- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Online
- :
- ArcGIS Online Blog
- :
- Easy How-To: Symbology Using Related Records
Easy How-To: Symbology Using Related Records
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
I've had a longstanding need to visualize, query, and filter features using values from a related table, and came up with the following solution, which works great for my use case.
Note: You can also use joined hosted feature layer views to symbolize by related records, but these have some limitations, as listed in the documentation. But if a joined view works for your use case, it's an easier option.
The use case involves managing stormwater catch basin inspection and cleaning (I've simplified the workflow for purposes of this post). The customer wanted field workers to be able to open Collector and quickly see basins that need attention or haven't been inspected/cleaned in over a year, and provide that same information in a dashboard.
It's easy to set up:
- Add fields to the feature layer to hold the attributes to bring over from the related table
- Grab the most recent record from the related table, and write values from that record over to the feature layer using the ArcGIS API for Python
- Put script on PythonAnywhere and set it to run every 60 seconds
- Configure web map symbology with a simple Arcade expression to show expired and failed inspections
Details on each step above:
- Self-explanatory. I named the fields "Status" and "LastCleaning".
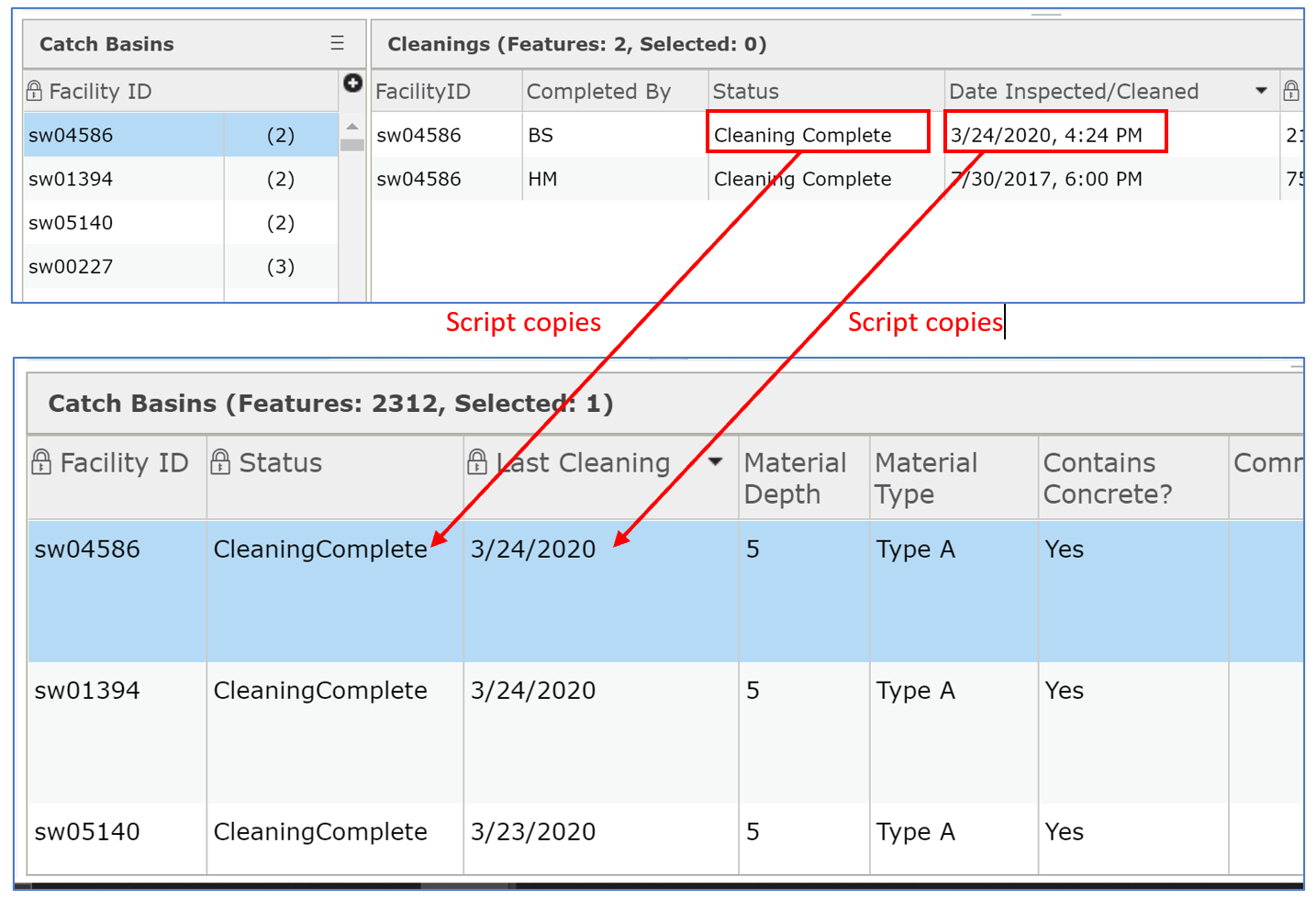
- Wrote the script shown at the end of this post to grab records from the related table from the past day, sort them by time and drop duplicate records related to an asset (in case there were two inspection/cleaning records within the past 24 hours -- for example, a failed inspection on Wednesday afternoon was resolved on Thursday morning), then use a unique identifier ('FacilityID') to update the asset with data from the most recent inspection/cleaning.
from arcgis import GIS
from arcgis.features import FeatureLayer
import pandas as pd
from arcgis.features import SpatialDataFrame
from datetime import datetime, timedelta
import time
gis = GIS(f"https://someorg.maps.arcgis.com", 'someuser', 'somepass')
def update_basins():
one_day = datetime.today() - timedelta(days=1)
string_day = one_day.strftime('%Y-%m-%d %H:%M:%S')
where_query = f"DateInspected >= DATE '{string_day}'"
# get catch basin features
catch_basins = gis.content.get('21343f6579b74cf212576e5614db8866')
catch_basins_lyr = catch_basins.layers[0]
catch_basins_sdf = SpatialDataFrame.from_layer(catch_basins_lyr)
catch_basins_fset = catch_basins_lyr.query()
catch_basins_features = catch_basins_fset.features
# get cleanings records
cleanings_url = 'https://services9.arcgis.com/iERASXD4kaw1L6en/arcgis/rest/services/this_is_an_example/FeatureServer/1'
cleanings_lyr = FeatureLayer(cleanings_url)
cleanings_sdf = SpatialDataFrame.from_layer(cleanings_lyr)
cleanings_fset = cleanings_lyr.query(where=where_query, out_fields='DateInspected, FacilityID, Status')
cleanings_features = cleanings_fset.features
# sort by clreaning date and drop all but most recent
cleanings_df = cleanings_sdf.sort_values('DateInspected', ascending=False)
cleanings_df = df.drop_duplicates(subset="FacilityID")
# find overlapping rows between catch basins and cleanings
overlap_rows = pd.merge(left = catch_basins_sdf, right = df, how='inner', on = 'FacilityID')
def update(basins, cleanings):
for FacilityID in overlap_rows['FacilityID']:
try:
basin_feature = [f for f in basins if f.attributes['FacilityID'] == FacilityID][0]
basin_feature.attributes['LastCleaning'] = cleanings.attributes['DateInspected']
basin_feature.attributes['Status'] = cleanings.attributes['Status']
catch_basins_lyr.edit_features(updates=[basin_feature])
print(f"Updated {basin_feature.attributes['FacilityID']} status to {basin_feature.attributes['Status']}", flush=True)
except Exception as e:
print(f"Could not update {FacilityID}. Exception: {e}")
continue
update(catch_basins_features, cleanings_features)
while True:
update_basins()
time.sleep(60)
- Set up an "Always-On" task on PythonAnywhere to continually run the script. This is a very easy process. Just set up a PythonAnywhere account (the free tier would probably be fine for this application), upload your script file, and add the script on the Tasks tab as an Always-On Task. Now, the script writes the most recent inspection/cleaning record to the catch basins attribute table every 60 seconds:
- And lastly, just a simple Arcade expression to symbolize by the status of each basin (Current, Expired, or Needs Attention):
var present = Now()
var last_cleaning = $feature.LastCleaning
var cleaning_age = DateDiff(present, last_cleaning, 'years');
If (cleaning_age < 1 && $feature.Status == 'CleaningComplete') {
return "Current"
} else if ($feature.Status == 'NeedsAttention') {
return "Needs Attention"
} else if (cleaning_age > 1) {
return "Expired"
} else if (IsEmpty($feature.Status)) {
return "Record missing or incomplete"
}
I hope this is helpful to someone. Feel free to offer suggestions or ask questions.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.