- Home
- :
- All Communities
- :
- User Groups
- :
- Python Snippets
- :
- Questions
- :
- what is wrong in my python intersect tool the line...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
what is wrong in my python intersect tool the line 103 give me error
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# Chapter4Modified2.py
# Created by Silas Toms
# 2014 04 23
# ---------------------------------------------------------------------------
# Import arcpy module
import arcpy
import csv
arcpy.env.overwriteOutput =True
Bus_Stops = r"D:\GIS\books\arcpy and arcgis - geospatial analysis with python\8662_ArcPyArcGIS_2\Data\SanFrancisco.gdb\SanFrancisco\Bus_Stops"
CensusBlocks2010 = r"D:\GIS\books\arcpy and arcgis - geospatial analysis with python\8662_ArcPyArcGIS_2\Data\SanFrancisco.gdb\SanFrancisco\CensusBlocks2010"
Inbound71 = r"D:\GIS\books\arcpy and arcgis - geospatial analysis with python\my work\chapter3.gdb\Inbound71"
Inbound71_400ft_buffer = r"D:\GIS\books\arcpy and arcgis - geospatial analysis with python\my work\chapter3.gdb\Inbound71_400ft_buffer"
Intersect71Census = r"D:\GIS\books\arcpy and arcgis - geospatial analysis with python\my work\chapter3.gdb\Intersect71Census"
bufferDist = 400
bufferUnit = "Feet"
lineNames = [('71 IB', 'Ferry Plaza'),('71 OB','48th Avenue')]
sqlTemplate = "NAME = '{0}' AND BUS_SIGNAG = '{1}'"
intersected = [Inbound71_400ft_buffer, CensusBlocks2010]
dataKey = 'NAME','STOPID'
fields = 'HOUSING10','POP10'
csvname = r'D:\GIS\books\arcpy and arcgis - geospatial analysis with python\my work\chapter3\Averages.csv'
def formatSQLMultiple(dataList, sqlTemplate, operator=" OR "):
'a function to generate a SQL statement'
sql = ''
for count, data in enumerate(dataList):
if count != len(dataList)-1:
sql += sqlTemplate.format(*data) + operator
else:
sql += sqlTemplate.format(*data)
return sql
def formatIntersect(features):
'a function to generate an intersect string'
formatString = ''
for count, feature in enumerate(features):
if count != len(features)-1:
formatString += feature + " #;"
else:
formatString += feature + " #"
return formatString
def createResultDic(resultFC, key, values):
dataDictionary = {}
fields = []
if type(key) == type((1,2)) or type(key) == type([1,2]):
fields.extend(key)
length = len(key)
else:
fields = [key]
length = 1
fields.extend(values)
with arcpy.da.SearchCursor(resultFC, fields) as cursor:
for row in cursor:
busStopID = row[:length]
data = row[length:]
if busStopID not in dataDictionary.keys():
dataDictionary[busStopID] = {}
for counter,field in enumerate(values):
if field not in dataDictionary[busStopID].keys():
dataDictionary[busStopID][field] = [data[counter]]
else:
dataDictionary[busStopID][field].append(data[counter])
return dataDictionary
def createCSV(data, csvname, mode ='ab'):
with open(csvname, mode) as csvfile:
csvwriter = csv.writer(csvfile, delimiter=',')
csvwriter.writerow(data)
sql = formatSQLMultiple(lineNames, sqlTemplate)
print 'Process: Select'
arcpy.Select_analysis(Bus_Stops,
Inbound71,
sql)
print 'Process: Buffer'
arcpy.Buffer_analysis(Inbound71,
Inbound71_400ft_buffer,
"{0} {1}".format(bufferDist, bufferUnit),
"FULL", "ROUND", "NONE", "")
iString = formatIntersect(intersected)
print iString
print 'Process: Intersect'
arcpy.Intersect_analysis(iString,
Intersect71Census, "ALL", "", "INPUT")
print 'Process Results'
dictionary = createResultDic(Intersect71Census, dataKey, fields)
print 'Create CSV'
header = [dataKey]
for field in fields:
header.append(field)
createCSV(header,csvname, 'wb' )
for counter, busStop in enumerate(dictionary.keys()):
datakeys = dictionary[busStop]
averages = [busStop]
for key in datakeys:
data = datakeys[key]
average = sum(data)/len(data)
averages.append(average)
createCSV(averages,csvname)
print "Data Analysis Complete"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey Ahmed,
Can you re-post your code using the Syntax Highlighter. This will make it easier to read and preserve all of your indentation as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks Jake Skinner for your help this is my code and give me error 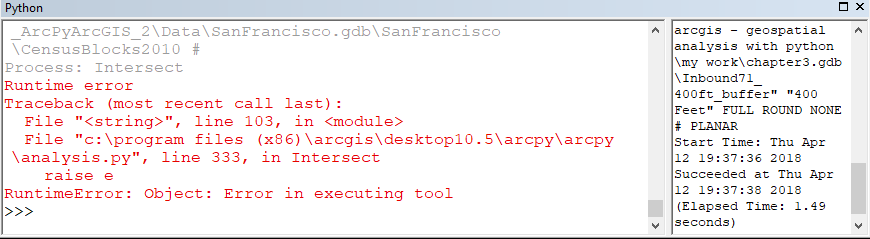
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Since you are using the defaults, just try
arcpy.Intersect_analysis(iString, Intersect71Census)You might want to print both the inputs out before that to ensure that they are indeed correct. Your paths are as convoluted as they can get with spaces and dashes etc. If the paths look correct, I would suggest moving everything to a better folder structure ... ie c:/GIS or something simple and try again.
And to be extra safe... reboot, try using the data in a new project and whatever else you haven't tried
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm having trouble reproducing this error with the below:
import arcpy
arcpy.env.overwriteOutput = 1
CensusBlocks2010 = r"D:\Temp\Python\Test.gdb\Counties"
Inbound71_400ft_buffer = r"D:\Temp\Python\Test.gdb\Cities"
Intersect71Census = r"D:\Temp\Python\Test.gdb\Intersect"
intersected = [Inbound71_400ft_buffer, CensusBlocks2010]
def formatIntersect(features):
'a function to generate an intersect string'
formatString = ''
for count, feature in enumerate(features):
if count != len(features)-1:
formatString += feature + " #;"
else:
formatString += feature + " #"
return formatString
iString = formatIntersect(intersected)
print iString
print 'Process: Intersect'
arcpy.Intersect_analysis(iString,
Intersect71Census, "ALL", "", "INPUT")I would agree with Dan and try simplifying your paths. Another thing to do is to manually run the Intersect in ArcMap. Then go to the Geoprocessing menu > Results. In the results window right-click on the Intersect tool > Copy as Python snippet. You can then paste this into your code and compare it what ran successfully and to what your code is running.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just noticed that the script is by another individual for some exercise in a gis book.
If you are trying to replicate and/or use the script, you would also have to replicate the environment with respect tosoftware, extensions etc. Did you do this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
yes i do this i replaced the paths of my code to another path and i do all steps in the book but i think the code in the book is wrong because i review it more than one and i found another code in the book is wrong but i don't know where is wrong in my line code 103 i'm new learner arcpy and python. if you have this book dan and his data tell me where is the wrong i working in arcgis 10.5.1.7333 and working in default python 2.7.13 it give me wrong then update python to 2.7.14 it give me wrong and the book working in arcgis 10.1 and python 2.7.3 i asking can this little change in arcgis version and python version affect on the result and give me this error ? thanks dan.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You would have to show the exact code you are using with your paths. A lot changed in ArcGIS, but little changed in python.
Jake's answer does show that the process works if paths are kept simple and the data are not corrupt