES | X_COORD | Y_COORD | LINK_X_Y | WAYS_COUNT | STNAME_WAYS |
| 50676 | Point | {MADRONO CT} | 6296418.904414 | 2243614.433358 | {6296418.9044}{2243614.4334} | 1 | {1} |
| 50867 | Point | {10TH ST} | 6297064.90509 | 2243667.729839 | {6297064.9051}{2243667.7298} | 2 | {2} |
| 50889 | Point | {10TH ST}{WOLFSKILL AVE} | 6297145.870479 | 2243668.425376 | {6297145.8705}{2243668.4254} | 2 | {1}{1} |
| 50997 | Point | {BELL AVE}{WOLFSKILL AVE} | 6297360.565588 | 2243670.268876 | {6297360.5656}{2243670.2689} | 3 | {1}{2} |
| 51160 | Point | {MAGNOLIA AVE}{WOLFSKILL AVE} | 6297781.153002 | 2243671.327601 | {6297781.1530}{2243671.3276} | 4 | {2}{2} |
| 51407 | Point | {HANSEN AVE}{WOLFSKILL AVE} | 6298405.94145 | 2243672.728517 | {6298405.9415}{2243672.7285} | 4 | {2}{2} |
| 51724 | Point | {6TH ST}{WOLFSKILL AVE} | 6299040.417543 | 2243674.151414 | {6299040.4175}{2243674.1514} | 4 | {2}{2} |
| 52871 | Point | {5TH ST}{WOLFSKILL AVE} | 6301563.821945 | 2243679.94635 | {6301563.8219}{2243679.9464} | 4 | {2}{2} |
| 53020 | Point | {MIKE LN}{WOLFSKILL AVE} | 6301904.892129 | 2243680.73211 | {6301904.8921}{2243680.7321} | 3 | {1}{2} |
| 53164 | Point | {HAVENHURST DR}{WOLFSKILL AVE} | 6302189.418463 | 2243681.387948 | {6302189.4185}{2243681.3879} | 3 | {1}{2} |
| 53355 | Point | {WOLFSKILL AVE} | 6302528.110371 | 2243682.16813 | {6302528.1104}{2243682.1681} | 2 | {2} |
| 53469 | Point | {BLUEBONNET RD}{WOLFSKILL AVE} | 6302822.667853 | 2243682.846935 | {6302822.6679}{2243682.8469} | 3 | {1}{2} |
| 53637 | Point | {POPPY RD}{WOLFSKILL AVE} | 6303293.806346 | 2243683.932563 | {6303293.8063}{2243683.9326} | 3 | {1}{2} |
| 53810 | Point | {4TH ST}{CORSO ALTO AVE}{WOLFSKILL AVE} | 6303774.846395 | 2243684.940106 | {6303774.8464}{2243684.9401} | 3 | {1}{1}{1} |
| 50553 | Point | {MADRONO CT}{YUCCA AVE} | 6295970.886609 | 2243832.745913 | {6295970.8866}{2243832.7459} | 3 | {1}{2} |
| 50586 | Point | {10TH ST}{YUCCA AVE} | 6296116.882052 | 2244123.025844 | {6296116.8821}{2244123.0258} | 4 | {2}{2} |
| 50779 | Point | {WILDFIRE CIR} | 6296733.251882 | 2244238.88388 | {6296733.2519}{2244238.8839} | 1 | {1} |
| 50638 | Point | {WILDFIRE CIR}{YUCCA AVE} | 6296284.789853 | 2244458.484163 | {6296284.7899}{2244458.4842} | 4 | {2}{2} |
| 50332 | Point | {10TH ST}{ARMANDO DR} | 6295320.524393 | 2244504.723572 | {6295320.5244}{2244504.7236} | 3 | {2}{1} |
| 50534 | Point | {WILDFIRE CIR} | 6295917.833565 | 2244566.072531 | {6295917.8336}{2244566.0725} | 1 | {1} |
| 53872 | Point | {YUCCA AVE} | 6303868.692664 | 2244646.38405 | {6303868.6927}{2244646.3840} | 2 | {2} |
| 53854 | Point | {4TH ST}{YUCCA AVE} | 6303843.885627 | 2244649.336472 | {6303843.8856}{2244649.3365} | 4 | {2}{2} |
| 50223 | Point | {10TH ST}{LAKEVIEW AVE} | 6294916.12986 | 2244698.551596 | {6294916.1299}{2244698.5516} | 4 | {2}{2} |
| 53027 | Point | {MIKE LN} | 6301917.13784 | 2244702.955131 | {6301917.1378}{2244702.9551} | 1 | {1} |
| 50855 | Point | {DEBBIE LN} | 6297012.336626 | 2244807.570407 | {6297012.3366}{2244807.5704} | 1 | {1} |
| 50737 | Point | {DEBBIE LN}{WOLFGRAM DR}{YUCCA AVE} | 6296566.133122 | 2245018.051942 | {6296566.1331}{2245018.0519} | 4 | {1}{1}{2} |
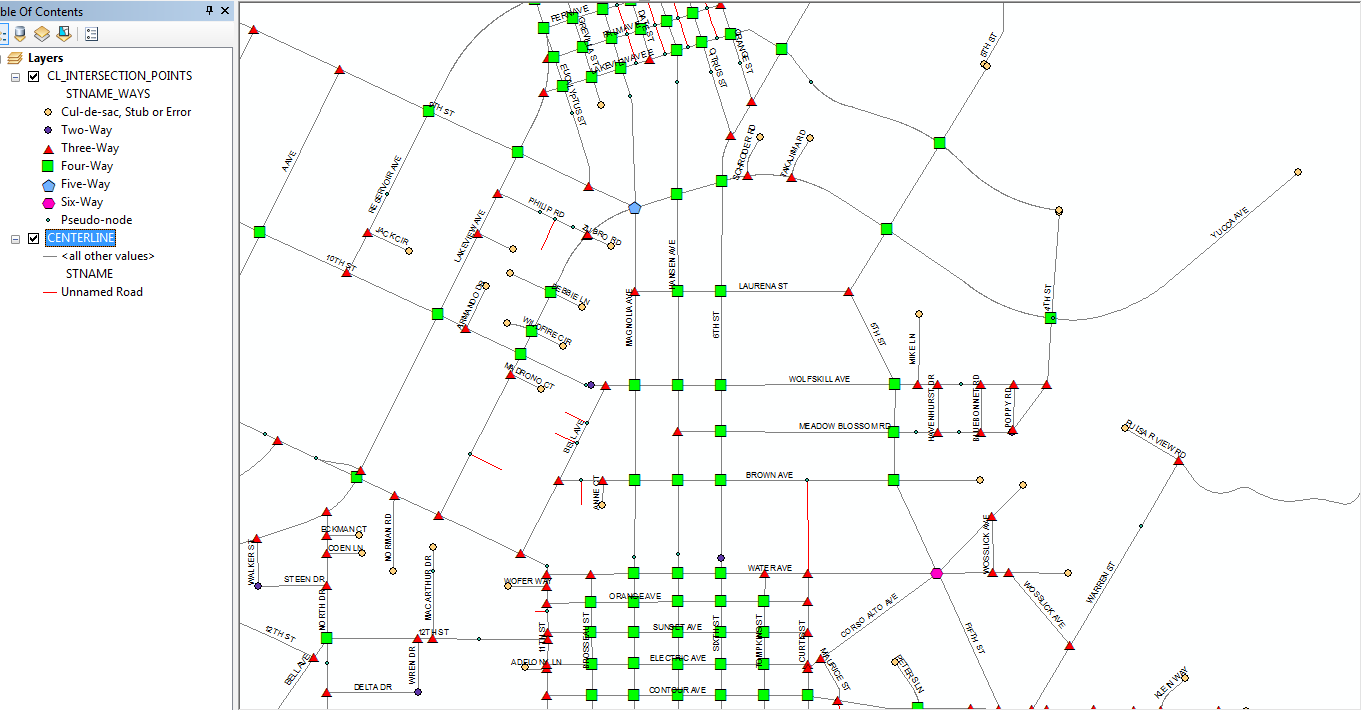
Here is a picture of one of the ways this data can displayed:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The following changes should be made to the code above, which improves the handling of whitespace/Null name inclusion or exclusion from the name list and which makes the code work whether the name variable value you provide is a numeric ID value or a string name value. The name variable is used to create in the list of values the determines whether the point is a true intersection for that attribute (2 or more different values are listed for a point) or a pseudo-node for that attribute (only 1 value is listed for a point):
I added a new boolean variable called allowWhitespace that by default is set to False. A value of False for this variable will exclude whitespace and Null name values and a value of True will include whitespace or Null name values.
as a result lines 77 through 80 should now read:
# Set allowWhitespace to True to include whitespace or Null names
if allowWhitespace or (len(str(name).strip()) <> 0 and name != None):
In order to accommodate a single character list separator if you prefer to make that modification, lines 159 through 166 should read:
if names == "":
# Optional: Change separator configuration
names = opening_separator + str(name) + closing_separator
counts = opening_separator + str(valueDict[keyValue][0][name]) + closing_separator
else:
# Optional: Change separator configuration
names = names + opening_separator + str(name) + closing_separator
counts = counts + opening_separator + str(valueDict[keyValue][0][name]) + closing_separator
I revised the import code to immediately report the time the script starts and to eliminate the import of os. I also changed the double spaced blank newlines to single spaced blank newlines to reduce the overall number of lines of code and make it more compact. My latest script runs on my 120,000+ polyline test data now consistently take just under two minutes to complete.
Here is the entire revised code:
# ---------------------------------------------------------------------------
# Created on: 2014-09-25
# Modified on: 2014-09-26
# Author: Richard Fairhurst
# Description: This code is designed to create intersection points, end
# points and/or pseudo-node points based on a name/ID attribute that are
# derived from an input line network. Only line end points are used
# to form intersections, unmatched line ends, or pseudo-nodes.
# High precision topology is typically required to ensure that line ends snap
# together with sufficient accuracy to be considered part of the same
# intersection point.
# ---------------------------------------------------------------------------
from time import strftime
print "Start script: " + strftime("%Y-%m-%d %H:%M:%S")
import arcpy
from arcpy import env
# Customize the workspace path to fit your data
env.workspace = r"C:\Users\Owner\Documents\ArcGIS\Centerline_Edit.gdb"
# Customize the allowWhitespace variable to False to not allow and True
# to allow whitespace or Null names/IDs to be included in the list of
# names/IDs that define the intersection.
allowWhitespace = False
# Customize the name of the field that contains networks line names/IDs
name_field = "STNAME"
# Customize the output field names for the line names list, coordinates,
# concatenated coordinates, total line count, and names count list
names_list_field = "STNAMES"
X_field = "X_COORD"
Y_field = "Y_COORD"
XY_field = "LINK_X_Y"
total_count_field = "WAYS_COUNT"
names_count_list_field = "STNAME_WAYS"
point_type_field = "POINT_TYPE"
# Customize the separators for concatenated coordinate keys and lists
opening_separator = "{"
closing_separator = "}"
# Customize the input to your feature class, shapefile or layer
inputdata = r"CENTERLINE"
inputfilefull = env.workspace + "\\" + inputdata
# Customize the output feature class or layer to fit your network
outputfile = r"CL_INTERSECTION_POINTS"
outputfilefull = env.workspace + "\\" + outputfile
# Makes a dictionary of unique string coordinate keys from both line ends
# with values in a list holding a dictionary of intersecting names with
# their counts, coordinates, and a total line count
valueDict = {}
with arcpy.da.SearchCursor(inputdata, [name_field, "SHAPE@"]) as searchRows:
for searchRow in searchRows:
name = searchRow[0]
geometry = searchRow[1]
From_X = geometry.firstPoint.X
From_Y = geometry.firstPoint.Y
To_X = geometry.lastPoint.X
To_Y = geometry.lastPoint.Y
# Customize string coordinate keys for the line From and To ends
# For Latitude and Longitude change the formating below to
# "%(OSep1)s%(FY)012.8f%(CSep1)s%(OSep2)s%(FX)012.8f%(CSep2)s" % {'OSep1': opening_separator, 'FY': From_Y, 'CSep1': closing_separator, 'OSep2': opening_separator, 'FX': From_X, 'CSep2': closing_separator}
keyValueFrom = "%(OSep1)s%(FX)012.4f%(CSep1)s%(OSep2)s%(FY)012.4f%(CSep2)s" % {'OSep1': opening_separator, 'FX': From_X, 'CSep1': closing_separator, 'OSep2': opening_separator, 'FY': From_Y, 'CSep2': closing_separator}
keyValueTo = "%(OSep1)s%(TX)012.4f%(CSep1)s%(OSep2)s%(TY)012.4f%(CSep2)s" % {'OSep1': opening_separator, 'TX': To_X, 'CSep1': closing_separator, 'OSep2': opening_separator, 'TY': To_Y, 'CSep2': closing_separator}
# Set allowWhitespace to True to include whitespace or Null names
if allowWhitespace or (len(str(name).strip()) <> 0 and name != None):
# add new From coordinate into dictionary
if not keyValueFrom in valueDict:
valueDict[keyValueFrom] = [{}, From_X, From_Y, 1]
valueDict[keyValueFrom][0][name] = 1
# add new name into names dictionary of known From coordinate
elif not name in valueDict[keyValueFrom][0].keys():
valueDict[keyValueFrom][0][name] = 1
valueDict[keyValueFrom][3] += 1
# increment counts when the From coordinate and name are known
else:
valueDict[keyValueFrom][0][name] += 1
valueDict[keyValueFrom][3] += 1
# add new To coordinates into dictionary
if not keyValueTo in valueDict:
valueDict[keyValueTo] = [{}, To_X, To_Y, 1]
valueDict[keyValueTo][0][name] = 1
# add new name into names dictionary of known To coordinate
elif not name in valueDict[keyValueTo][0].keys():
valueDict[keyValueTo][0][name] = 1
valueDict[keyValueTo][3] += 1
# increment counts when the To coordinate and name are known
else:
valueDict[keyValueTo][0][name] += 1
valueDict[keyValueTo][3] += 1
print "Finished dictionary creation: " + strftime("%Y-%m-%d %H:%M:%S")
# Determine if the outputfilefull exists already
if arcpy.Exists(outputfilefull):
# Process: Delete outputfilefull...
arcpy.Delete_management(outputfilefull, "FeatureClass")
# Process: Create Feature Class...
arcpy.CreateFeatureclass_management(env.workspace, outputfile, "POINT", "", "DISABLED", "DISABLED", inputfilefull, "", "0", "0", "0")
# Process: Add names_list_field Field...
arcpy.AddField_management(outputfilefull, names_list_field, "TEXT", "150", "", "150", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add X_field Field...
arcpy.AddField_management(outputfilefull, X_field, "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add Y_field Field...
arcpy.AddField_management(outputfilefull, Y_field, "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add XY_field Field...
arcpy.AddField_management(outputfilefull, XY_field, "TEXT", "", "", "28", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add total_count_field Field...
arcpy.AddField_management(outputfilefull, total_count_field, "LONG", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add names_count_list_field Field...
arcpy.AddField_management(outputfilefull, names_count_list_field, "TEXT", "", "", "20", "", "NULLABLE", "NON_REQUIRED", "")
# Process: Add names_count_list_field Field...
arcpy.AddField_management(outputfilefull, point_type_field, "TEXT", "", "", "22", "", "NULLABLE", "NON_REQUIRED", "")
print "Finished feature class creation: " + strftime("%Y-%m-%d %H:%M:%S")
# Create an insert cursor for a table specifying the fields that will
# have values provided
fields = [names_list_field, X_field, Y_field, XY_field, total_count_field, names_count_list_field, point_type_field, 'SHAPE@XY']
insertcursor = arcpy.da.InsertCursor(outputfilefull, fields)
# sort the string coordinate keys and process their values
for keyValue in sorted(valueDict.keys()):
# create a list of names and their counts with separator characters
# reset variables to hold new lists of names and their counts
names = ""
counts = ""
point_type = ""
# sort the names dictionary and create the names and counts lists
for name in sorted(valueDict[keyValue][0].keys()):
if names == "":
# Optional: Change separator configuration
names = opening_separator + str(name) + closing_separator
counts = opening_separator + str(valueDict[keyValue][0][name]) + closing_separator
else:
# Optional: Change separator configuration
names = names + opening_separator + str(name) + closing_separator
counts = counts + opening_separator + str(valueDict[keyValue][0][name]) + closing_separator
if closing_separator + opening_separator in names:
point_type = "True Intersection"
elif counts == opening_separator + '1' + closing_separator:
point_type = "Single-Line End Point"
elif counts == opening_separator + '2' + closing_separator:
point_type = "Pseudo Node"
else:
point_type = "Branching Lines"
row = (names, valueDict[keyValue][1], valueDict[keyValue][2], keyValue, valueDict[keyValue][3], counts, point_type, (valueDict[keyValue][1], valueDict[keyValue][2]))
insertcursor.insertRow(row)
del insertcursor
print "Finished inserting rows: " + strftime("%Y-%m-%d %H:%M:%S")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Richard,
Once you've generated the intersections, what do you use them for?
Thanks,
Jon.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am in transportation and intersections define all of my reference points. This is the way all of my users understand the road network and makes human centric interfaces possible. My County DOT never uses mileposts on the roads we maintain, so positions that are defined relative to intersections are the most reliable way we have of describing features on our road network. Collision reports from the state also use intersection descriptions and offsets to define accident locations.
The fields I create make it possible to select or filter intersections based on their most common characteristics using standard SQL expressions. Examine the map picture in my first post more closely and you will see that I have correctly symbolized the different intersection configurations (3-way, 4-way, etc.) with symbols that emphasize those characteristics (triangles for 3-way, squares for 4-way, pentagons for 5-way, etc. each with a distinct color).
These intersection points and the ability to use SQL with these fields have allowed me to design applications that let a user find and zoom to any intersection (correctly spelled, which is crucial to our operations). By applying linear referencing tools to these intersection points I am able to create segments of road between two intersections a user selects or based on offsets from one or more intersections using a compass direction and distance provided by a user. Road segments are the basis of all the money we get for gas tax or that we spend on capital improvements.
The intersection count fields help me quickly see and identify topology errors (which often are invisible if you just look at at the lines) or unwanted name changes and name branching, which results in bad linear referenced routes. The sorted name listing and associated counts also help me find unwanted variant name misspellings where two lines connect. (i.e., 6TH ST and SIXTH ST). With a bit of SQL I can easily select and locate the name variants that should not exist where roads intersect.
Intersections typically also define block limits for addressing and being able to easily identify actual intersections and their cross-roads is useful for assigning the well defined address range break positions. I can use SQL or a sorted table view to choose the cross-street names that define an addressed block and zoom to the limits of the set of lines that fall between those two points, even if there are many lines that make up that block.
As a derivative of these intersections I also create a linear referenced event table that lists every pair of street names in every possible order at each real intersection location. This event table makes it possible to sort the rows by cross streets for each individual road in their alphabetical or drivable order. This table makes it even easier to find unwanted name variants or to match user data to the network and to create the road segments I mentioned. Without this initial set of points that event table cannot be created. As a follow up I will be redesigning my code to derive that event table based on the coding techniques I have used in this post.
Intersections provide fundamental data that is essential to understanding and using a line network in my experience.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Richard Fairhurst this is great. Thanks for sharing!
I am working on a very similar workflow. I was able to use this example and then parse the results using SQL so that the py script results are separated into new rows:
Py Results:
Intersection_ID = 1, FULLNAME = {First Ave}{Main St}
Intersection_ID = 2, FULLNAME = {Second Ave}{Main St}
SQL Result:
1 First Ave
1 Main St
2 Second Ave
2 Main St
Any ideas on how to do this purely in Python?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am not sure I understand what you are doing with the SQL. Is the SQL result representing a concatenated field, or two separate fields? Is it showing something like a Calculated field in Access?
As far as the Python processing are you wanting separate points for each single street name paired with the intersection ID value? So if 3 names meet at the intersection you would want 3 points? Is it OK if FULLNAME continues to contain the names in brackets and the single name goes in a new separate field or do you want to drop the names in brackets? If you dropped the bracketed names how would you select the "Main St" intersection at "Second Ave"?
As I mentioned, I create a derivative of the output of this script to show all intersection pair names in all orders. So 12 points get created if there are 4 names that meet at an intersection, with each of the 4 unbracketed names being used as a primary street name and paired with each of the other 3 unbracketed names in a cross street field. The pair of names is also kept as a bracketed pair for joins so that all possible name pairings in all possible orders have a join field.
However, my script that extracts the name pairs points is not a standalone script. It is part of an integrated weekly update script specific to my data. To separate out the code that creates the derivative output and make it more generic for anyone to adapt to their own data would take more time and effort than I can give to it right now.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for the quick reply.
The SQL is parsed into separate columns. See below.
As far as the Python processing are you wanting separate points for each single street name paired with the intersection ID value? So if 3 names meet at the intersection you would want 3 points? Is it OK if FULLNAME continues to contain the names in brackets and the single name goes in a new separate field or do you want to drop the names in brackets? If you dropped the bracketed names how would you select the "Main St" intersection at "Second Ave"?
Almost. I load the results of the Python script into Oracle and then run the query below. Using the OBJECTID as the key to yield a new row for each street that intersects using the braces as a delimiter.
SELECT
t.COUNTYFP COUNTY_FIPS
,upper(t.COUNTYNAME) COUNTY_NAME
, upper(t.COUSUBFP) MUNICIPALITY_FIPS
, upper(t.MUNINAME) MUNICIPALITY_NAME
, t.placefp PLACE_FIPS
, upper(t.PLACENAME) PLACE_NAME
, t.OBJECTID INTERSECTION_ID
, t.EQUIPMENT_ID XFMR_ID
, t.NEAR_DIST DISTANCE_FT
, upper(trim(regexp_substr(t.FULLNAME, '[^}{]+', 1, lines.column_value))) FULLNAME
, t.POINT_X
, t.POINT_Y
FROM TIGER_20150622155219 t,
TABLE (CAST (MULTISET
(SELECT LEVEL FROM dual CONNECT BY regexp_substr(t.FULLNAME , '[^}{]+', 1, LEVEL) IS NOT NULL)
AS sys.odciNumberList
)
) lines
ORDER BY t.OBJECTID;sample results:
| INTERSECTION_ID | FULLNAME |
|---|---|
| 1 | CO RD 1 |
| 1 | COUNCIL HILL RD (WEST) |
| 2 | BALES RD |
| 2 | STATE LINE RD |
| 2 | VETA GRANDE RD (WEST) |
As I mentioned, I create a derivative of the output of this script to show all intersection pair names in all orders. So 12 points get created if there are 4 names that meet at an intersection, with each of the 4 unbracketed names being a used as a primary street name and paired with each of the other 3 unbracketed names in a cross street field.
Ultimately, this is exactly what I'm trying to do. I completely understand about the level of effort though.
My initial thought was to translate the above SQL functionality into Python, but that is currently beyond my depth.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Well, just to give you the idea of what I do I am pasting my actual script code that occurs after the Intersections are created based on a script similar to the one I posted here. The script assumes a template feature class (CL_INTERSECTIONS_PAIRS_Full) exists that holds all of the fields inserted for the CL_INTERSECTIONS_Cross1. Those fields are in the first fields list (["RID", "MEAS", "Distance", "STNAMES", "X_COORD", "Y_COORD", "X_Y_LINK", "WAYS_COUNT", "STNAME_WAYS", "POINT_ID", "STNAME", "X_Y_STNAME", "X_Y_ROUTE", "MAINT_TYPE", "IS_MAINTAINED", "CROSS_STREET", "X_Y_CROSS", "CROSS_MAINT_TYPE", "CROSS_IS_MAINTAINED", "PAIR_STNAMES", "X_Y_PAIRS", "RDNUMBER", "CROSS_RDNUMBER", "INT_CLARIFY", "INT_SPREAD", "GOOGLE_URL", "SEQUENCE"]).
As I said, this code is not generic, so it is will not be easily adapted to other data configurations. Not all of the fields I create for intersection points in my personal script are included in the script I posted here. My script is actually creating a Linear Referencing event table so it derives the M coordinates of the points against a set of routes derived from my centerlines in a previous part of the script. Also, although your output has FULLNAME with bracketed names, my output just has a normal single street name in that field. STNAMES is the field in my data with the bracketed set of street names that meet at the intersection.
This is only intended to convey the idea of what can be done to manipulate the intersection data with python cursors and dictionaries.
import time
from time import strftime
start_time = time.time()
last_time = start_time
import logging
logging.basicConfig(filename=r"\\agency\agencydfs\Tran\Files\GISData\rfairhur\Python Scripts\Centerline_Derivatives_Update_New.log",level=logging.DEBUG)
print "Start script: " + strftime("%Y-%m-%d %H:%M:%S")
logging.info(" ****Start script: " + strftime("%Y-%m-%d %H:%M:%S") + "****")
# Set the necessary product code
import arcinfo
import sys, string, os, arcpy, numpy
from arcpy import env
import datetime
import math
def hms_string(sec_elapsed):
h = int(sec_elapsed / (60 * 60))
m = int((sec_elapsed % (60 * 60)) / 60)
s = sec_elapsed % 60.
return "{}:{:>02}:{:>05.2f}".format(h, m, s)
# End hms_string
def print_times(event, last, start):
current_time = time.time()
print ""
print "{} took {} to execute".format(event, hms_string(current_time - last))
print "{} - Total script run time is {}".format(strftime("%Y-%m-%d %H:%M:%S"), hms_string(current_time - start))
logging.info("")
logging.info(" {} took {} to execute".format(event, hms_string(current_time - last)))
logging.info(" {} - Total script run time is {}".format(strftime("%Y-%m-%d %H:%M:%S"), hms_string(current_time - start)))
return current_time
last_time = print_times("Imports Loaded", last_time, start_time)
env.workspace = r"\\agency\agencydfs\Tran\Files\GISData\rfairhur\Layers\Centerline_Synch.gdb"
Trans_Connection = r"Database Connections\Trans Connection to SQL Server.sde"
TRANS_MAINT = Trans_Connection + r"\GDB_TRANS.TRANS.TRANSPORTATION_MAINT"
Centerline_Synch_gdb = r"\\agency\agencydfs\Tran\Files\GISData\rfairhur\Layers\Centerline_Synch.gdb"
CL_Maint = Centerline_Synch_gdb + r"\CL_Maint"
# Customize the point_ID to fit your network
CL_INTERSECTION_POINTS_IDS = r"CL_INTERSECTION_POINTS_IDS"
CL_INTERSECTION_POINTS_IDS_Full = env.workspace + "\\" + CL_INTERSECTION_POINTS_IDS
CENTERLINE_ROUTES_APPEND = "CENTERLINE_ROUTES_APPEND"
CENTERLINE_ROUTES_APPEND_Full = CL_Maint + "\\" + CENTERLINE_ROUTES_APPEND
CENTERLINE_ROUTES_MERGED_OLD = "CENTERLINE_ROUTES_MERGED_OLD"
CENTERLINE_ROUTES_MERGED_OLD_Full = CL_Maint + "\\" + CENTERLINE_ROUTES_MERGED_OLD
CENTERLINE_ROUTES_MERGED = "CENTERLINE_ROUTES_MERGED"
CENTERLINE_ROUTES_MERGED_Full = CL_Maint + "\\" + CENTERLINE_ROUTES_MERGED
CENTERLINE_ROUTES_MERGED_Layer = "CENTERLINE_ROUTES_MERGED_Layer"
# Customize the old feature class as a backup to fit your network
CL_INTERSECTION_POINTS_OLD = "CL_INTERSECTION_POINTS_OLD"
CL_INTERSECTION_POINTS_OLD_Full = CL_Maint + "\\" + CL_INTERSECTION_POINTS_OLD
# Customize the output feature class or layer to fit your network
CL_INTERSECTION_POINTS = r"CL_INTERSECTION_POINTS"
CL_INTERSECTION_POINTS_Full = CL_Maint + "\\" + CL_INTERSECTION_POINTS
CL_INTERSECTION_POINTS_Layer = "CL_INTERSECTION_POINTS_Layer"
# Customize the point_ID to fit your network
CL_INTERSECTION_POINTS_IDS = r"CL_INTERSECTION_POINTS_IDS"
CL_INTERSECTION_POINTS_IDS_Full = env.workspace + "\\" + CL_INTERSECTION_POINTS_IDS
# Customize the Intersections to fit your network
CENTERLINE_INTERSECTIONS_OLD = r"CENTERLINE_INTERSECTIONS_OLD"
CENTERLINE_INTERSECTIONS_OLD_Full = CL_Maint + "\\" + CENTERLINE_INTERSECTIONS_OLD
# Customize the Intersections to fit your network
CENTERLINE_INTERSECTIONS = r"CENTERLINE_INTERSECTIONS"
CENTERLINE_INTERSECTIONS_Full = CL_Maint + "\\" + CENTERLINE_INTERSECTIONS
CENTERLINE_CULS_STUBS_OLD = r"CENTERLINE_CULS_STUBS_OLD"
CENTERLINE_CULS_STUBS_OLD_Full = CL_Maint + "\\" + CENTERLINE_CULS_STUBS_OLD
CENTERLINE_CULS_STUBS = r"CENTERLINE_CULS_STUBS"
CENTERLINE_CULS_STUBS_Full = CL_Maint + "\\" + CENTERLINE_CULS_STUBS
CENTERLINE_CULS_STUBS_Layer = "CENTERLINE_CULS_STUBS_Layer"
CL_MAINT_TYPE = "CL_MAINT_TYPE"
CL_MAINT_TYPE_Full = Centerline_Synch_gdb + "\\" + CL_MAINT_TYPE
CL_INTERSECTIONS_Cross1 = "CL_INTERSECTIONS_Cross1"
CL_INTERSECTIONS_Cross1_Full = Centerline_Synch_gdb + "\\" + CL_INTERSECTIONS_Cross1
CL_INTERSECTIONS_Cross1_View = "CL_INTERSECTIONS_Cross1_View"
Route_Event_Table_Properties = "RID POINT MEAS"
CL_INTERSECTIONS_PAIRS_OLD = "CL_INTERSECTIONS_PAIRS_OLD"
CL_INTERSECTIONS_PAIRS_OLD_Full = Centerline_Synch_gdb + "\\" + CL_INTERSECTIONS_PAIRS_OLD
CL_INTERSECTIONS_PAIRS = "CL_INTERSECTIONS_PAIRS"
CL_INTERSECTIONS_PAIRS_Full = Centerline_Synch_gdb + "\\" + CL_INTERSECTIONS_PAIRS
CL_INTERSECTIONS_PAIRS_View = "CL_INTERSECTIONS_PAIRS_View"
Try:
arcpy.CreateTable_management(Centerline_Synch_gdb, CL_INTERSECTIONS_Cross1, CL_INTERSECTIONS_PAIRS_Full)
last_time = print_times("Created CL_INTERSECTIONS_Cross1", last_time, start_time)
fields = ["RID", "MEAS", "Distance", "STNAMES", "X_COORD", "Y_COORD", "X_Y_LINK", "WAYS_COUNT", "STNAME_WAYS", "POINT_ID", "STNAME", "X_Y_STNAME", "X_Y_ROUTE", "MAINT_TYPE", "IS_MAINTAINED", "CROSS_STREET", "X_Y_CROSS", "CROSS_MAINT_TYPE", "CROSS_IS_MAINTAINED", "PAIR_STNAMES", "X_Y_PAIRS", "RDNUMBER", "CROSS_RDNUMBER", "INT_CLARIFY", "INT_SPREAD", "GOOGLE_URL", "SEQUENCE"]
insertcursor = arcpy.da.InsertCursor(CL_INTERSECTIONS_Cross1_Full, fields)
insertList = []
print ""
print str(len(pointRouteMDict.keys()))
count = 0
for street in pointIDDict.keys():
count += 1
if not street in pointRouteMDict:
print street + " has no Point and no Route"
else:
for pointXY in pointIDDict[street].keys():
if not pointXY in pointRouteMDict[street]:
print street + " " + pointXY + " has no Route"
else:
for item in pointRouteMDict[street][pointXY]:
insertList.append(item)
insertList = sorted(insertList)
last_time = print_times("Created InsertList", last_time, start_time)
for item in insertList:
row = item
insertcursor.insertRow(row)
del insertcursor
del insertList
pointIDDict = {}
sourceFieldsList = ["X_Y_LINK", "OID@", "FREQUENCY", "FIRST_STNAMES", "CREATED", "MODIFIED", "DELETED", "POINT_ID", "X_COORD", "Y_COORD", "G_LAT", "G_LONG", "GOOGLE_URL"]
# Use list comprehension to build a dictionary from a da SearchCursor
pointIDDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(CL_INTERSECTION_POINTS_IDS_Full, sourceFieldsList)}
last_time = print_times("Created POINT_ID Dict", last_time, start_time)
searchFC = CENTERLINE_ROUTES_MERGED_Full
searchFieldsList = ["FULL_NAME", "ROUTE_NAME", "SHAPE@", "LENGTH", "LINE_LINK", "MMONOTONIC", "PARTS", "FROM_M", "TO_M"]
# This code extracts M values from Route vertices and is much faster than the Locate Features Along Route tool.
pointRouteMDict = {}
with arcpy.da.SearchCursor(searchFC, searchFieldsList) as searchRows:
for searchRow in searchRows:
keyValue = searchRow[0]
if keyValue > " " and keyValue in pointIDDict:
Route = searchRow[1]
feat = searchRow[2]
partnum = 0
partcount = feat.partCount
pntcount = 0
while partnum < partcount:
part = feat.getPart(partnum)
pnt = part.next()
while pnt:
pntcount += 1
x = pnt.X
y = pnt.Y
for xy in pointIDDict[keyValue]:
if abs(x - pointIDDict[keyValue][xy][1]) <= .0001 and abs(y - pointIDDict[keyValue][xy][2]) <= .0001:
cross_streets = pointIDDict[keyValue][xy][0].replace('{' + keyValue + '}', '').replace('}{', ';').replace('{', '').replace('}', '').split(';')
if cross_streets == [""]:
if pointIDDict[keyValue][xy][4] == 1:
cross = "END"
elif pointIDDict[keyValue][xy][4] == 2:
cross = "PSEUDO_NODE"
else:
cross = "BRANCH"
if not keyValue in pointRouteMDict:
pointRouteMDict[keyValue] = {}
pointRouteMDict[keyValue][xy] = [[Route, pnt.M, math.hypot(x-pointIDDict[keyValue][xy][1], y - pointIDDict[keyValue][xy][2]), pointIDDict[keyValue][xy][0], pointIDDict[keyValue][xy][1], pointIDDict[keyValue][xy][2], pointIDDict[keyValue][xy][3], pointIDDict[keyValue][xy][4], pointIDDict[keyValue][xy][5], pointIDDict[keyValue][xy][6], keyValue, xy + "{" + keyValue + "}", xy + "{" + Route + "}", None, None, cross, xy + "{" + cross + "}", None, None, "{" + keyValue + "}{" + cross + "}", xy + "{" + keyValue + "}{" + cross + "}", None, None, None, None, None, None]]
elif not xy in pointRouteMDict[keyValue]:
pointRouteMDict[keyValue][xy] = [[Route, pnt.M, math.hypot(x-pointIDDict[keyValue][xy][1], y - pointIDDict[keyValue][xy][2]), pointIDDict[keyValue][xy][0], pointIDDict[keyValue][xy][1], pointIDDict[keyValue][xy][2], pointIDDict[keyValue][xy][3], pointIDDict[keyValue][xy][4], pointIDDict[keyValue][xy][5], pointIDDict[keyValue][xy][6], keyValue, xy + "{" + keyValue + "}", xy + "{" + Route + "}", None, None, cross, xy + "{" + cross + "}", None, None, "{" + keyValue + "}{" + cross + "}", xy + "{" + keyValue + "}{" + cross + "}", None, None, None, None, None, None]]
else:
pointRouteMDict[keyValue][xy].append([Route, pnt.M, math.hypot(x-pointIDDict[keyValue][xy][1], y - pointIDDict[keyValue][xy][2]), pointIDDict[keyValue][xy][0], pointIDDict[keyValue][xy][1], pointIDDict[keyValue][xy][2], pointIDDict[keyValue][xy][3], pointIDDict[keyValue][xy][4], pointIDDict[keyValue][xy][5], pointIDDict[keyValue][xy][6], keyValue, xy + "{" + keyValue + "}", xy + "{" + Route + "}", None, None, cross, xy + "{" + cross + "}", None, None, "{" + keyValue + "}{" + cross + "}", xy + "{" + keyValue + "}{" + cross + "}", None, None, None, None, None, None])
else:
for cross in cross_streets:
if not keyValue in pointRouteMDict:
pointRouteMDict[keyValue] = {}
pointRouteMDict[keyValue][xy] = [[Route, pnt.M, math.hypot(x-pointIDDict[keyValue][xy][1], y - pointIDDict[keyValue][xy][2]), pointIDDict[keyValue][xy][0], pointIDDict[keyValue][xy][1], pointIDDict[keyValue][xy][2], pointIDDict[keyValue][xy][3], pointIDDict[keyValue][xy][4], pointIDDict[keyValue][xy][5], pointIDDict[keyValue][xy][6], keyValue, xy + "{" + keyValue + "}", xy + "{" + Route + "}", None, None, cross, xy + "{" + cross + "}", None, None, "{" + keyValue + "}{" + cross + "}", xy + "{" + keyValue + "}{" + cross + "}", None, None, None, None, None, None]]
elif not xy in pointRouteMDict[keyValue]:
pointRouteMDict[keyValue][xy] = [[Route, pnt.M, math.hypot(x-pointIDDict[keyValue][xy][1], y - pointIDDict[keyValue][xy][2]), pointIDDict[keyValue][xy][0], pointIDDict[keyValue][xy][1], pointIDDict[keyValue][xy][2], pointIDDict[keyValue][xy][3], pointIDDict[keyValue][xy][4], pointIDDict[keyValue][xy][5], pointIDDict[keyValue][xy][6], keyValue, xy + "{" + keyValue + "}", xy + "{" + Route + "}", None, None, cross, xy + "{" + cross + "}", None, None, "{" + keyValue + "}{" + cross + "}", xy + "{" + keyValue + "}{" + cross + "}", None, None, None, None, None, None]]
else:
pointRouteMDict[keyValue][xy].append([Route, pnt.M, math.hypot(x-pointIDDict[keyValue][xy][1], y - pointIDDict[keyValue][xy][2]), pointIDDict[keyValue][xy][0], pointIDDict[keyValue][xy][1], pointIDDict[keyValue][xy][2], pointIDDict[keyValue][xy][3], pointIDDict[keyValue][xy][4], pointIDDict[keyValue][xy][5], pointIDDict[keyValue][xy][6], keyValue, xy + "{" + keyValue + "}", xy + "{" + Route + "}", None, None, cross, xy + "{" + cross + "}", None, None, "{" + keyValue + "}{" + cross + "}", xy + "{" + keyValue + "}{" + cross + "}", None, None, None, None, None, None])
pnt = part.next()
if not pnt:
pnt = part.next()
partnum += 1
del searchRows
last_time = print_times("Created pointRouteMDict", last_time, start_time)
if arcpy.Exists(CL_INTERSECTIONS_Cross1_Full):
# Process: Delete (43)...
arcpy.Delete_management(CL_INTERSECTIONS_Cross1_Full, "Table")
last_time = print_times("Deleted Cross1", last_time, start_time)
arcpy.CreateTable_management(Centerline_Synch_gdb, CL_INTERSECTIONS_Cross1, CL_INTERSECTIONS_PAIRS_Full)
last_time = print_times("Created CL_INTERSECTIONS_Cross1", last_time, start_time)
fields = ["RID", "MEAS", "Distance", "STNAMES", "X_COORD", "Y_COORD", "X_Y_LINK", "WAYS_COUNT", "STNAME_WAYS", "POINT_ID", "STNAME", "X_Y_STNAME", "X_Y_ROUTE", "MAINT_TYPE", "IS_MAINTAINED", "CROSS_STREET", "X_Y_CROSS", "CROSS_MAINT_TYPE", "CROSS_IS_MAINTAINED", "PAIR_STNAMES", "X_Y_PAIRS", "RDNUMBER", "CROSS_RDNUMBER", "INT_CLARIFY", "INT_SPREAD", "GOOGLE_URL", "SEQUENCE"]
insertcursor = arcpy.da.InsertCursor(CL_INTERSECTIONS_Cross1_Full, fields)
insertList = []
print ""
print str(len(pointRouteMDict.keys()))
count = 0
for street in pointIDDict.keys():
count += 1
if not street in pointRouteMDict:
print street + " has no Point and no Route"
else:
for pointXY in pointIDDict[street].keys():
if not pointXY in pointRouteMDict[street]:
print street + " " + pointXY + " has no Route"
else:
for item in pointRouteMDict[street][pointXY]:
insertList.append(item)
insertList = sorted(insertList)
last_time = print_times("Created InsertList", last_time, start_time)
for item in insertList:
row = item
insertcursor.insertRow(row)
del insertcursor
del insertList
last_time = print_times("Inserted rows into CL_INTERSECTIONS_Cross1", last_time, start_time)
# Process: Make Table View (8)...
arcpy.MakeTableView_management(CL_INTERSECTIONS_Cross1_Full, CL_INTERSECTIONS_Cross1_View, "", "", "RID RID VISIBLE NONE;MEAS MEAS VISIBLE NONE;Distance Distance VISIBLE NONE;STNAMES STNAMES VISIBLE NONE;X_COORD X_COORD VISIBLE NONE;Y_COORD Y_COORD VISIBLE NONE;X_Y_LINK X_Y_LINK VISIBLE NONE;WAYS_COUNT WAYS_COUNT VISIBLE NONE;STNAME_WAYS STNAME_WAYS VISIBLE NONE;POINT_ID POINT_ID VISIBLE NONE;STNAME STNAME VISIBLE NONE;X_Y_STNAME X_Y_STNAME VISIBLE NONE;X_Y_ROUTE X_Y_ROUTE VISIBLE NONE;MAINT_TYPE MAINT_TYPE VISIBLE NONE;IS_MAINTAINED IS_MAINTAINED VISIBLE NONE;CROSS_STREET CROSS_STREET VISIBLE NONE;X_Y_CROSS X_Y_CROSS VISIBLE NONE;CROSS_MAINT_TYPE CROSS_MAINT_TYPE VISIBLE NONE;CROSS_IS_MAINTAINED CROSS_IS_MAINTAINED VISIBLE NONE;PAIR_STNAMES PAIR_STNAMES VISIBLE NONE;X_Y_PAIRS X_Y_PAIRS VISIBLE NONE;RDNUMBER RDNUMBER VISIBLE NONE;CROSS_RDNUMBER CROSS_RDNUMBER VISIBLE NONE; GOOGLE_URL GOOGLE_URL VISIBLE NONE; SEQUENCE SEQUENCE VISIBLE NONE")
sourceFC = CENTERLINE_ROUTES_MERGED_Layer
sourceFieldsList = ["ROUTE_NAME", "FULL_NAME"]
valueDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(sourceFC, sourceFieldsList)}
updateFC = CL_INTERSECTIONS_Cross1_View
updateFieldsList = ["RID", "MEAS", "Distance", "STNAMES", "X_COORD", "Y_COORD", "X_Y_LINK", "WAYS_COUNT", "STNAME_WAYS", "POINT_ID", "STNAME", "X_Y_STNAME", "X_Y_ROUTE", "MAINT_TYPE", "IS_MAINTAINED", "CROSS_STREET", "X_Y_CROSS", "CROSS_MAINT_TYPE", "CROSS_IS_MAINTAINED", "PAIR_STNAMES", "X_Y_PAIRS", "RDNUMBER", "CROSS_RDNUMBER", "GOOGLE_URL", "SEQUENCE"]
with arcpy.da.UpdateCursor(updateFC, updateFieldsList) as updateRows:
for updateRow in updateRows:
keyValue = updateRow[0]
if keyValue in valueDict:
X_Y_STNAME = updateRow[11]
X_Y_CROSS = updateRow[16]
updateRow[13] = XYNameDict[X_Y_STNAME][0]
updateRow[14] = isMaintDict[updateRow[13]]
updateRow[21] = XYNameDict[X_Y_STNAME][1]
if X_Y_CROSS in XYNameDict:
updateRow[17] = XYNameDict[X_Y_CROSS][0]
updateRow[18] = isMaintDict[updateRow[17]]
updateRow[22] = XYNameDict[X_Y_CROSS][1]
else:
updateRow[17] = ""
updateRow[18] = 0
updateRow[22] = ""
updateRows.updateRow(updateRow)
del updateRows
del valueDict
last_time = print_times("Updated Cross1", last_time, start_time)
sourceFields = ["PAIR_STNAMES", "X_Y_LINK"]
pairsXYDict = {}
with arcpy.da.SearchCursor(CL_INTERSECTIONS_Cross1_View, sourceFields) as searchRows:
for searchRow in searchRows:
pair_name = searchRow[0]
XYLink = searchRow[1]
if not pair_name in pairsXYDict:
pairsXYDict[pair_name] = [XYLink]
elif not XYLink in pairsXYDict[pair_name]:
pairsXYDict[pair_name].append(XYLink)
del searchRows
last_time = print_times("Created pairsXYDict", last_time, start_time)
pairsMinMaxDict = {}
pairsYXDict = {}
for key in pairsXYDict:
pairsXYDict[key] = sorted(pairsXYDict[key])
minX = 99999999999
maxX = 0
minY = 99999999999
maxY = 0
YXSorted = []
for item in pairsXYDict[key]:
if minX > float(item[1:13]):
minX = float(item[1:13])
if maxX < float(item[1:13]):
maxX = float(item[1:13])
if minY > float(item[15:27]):
minY = float(item[15:27])
if maxY < float(item[15:27]):
maxY = float(item[15:27])
YX = item[14:27] + item[0:13]
YXSorted.append([YX, item])
pairsMinMaxDict[key] = [minX, maxX, minY, maxY]
pairsYXDict[key] = sorted(YXSorted)
last_time = print_times("Created pairsYXDict", last_time, start_time)
pointLatLongDict = {}
sourceFieldsList = ["X_Y_LINK", "G_LAT", "G_LONG", "POINT_ID"]
# Use list comprehension to build a dictionary from a da SearchCursor
pointLatLongDict = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(CL_INTERSECTION_POINTS_IDS_Full, sourceFieldsList)}
last_time = print_times("Created XYLatLongDict", last_time, start_time)
RIDVal = " "
Sequence = 0
LastXY = " "
updateFields = ["PAIR_STNAMES", "X_Y_LINK", "INT_CLARIFY", "INT_SPREAD", "RID", "SEQUENCE", "GOOGLE_URL"]
with arcpy.da.UpdateCursor(CL_INTERSECTIONS_Cross1_View, updateFields) as updateRows:
for updateRow in updateRows:
pair_name = updateRow[0]
XYLink = updateRow[1]
if RIDVal != updateRow[4]:
RIDVal = updateRow[4]
LastXY = XYLink
Sequence = 1
if LastXY != XYLink:
LastXY = XYLink
Sequence += 1
updateRow[5] = Sequence
XYSorted = pairsXYDict[pair_name]
YXSorted = pairsYXDict[pair_name]
minX = pairsMinMaxDict[pair_name][0]
maxX = pairsMinMaxDict[pair_name][1]
minY = pairsMinMaxDict[pair_name][2]
maxY = pairsMinMaxDict[pair_name][3]
updateRow[3] = math.hypot(maxX - minX, maxY - minY)
if len(XYSorted) == 1:
updateRow[2] = " "
updateRow[3] = 0
elif len(XYSorted) == 2:
if maxX - minX >= maxY - minY:
if XYLink == XYSorted[0]:
updateRow[2] = "W"
else:
updateRow[2] = "E"
else:
if XYLink == XYSorted[0]:
if float(XYSorted[0][15:27]) > float(XYSorted[1][15:27]):
updateRow[2] = "N"
else:
updateRow[2] = "S"
else:
if float(XYSorted[0][15:27]) < float(XYSorted[1][15:27]):
updateRow[2] = "N"
else:
updateRow[2] = "S"
else:
if maxX - minX >= maxY - minY:
for i in range(len(XYSorted)):
if XYLink == XYSorted:
if len(XYSorted) < 9:
updateRow[2] = str(i+1)
else:
updateRow[2] = "{:02.0f}".format(i+1)
break
else:
for i in range(len(XYSorted)):
if XYLink == YXSorted[1]:
if len(YXSorted) < 9:
updateRow[2] = str(i+1)
else:
updateRow[2] = "{:02.0f}".format(i+1)
break
updateRow[6] = "http://maps.google.com/maps?q=" + str(round(pointLatLongDict[XYLink][0], 8)) + "," + str(round(pointLatLongDict[XYLink][1], 8)) + "+(" + pair_name.replace("}{", " / ").replace("{", "").replace("}", "").replace("'", "") + " - INT_CLARIFY = " + updateRow[2] + " - POINT ID = " + str(pointLatLongDict[XYLink][2]) + ")"
updateRows.updateRow(updateRow)
del updateRows
last_time = print_times("Updated INT_CLARIFY and INT_SPREAD", last_time, start_time)
# Process: Select Layer By Attribute (4)...
arcpy.SelectLayerByAttribute_management(CL_INTERSECTIONS_Cross1_View, "NEW_SELECTION", "\"STNAMES\" LIKE '%}{%'")
# Process: Add RID Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_Cross1_View, "RID", "RIDIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add MEAS Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_Cross1_View, "MEAS", "MEASIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add STNAMES Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_Cross1_View, "STNAMES", "STNAMESIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add STNAME Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_Cross1_View, "STNAME", "I613STNAME", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_Y_STNAME Index (2)...
arcpy.AddIndex_management(CL_INTERSECTIONS_Cross1_View, "X_Y_STNAME", "IND864XYSTNAME", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_Y_ROUTE Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_Cross1_View, "X_Y_ROUTE", "I613X_Y_ROUTE", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add CROSS_STREET Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_Cross1_View, "CROSS_STREET", "I613CROSS_STREET", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_Y_CROSS Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_Cross1_View, "X_Y_CROSS", "IND864XYCROSS", "NON_UNIQUE", "NON_ASCENDING")
last_time = print_times("Added 6 Indexes", last_time, start_time)
if arcpy.Exists(CL_INTERSECTIONS_PAIRS_OLD_Full) and arcpy.Exists(CL_INTERSECTIONS_PAIRS_Full):
# Process: Delete (47)...
arcpy.Delete_management(CL_INTERSECTIONS_PAIRS_OLD_Full, "Table")
if arcpy.Exists(CL_INTERSECTIONS_PAIRS_Full):
# Process: Rename (5)...
arcpy.Rename_management(CL_INTERSECTIONS_PAIRS_Full, CL_INTERSECTIONS_PAIRS_OLD_Full, "Table")
# Process: Sort
arcpy.Sort_management(CL_INTERSECTIONS_Cross1_View, CL_INTERSECTIONS_PAIRS_Full, "RID ASCENDING;MEAS ASCENDING;CROSS_STREET ASCENDING;X_Y_LINK ASCENDING", "UR")
last_time = print_times("Created CL_INTERSECTIONS_PAIRS", last_time, start_time)
# Process: Add RID Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "RID", "RIDIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add MEAS Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "MEAS", "MEASIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add STNAMES Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "STNAMES", "STNAMESIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_COORD Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "X_COORD", "X_COORDIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add Y_COORD Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "Y_COORD", "Y_COORDIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_Y_LINK Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "X_Y_LINK", "X_Y_LINKIND", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add STNAME Index (2)...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "STNAME", "STNAME", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_Y_STNAME Index (3)...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "X_Y_STNAME", "IND864XYSTNAME", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_Y_ROUTE Index (2)...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "X_Y_ROUTE", "I613X_Y_ROUTE", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add CROSS_STREET Index (2)...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "CROSS_STREET", "INDCROSS_ST", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_Y_CROSS Index (2)...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "X_Y_CROSS", "IND864XYCROSS", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add PAIRS_STNAMES Index...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "PAIR_STNAMES", "PAIRS_STNAMES", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add X_Y_PAIRS Index (2)...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "X_Y_PAIRS", "IND864XYPAIRS", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add RDNUMBER Index (2)...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "RDNUMBER", "INDRDNUMBER", "NON_UNIQUE", "NON_ASCENDING")
# Process: Add CROSS_RDNUMBER Index (2)...
arcpy.AddIndex_management(CL_INTERSECTIONS_PAIRS_Full, "CROSS_RDNUMBER", "INDCROSS_RDNUMBER", "NON_UNIQUE", "NON_ASCENDING")
last_time = print_times("Added 15 Indexes", last_time, start_time)
except Exception as e:
print e.message
logging.warning("")
logging.warning(e.message)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Mr. Fairhurst, is there a tool or app that runs this process that can be used with datasets from multiple states?
Sorry, i tried to message you, but it won't let me.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Mr. Fairhurst,
The code runs fine up until line 119. I am receiving a runtime error 00732 stating that the output file does not exist. What is the work around for this?
Thank you.