- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
Inspiration... Re: Calculate field conditional statement using a date formula
Background...
| Bisect method |
|---|
>>> dts = [1,28,29,91,92,182,183,365,366] >>> bins = [28,91,182,365,400] >>> import bisect >>> a = [ bisect.bisect_left(bins,i) + 1 for i in dts] result a = [1, 1, 2, 2, 3, 3, 4, 4, 5] |
| Numpy method |
>>> dts = [1,28,29,91,92,182,183,365,366] >>> bins = [28,91,182,365,400] >>> import numpy as np >>> b = np.digitize(dts, bins, right=True) + 1 result list(b) = [1, 1, 2, 2, 3, 3, 4, 4, 5] |
It really bugs me that doing reclassification is such a pain whether you are using plain python or other software. This situation is only amplified if you are trying to do this in the field calculator.
Things can be made much easier using either numpy or the bisect module. .. whether it be text or numbers. The table to the right shows how to do this with the same data set using the bisect and the numpy modules.
The intent in the cited thread was to reclassify some values to an ordinal/intervale scale depending upon threshold values. This of course normally leads to a multi-tiered if statement. A simple list comprehension isn't much either due to the nature of the classification. To expedite matters, some method of parsing the data into an appropriate class is needed.
The bisect module and its methods, allow for this, should you be able to supply it with a sequential classification scheme. The data can be fed into the method within a list comprehension to return the values for a list of data all at once. If this method is to be used in the field calculator, a generator expression needs to be used since the field calculator and cursors in general, read their values sequentially from rows in a table.
| Reclass methods... numpy and bisect module |
Numpy reclass method
|
Numpy results
|
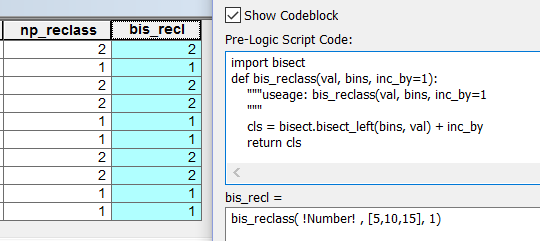 |
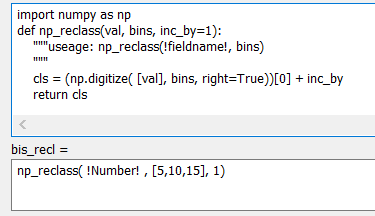
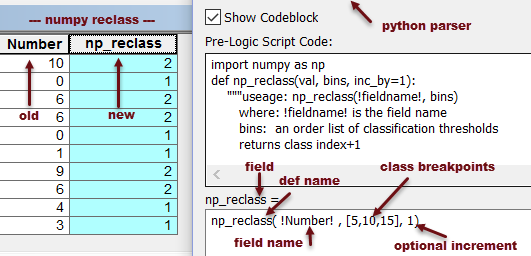
The results and the code are shown to the right.
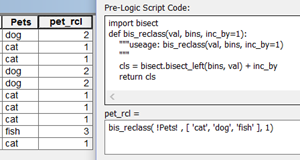
Oh yes... forgot about text...here are two examples, one from text to numbers and the second from text to text (apologies to dog owners)
| Homework |
|---|
 |
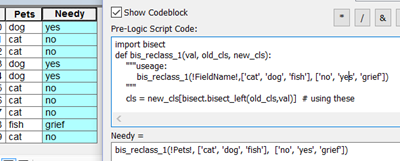 |
Should you have any other unique situations, please forward them on to me.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.