- Home
- :
- All Communities
- :
- Developers
- :
- ArcObjects SDK (Retired)
- :
- ArcObjects SDK Questions
- :
- How to Update AssetTypceCode field at a time for a...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to Update AssetTypceCode field at a time for all feature class
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dear Friends,
Here Attached for gdb & Asset_Type_Code Excel sheet.
I have number of Datasets & feature class in that feature class have Asset Type Code field. Each subtype have asset_type_code in the excel sheet .How can update at a time for all feature class and Subtypes.
Example : See the Image or SW_Fitting Feature class.
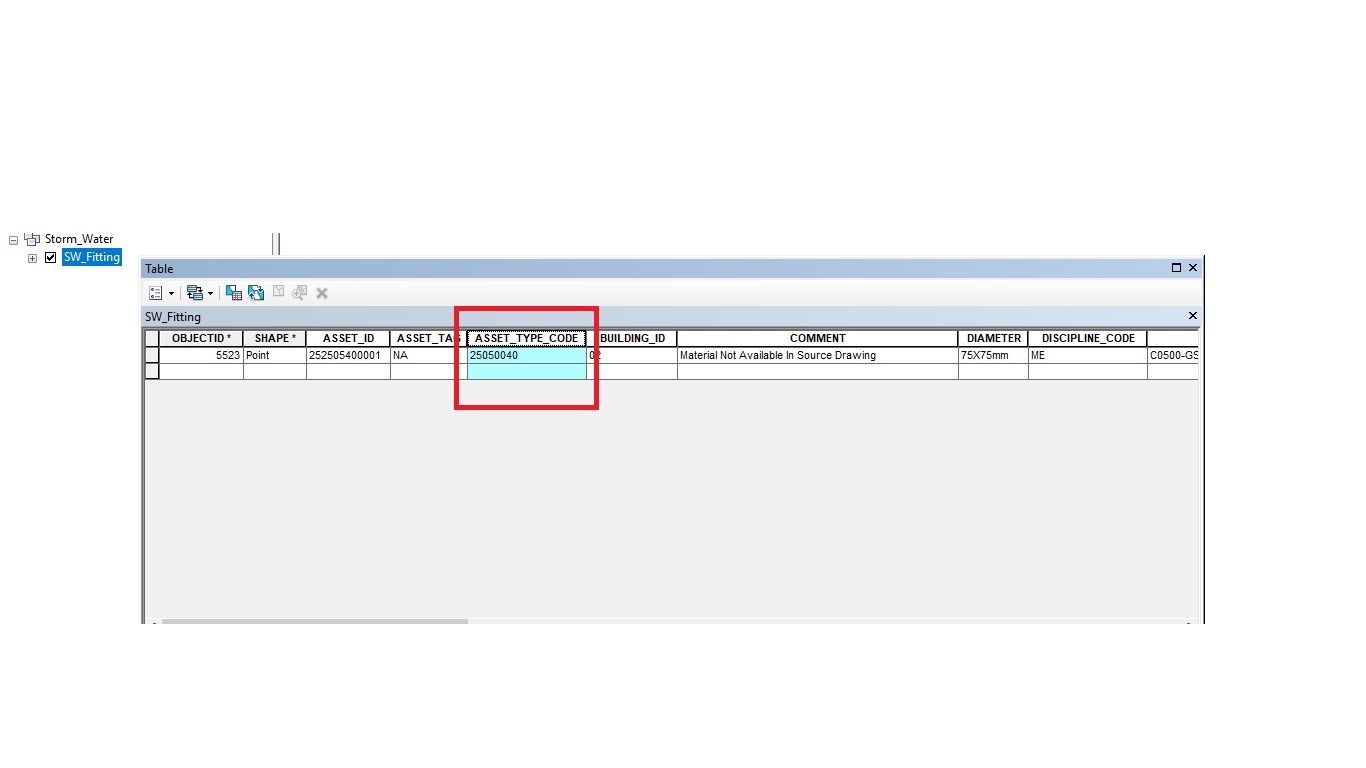
Thanks
Santhosh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Santhosh,
Have you looked into the Excel To Table—Conversion toolbox | ArcGIS Desktop tool? It will allow you to get the data out of the excel sheets and into a gdb. Once that is done, you can use an UpdateCursor—Data Access module | ArcGIS Desktop to loop through each row in the Table/FeatureClass and change the value as needed. Perhaps try the code samples from those docs to see how the tools work in Python.
I'm happy to help more, that's just somewhere to start. 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This code may get you close to what you need. The commented out print statements may help debug or understand the code.
The first step was using Clinton Dow's suggestion of Excel To Table (this page has sample code that will add all worksheets into your geodatabase as tables.
The second step was using code to loop through the feature classes in your feature datasets. This code is basically the code used in your previous question: How to Remove domain from field for gdb.
The third step was including some code by Richard Fairhurst in his blog on Turbo Charging Data Manipulation with Python Cursors and Dictionaries. I've been wanting to explore Richard's code, and this question seemed to suitable.
Here's the code. It may need some tweaking and clean-up.
import arcpy
gdb = r'C:\Path\To\COBW_WS_FA_HVAC_SO_SW_FP\COBW_WS_FA_HVAC_SO_SW_FP.gdb'
arcpy.env.workspace = gdb
# tab names from Excel file - each tab is a feature dataset
# the sample code at http://desktop.arcgis.com/en/arcmap/latest/tools/conversion-toolbox/excel-to-table.htm
# will print a list of tabs names -- NOTE: they should match your feature dataset names
dsets = ['Audiovisual','Building','Communication','ConveyingSystem','DataSystem','Drianage','Fire_Alarm',
'Fire_Protection','Fuel','Gas_Air_Services','HVAC','Irrigation','Laboratory','Landbase','Lighting',
'lightning_Earthing','LPG','Master_Clock','MATV_IPTV','Power','Public_Address','Security','Solar',
'Steam_services','Storm_Water','Water_Supply','TSE','WaterResources','BMS' ]
for fds in arcpy.ListDatasets('','Feature'):
if fds in dsets:
print "DS: {}".format(fds)
# table (converted from Excel) to connect to for codes
sourceTbl = 'Asset_TypeCode_xlsx_' + fds # this matches default table name from the Excel conversion script
# print sourceTbl
# Use list comprehension to build a dictionary from a da SearchCursor where the key values are based on 3 separate feilds
# See https://community.esri.com/blogs/richard_fairhurst/2014/11/08/turbo-charging-data-manipulation-with-...
# Section: Creating a Multi-Field Python Dictionary Key to Replace a Concatenated Join Field
sourceFieldsList = [ "FeatureDataset", "FeatureClass", "SubtypeCode", "AssetTypeCode" ] # will match variables fds, fc and st_name
valueDict = {str(r[0]) + "," + str(r[1]) + "," + str(r[2]):(r[3:]) for r in arcpy.da.SearchCursor(sourceTbl, sourceFieldsList)}
# print valueDict
for fc in arcpy.ListFeatureClasses("*","",fds):
print "\tFC: {}".format(fc)
subtypes = arcpy.da.ListSubtypes(fc)
# print subtypes # print subtypes dictionary for debugging if needed
# loop through feature class' subtypes one at a time
for stcode, stdict in list(subtypes.items()):
for stkey in list(stdict.keys()):
# if there is a Subtype Field (that is, it is not an empty string)
if not stdict['SubtypeField'] == '':
st_name = stdict['SubtypeField']
else:
# default values in Excel table for missing subtype
st_name = "-" # no subtype found
if stkey == 'FieldValues':
fields = stdict[stkey]
if 'ASSET_TYPE_CODE' in fields:
fieldFound = 1
else:
fieldFound = 0
print("\t\tSubtype: {}".format(st_name))
if st_name == '-' and fieldFound:
# no subtype used
updateFieldsList = ["ASSET_TYPE_CODE"]
# print "\t\t{}".format(updateFieldsList)
with arcpy.da.UpdateCursor(fc, updateFieldsList) as updateRows:
for updateRow in updateRows:
# store the Join value by combining 3 values: fds, fc and st_name
keyValue = "{},{},{}".format(fds, fc, '01') # use 01 for SubtypeCode
# verify that the keyValue is in the Dictionary
if keyValue in valueDict:
# transfer the value stored under the keyValue from the dictionary to the updated field.
updateRow[0] = valueDict[keyValue][0]
updateRows.updateRow(updateRow)
# print valueDict[keyValue][0]
else:
print "NOT FOUND: {}".format(keyValue)
# print valueDict
elif fieldFound:
# subtype
updateFieldsList = [st_name, "ASSET_TYPE_CODE"]
# print "\t\t{}".format(updateFieldsList)
with arcpy.da.UpdateCursor(fc, updateFieldsList) as updateRows:
for updateRow in updateRows:
# store the Join value by combining 3 field values of the row being updated in a keyValue variable
keyValue = "{},{},{:02d}".format(fds, fc, updateRow[0] )
# verify that the keyValue is in the Dictionary
if keyValue in valueDict:
# transfer the value stored under the keyValue from the dictionary to the updated field.
updateRow[1] = valueDict[keyValue][0]
updateRows.updateRow(updateRow)
# print "{} {}".format(updateRow[0], valueDict[keyValue][0])
else:
print "NOT FOUND: {}".format(keyValue)
else:
print "\t\tSkipping {}".format(fc)
del valueDict
print "Done."It seems that your Asset Code Type is a combination of a numeric code for the dataset, feature and subtype code. It should be possible to create a dictionary of datasets and features that would provide the first two codes, then you could combine them with the subtype code in each row of the feature to calculate the Asset Code Type.
In your Fire_Alarm worksheet, there wasn't a code for FA_Module with a subtype of 03. Also, the code above is expecting certain rules: tab names are same as dataset names, the feature class name is in the table, names are case sensitive, etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Randy:
Thanks for trying out code based on my Blog. I wanted to mention that since I wrote my Turbo Charging blog that I discovered that a composite key in a dictionary does not have to be concatenated into a string and can contain multiple values of any field type if you cast the list of values to a tuple. This means that the dictionary tuple keys will sort according to the native data type rules of each tuple component value and each component that makes up the dictionary key can be directly referenced with a tuple index. My Multiple Field Key to Single Field Key tool uses a tuple dictionary key to create a single field value in two data sources that can be used to create a standard join and that will sort the same way that the set of original fields would sort, with an ascending or descending sort independently applied to each field. That tool also optionally supports string matching that is case insensitive and that trims white space from one or both ends of the string.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks, Richard. I'll check out the blog post you mentioned. And I've noticed several other of your postings that I want to check out, too.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The reason dictionary keys must be cast to a tuple is because the keys must be hashable - since the items in a list can be added/deleted/swapped after instantiation it is considered 'mutable' meaning the values can be changed. A tuple is 'immutable', meaning that they can't be changed. Namedtuples are handy as keys in lots of cases. A frozenset is another acceptable collection to use as a key.
These objects can only be used for keys if their contents are hashable objects as well (implements __hash__), if you define a class without that method, it can't be used in a key.