- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Spatial Analyst
- :
- ArcGIS Spatial Analyst Blog
- :
- Multiprocessing with ArcGIS - Raster Analysis
Multiprocessing with ArcGIS - Raster Analysis
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
With growing raster dataset sizes, the processing times for analysis are becoming longer and longer. By employing concepts from parallel and distributed computing, we can improve performance and scalability of workflows with Spatial Analyst tools. For some tools, Spatial Analyst offers enhanced performance with built-in parallel processing capability. These tools use the multi-core processors on modern computing hardware to complete processing tasks more quickly. Additionally, the ArcGIS Image Server provides capabilities for scalable distributed raster analysis and distributed storage of large image and raster collections. However, built-in capabilities are not yet available across all Spatial Analyst tools. In this blog, we will identify scenarios where the multiprocessing Python module (Python.org) can be used to optimize performance of raster analysis workflows by dividing up the work between multiple processes on a given machine. We will identify candidate raster operations that benefit most from parallel computation and learn how to develop efficient parallel systems for raster geoprocessing within the robust Python environment.
Candidate raster operations for parallelization can be broadly classified into three geoprocessing scenarios. Parallelism is invoked using a different mechanism for each scenario.
• Processing a large raster dataset with a single analysis tool
• Batch processing a collection of raster datasets by running a single analysis tool multiple times
• Raster geoprocessing workflow by running suitable analysis tools chained together
From our in-house testing, we evaluated the performance of a local operation executed parallelly on a large sample dataset. The graph below summarizes the performance improvements that were observed.
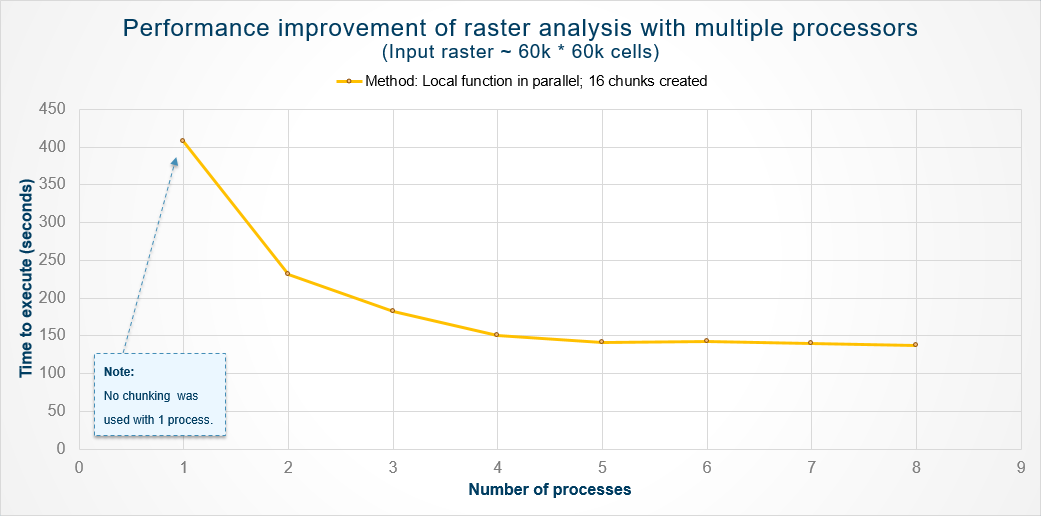
The advantages of optimizing raster analysis tasks with Python multiprocessing are evident from this graph. We can see significant improvements while adding more processes to help with the analysis, especially going from one to four processes. Beyond that, gains were negligible due to the overhead of spawning multiple processes.
Processing a large raster dataset
The increase in resolution of raster datasets has led to larger and larger data sizes. Currently, datasets are on the order of gigabytes and increasing, with billions of raster cells. While computing power of the processors and size of the memory in computers have increased appreciably, legacy equipment and algorithms suited to manipulating small rasters with coarser resolution make processing these improved data sources costly. [1]
Data decomposition, also known as divide and conquer, is a popular strategy used in parallel computing that we will take advantage of to parallelly process a large raster dataset. The algorithms used in raster analysis tools can be broadly classified into four categories – local, focal, zonal and global operations. For a deeper dive into the types of cell-based raster operations, read this article. Local, focal and zonal raster operations are simple to program with when it comes to data decomposition. Once the data is decomposed appropriately, each data ‘chunk’ can be operated on independently on by a process without the need to communicate with other processes. However, global raster operations are tougher to integrate with data decomposition and require communication between processes. Let us look at an example of processing a large raster dataset using a local math raster operation, Square Root. The Local, or per-cell operations, are the simplest to parallelize using a ‘divide and conquer’ strategy, since the resulting value at each cell only depends on the input value at that cell location. For each cell, the Square Root tool calculates the square root of the value from that cell. Using the tool serially would mean simply running the Square Root tool on the entire large dataset, but, this process can be time consuming.
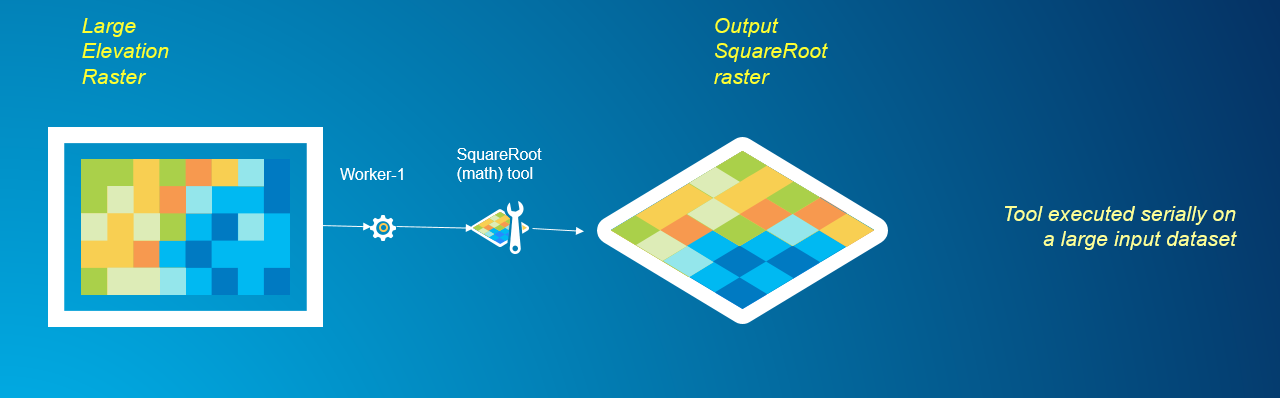
Default, non-optimized serial approach to processing a large raster
Instead, through data decomposition, we can redesign the analysis task to utilize multiple worker processes simultaneously, thus improving the performance of the overall analysis. The graphic below depicts splitting the domain of a large raster into several smaller chunks, and using multiple worker processes to simultaneously perform analysis on each of the sub-sections. The results are then stitched back together for the final output.
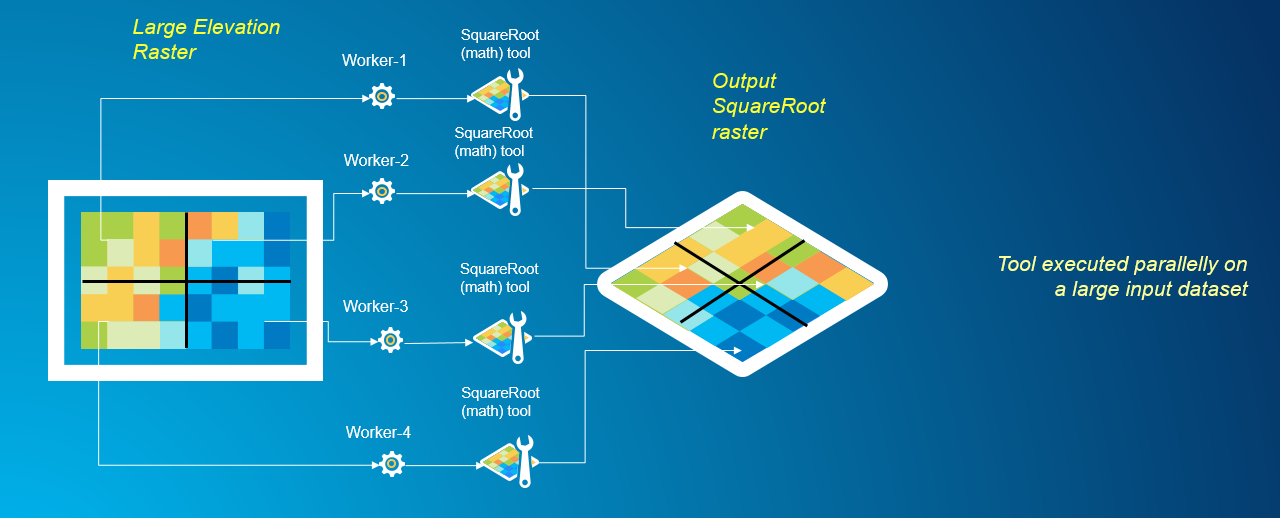
Multiprocessing large rasters parallelly
A sample script is shared on GitHub here that goes in depth on how this problem can be solved programmatically using ArcGIS Desktop and the Python multiprocessing module.
Batch processing a collection of raster datasets
When it comes to batch processing many datasets through a raster analysis tool, the common approach would be to use an iterator in ModelBuilder or write a Python script with a loop to iterate over each dataset in the batch and process them serially. This method can be time consuming when working with a large collection of rasters, particularly when running analysis tasks that have significant compute times.
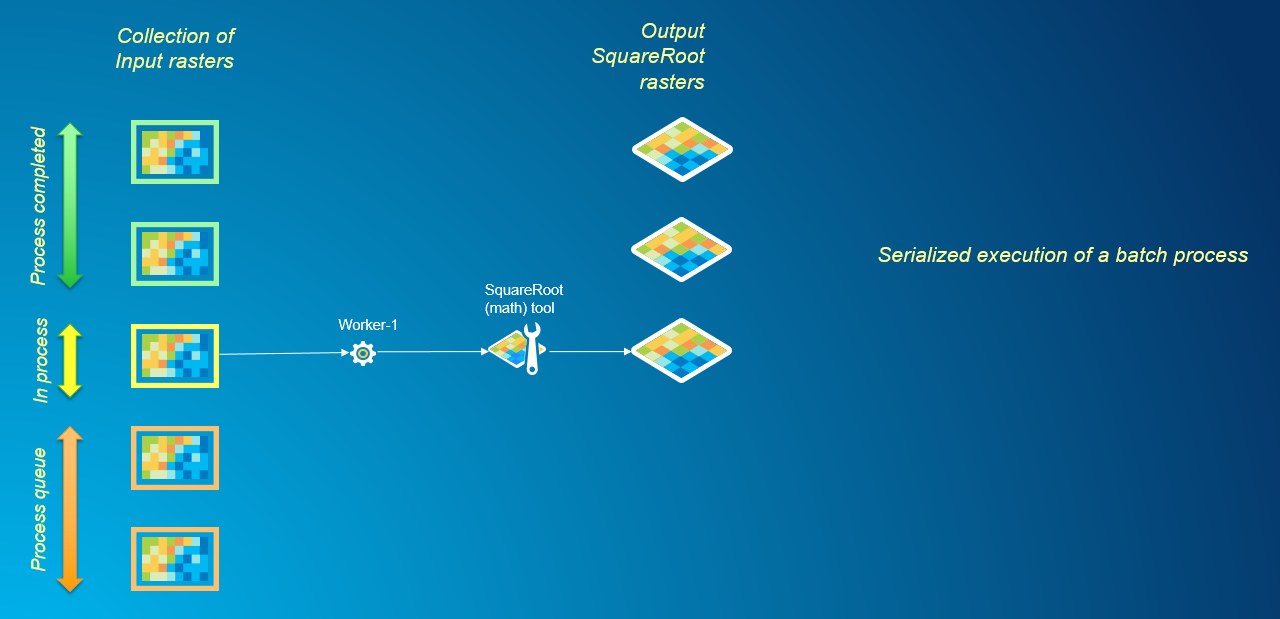
Default sequential approach to processing a multiple rasters
Parallelism is a straightforward mechanism for batch processing when the analysis of each dataset in the batch can be performed independently from the rest. From the graphic below we can see how multiple processes working simultaneously enable faster processing of the batch queue.
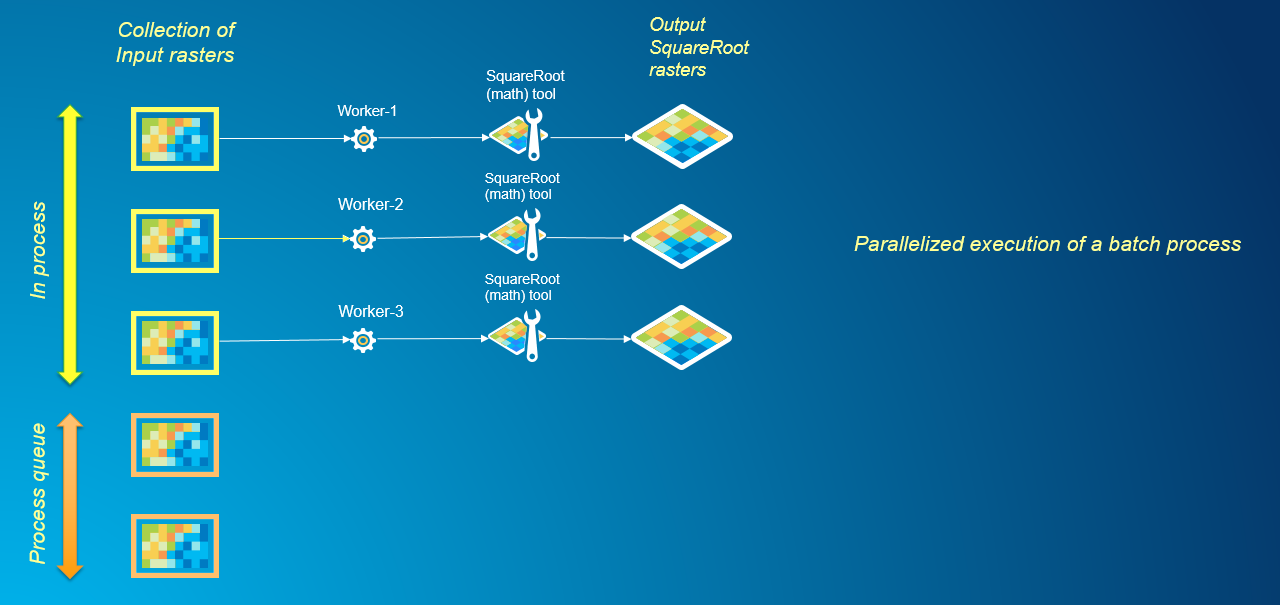
Using multiprocessing to efficiently process multiple rasters in a parallel fashion
A sample script is shared on GitHub here that describes in detail how batch processing can be solved programmatically using ArcGIS Desktop and the Python multiprocessing module.
Raster geoprocessing workflows
A geoprocessing workflow is a multiple-step procedure that combines geoprocessing tools and geographic data to produce a meaningful result. Within ArcGIS, raster geoprocessing workflows can be written as models using ModelBuilder or as Python scripts. The standard approach in either cases is to chain together the tools needed to perform your analysis and execute them serially. Let us look at an example workflow that assesses a suitability raster by running the Slope, Aspect, Reclassify and Weighted Sum tools. These tools are available as part of the Spatial Analyst Extension in ArcGIS Desktop.

Default approach to performing a workflow
In the above example, as tools are executed in a serial fashion, only one worker process can be utilized at a time to complete the workflow. To parallelize any geoprocessing workflow, the first task is to decompose the problem and identify parts of it that may be handled independently. This workflow is a good candidate for parallel processing as the execution of Slope, Aspect and Reclassify tools are independent tasks. These tasks have no dependencies on the execution of other tools in the workflow. However, the Weighted Sum tool is a dependent task, having dependencies on the outputs from the Slope, Aspect and Reclassify tools. Until the Slope, Aspect and Reclassify tools have finished executing, the Weighted Sum tool cannot begin its analysis. Having identified the independent and dependent tasks within this workflow, we can redesign this problem to parallelize it.
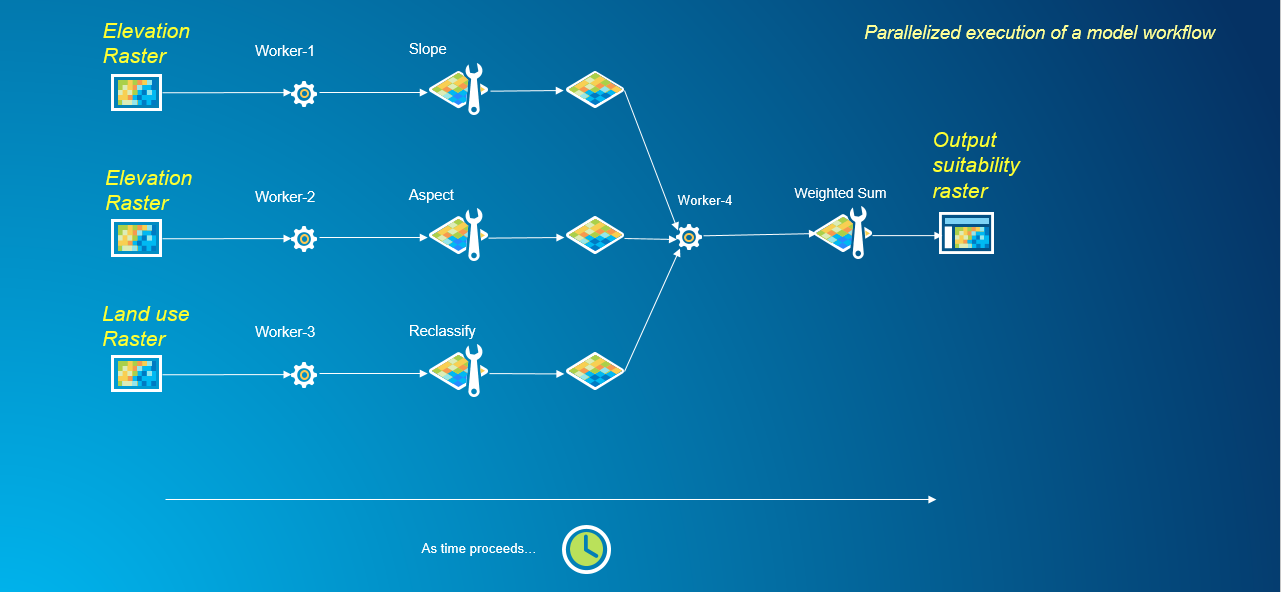
Incorporating parallel processing into model workflows
In this redesigned workflow, we are making use of multiple worker processes to execute independent tasks simultaneously, rather than depend on a single worker to process each task serially.
Best practices and considerations
There are many factors to consider while combining the capabilities of the arcpy and multiprocessing modules to improve performance of raster geoprocessing tasks.
• There are always overheads associated with spawning multiple processes that must be accounted for when considering a parallelized approach. In situations where the processing task is complex, and the processing data is large or the batch size is huge, parallelism can provide performance benefits that outweigh the overhead. In other situations, such as when the processing task is very simple, or if the processing datasets were not particularly large, it may be that utilizing multiprocessing does not provide any significant performance benefit and, in some cases, slows down overall processing speed. As parallelizing your code can be tedious, you should consider the end goal and opportunity cost of investing time in parallelization. For a task that is run repetitively, say on a scheduled basis, and in big data processing, parallelization can be advantageous.
• Avoid writing output rasters from multiple processes to a common File Geodatabase (FGDB) or to multiple Esri Grid rasters within a common folder workspace. These output formats often experience schema locks or synchronization issues when accessed by multiple simultaneous processes.
• You are encouraged to use ArcGIS Pro, ArcGIS Server or ArcMap with ArcGIS for Desktop Background Geoprocessing (64-bit) for parallelized raster analysis. Using 64-bit processing to perform analysis on systems with large amounts of RAM may help with processing large data efficiently.
Looking Ahead
The Spatial Analyst development team continues to work on parallelizing and distributing additional tools to further improve performance and scalability. Be on the lookout for these enhancements with future releases of ArcGIS Desktop, ArcGIS Pro and ArcGIS Image Server!
References
[1] Barnes, Lehman, Mulla. “Priority-Flood: An Optimal Depression-Filling and Watershed-Labeling Algorithm for Digital Elevation Models”. Computers & Geosciences. Vol 62, Jan 2014, pp 117-127, doi: ”10.1016/j.cageo.2013.04.024”.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.