- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- loop for value and counts in raster attribute
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
loop for value and counts in raster attribute
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Guys,
I'm a beginner to python scripting in GIS. I ‘m trying to make a loop for field “value” and “count” of a raster data. The logic behind the code is:
-1st calculate the total number of counts in the original raster
- use the " 1st value" from value field of the raster attribute of original raster to extract a new raster using raster calculator
-calculate the total number of counts in the new raster
-If the total counts of new raster < 0.25*(total counts of original raster)
-Then got the threshold value(which was used to calculate new raster from the original raster)
-Else, use the next value from the old raster attribute to calculate new raster and the total “count” of new raster until the total counts of new raster is < 0.25* (total counts of original raster).
I am providing the code below.However, I am getting "invalid syntax error" at the end of the for loop in the code below where it says "next row". I would appreciate any comment/suggestion.
Thanks!
Code:
import arcpy
from arcpy import env
from arcpy.sa import *
#To overwrite output
arcpy.env.overwriteOutput = True
#Set environment settings
env.workspace = "C:/Subhasis/Test/Neshanic_Python"
# set local variable
inraster ="01367620-r-r"
# read attribute table of raster
rows = arcpy.SearchCursor(inraster,"","","Count","")
# sum of counts in raster
s1=[]
for row in rows:
s1.append(row.getValue("Count"))
A= sum(s1)
#checkout ArcGIS spatial analyst extension license
arcpy.CheckOutExtension("Spatial")
# read attribute table of raster
rows = arcpy.SearchCursor(inraster,"","","value","")
for row in rows:
inSQLClause = "VALUE = row"
attExtract = ExtractByAttributes(inraster, inSQLClause)
attExtract.save("C:/Subhasis/Test/Neshanic_Python/STI-TH")
inraster="STI-TH"
rows = arcpy.SearchCursor(inraster,"","","Count","")
s2=[]
for row in rows:
s2.append(row.getValue("Count"))
B=sum(s2)
if B<=.25*A:
print 'got the Threshold point for STI row'
else:
print'need to use different STI'
next row
..........................................................................................................................
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Actually, there is a lot more going on in the script that wont work:
- the nested loop and reusing the same variable names (row, rows, inraster)
- the where clause will not be filled with the value you're reading
- the print statement at the end will never show a result since the "row" is printed as text
- you're mixing the "normal" SearchCursor and da.SearchCursor syntax
Furthermore, there is actually no need to create rasters, and therefore you don't need a SA license.
Take a look at the code below:
import arcpy
inraster ="C:/Subhasis/Test/Neshanic_Python/01367620-r-r"
threshold = 0.25
flds = ("VALUE", "COUNT")
dct = {row[0]:row[1] for row in arcpy.da.SearchCursor(inraster, flds)}
sumcnt = sum(dct.values())
threscnt = sumcnt * threshold
print "Number of pixels with a value = {0}".format(sumcnt)
print "Maximum number of pixels within threshold = {0}".format(threscnt)
cnt, result = 0, 0
for k in sorted(dct):
cnt += dct
print " - Value = {0}, Sum = {1}".format(k, cnt)
if cnt < threscnt:
result = int(k)
else:
break
print "Threshold = {0}".format(result)
On line 7 a dictionary is created using the da.SeachCursor. A dictionary is an object that hold key (=VALUE), value (=COUNT) pairs. Insert a print statement in the code to print the "dct" object to see how it is filled.
The sum of all the counts is calculated on line 8
On line 9 a variable is introduced that holds the maximum number of pixels based on the specified threshold.
Line 14 till 21 loop through the sorted dictionary (it is sorted on the pixel values) and calculates the sum of the COUNT of all the pixel values less than or equal to the current pixel value. In case this count is less than the maximum number of pixels calculated on line 9, the result is overwritten with the new best result.
Have a look at the output generated with a test raster:
Number of pixels with a value = 219996
Maximum number of pixels within threshold = 54999.0
- Value = 0, Sum = 10649
- Value = 1, Sum = 10721
- Value = 2, Sum = 10807
- Value = 3, Sum = 10896
<< other values omitted>>
- Value = 38, Sum = 53141
- Value = 39, Sum = 54281
- Value = 40, Sum = 55675
Threshold = 39
Kind regards,
Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
you shouldn't need the "next row" at all, you are in a for loop, so it will loop through all the rows regardless. Also, if you are on ArcGIS 10.1 or higher, I would use the data access cursor(arcpy.da.SearchCursor), it works significantly faster the old arcpy.SearchCursor.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Actually, there is a lot more going on in the script that wont work:
- the nested loop and reusing the same variable names (row, rows, inraster)
- the where clause will not be filled with the value you're reading
- the print statement at the end will never show a result since the "row" is printed as text
- you're mixing the "normal" SearchCursor and da.SearchCursor syntax
Furthermore, there is actually no need to create rasters, and therefore you don't need a SA license.
Take a look at the code below:
import arcpy
inraster ="C:/Subhasis/Test/Neshanic_Python/01367620-r-r"
threshold = 0.25
flds = ("VALUE", "COUNT")
dct = {row[0]:row[1] for row in arcpy.da.SearchCursor(inraster, flds)}
sumcnt = sum(dct.values())
threscnt = sumcnt * threshold
print "Number of pixels with a value = {0}".format(sumcnt)
print "Maximum number of pixels within threshold = {0}".format(threscnt)
cnt, result = 0, 0
for k in sorted(dct):
cnt += dct
print " - Value = {0}, Sum = {1}".format(k, cnt)
if cnt < threscnt:
result = int(k)
else:
break
print "Threshold = {0}".format(result)
On line 7 a dictionary is created using the da.SeachCursor. A dictionary is an object that hold key (=VALUE), value (=COUNT) pairs. Insert a print statement in the code to print the "dct" object to see how it is filled.
The sum of all the counts is calculated on line 8
On line 9 a variable is introduced that holds the maximum number of pixels based on the specified threshold.
Line 14 till 21 loop through the sorted dictionary (it is sorted on the pixel values) and calculates the sum of the COUNT of all the pixel values less than or equal to the current pixel value. In case this count is less than the maximum number of pixels calculated on line 9, the result is overwritten with the new best result.
Have a look at the output generated with a test raster:
Number of pixels with a value = 219996
Maximum number of pixels within threshold = 54999.0
- Value = 0, Sum = 10649
- Value = 1, Sum = 10721
- Value = 2, Sum = 10807
- Value = 3, Sum = 10896
<< other values omitted>>
- Value = 38, Sum = 53141
- Value = 39, Sum = 54281
- Value = 40, Sum = 55675
Threshold = 39
Kind regards,
Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Xander,
Sorry for my late response. Thank you very much for your quick response and walk through the code step by step.
When you have a chance could you please tell me the following:
-I want to automate this process for 70 rasters (finding the threshold value first for each raster)
-make a new raster using the individual threshold value and store the new raster in individual raster
Logic:-Assign a list and keep all the raster name inside the list
-Use a for loop to iterate the rasters in "inraster position in the code
Problem: each raster files have two folders: 1) raster name, 2)info. The second folder "info" is common for all raster. Therefore, I am not able to put all rasters directly in the working folder. Is there way I can solve this problem?
Code:
import arcpy,os
from arcpy import env
from arcpy.sa import *
#To overwrite output
arcpy.env.overwriteOutput = True
#Set environment settings
env.workspace = "C:/Subhasis/Test/Neshanic_Python"
outws="C:/Subhasis/Test/Neshanic_Python/extract"
#checkout ArcGIS spatial analyst extension license
arcpy.CheckOutExtension("Spatial")
# set local variable (only presented 3 out of 70 for testing)
inraster = ["01367620-r-r,01367700-r-r,01367770-r-r"]
threshold = 0.75
for i in inraster:
flds = ("VALUE", "COUNT")
dct = {row[0]:row[1] for row in arcpy.da.SearchCursor(i, flds)}
sumcnt = sum(dct.values())
threscnt = sumcnt * threshold
print "Total number of pixels with a value = {0}".format(sumcnt)
print "Total number of pixels within threshold = {0}".format(threscnt)
cnt, result = 0, 0
for k in sorted(dct):
cnt += dct
print " - Value = {0}, Sum = {1}".format(k, cnt)
if cnt < threscnt:
result = int(k)
else:
break
print "Threshold = {0}".format(result)
attExtract = ExtractByAttributes(str(i), "VALUE>=" + str("{0}".format(result)))
outname=os.path.join(outws,str(i), str("{0}".format(result)))
attExtract.save(outname
Thanks a lot for your time and help!
Subhasis
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Subhasis,
I suppose the code you posted did not work, right?
The list you created to test the code is actually a list with only one element. The list should have been created as (notice the missing quotes):
inraster = ["01367620-r-r","01367700-r-r","01367770-r-r"]
Don't worry about the folders, each folder contains an Esri grid and the info folder is a common storage for those grids.
The other part that wasn’t optimal was this block:
attExtract = ExtractByAttributes(str(i), "VALUE>=" + str("{0}".format(result)))
outname=os.path.join(outws,str(i), str("{0}".format(result)))
attExtract.save(outname
Apart from the missing bracket at the end, you don’t need to cast the name of the raster to string (it is already string). The strength of using “format” is that you can combine strings and values together in a much easier way.
I haven't tested the code below:
import arcpy,os
from arcpy import env
from arcpy.sa import *
#To overwrite output
arcpy.env.overwriteOutput = True
#Set environment settings
env.workspace = "C:/Subhasis/Test/Neshanic_Python"
outws="C:/Subhasis/Test/Neshanic_Python/extract"
#checkout ArcGIS spatial analyst extension license
arcpy.CheckOutExtension("Spatial")
# create a list of all rasters in current workspace
lst_ras = arcpy.ListRasters()
# set local variable (only presented 3 out of 70 for testing)
# inraster = ["01367620-r-r,01367700-r-r,01367770-r-r"]
threshold = 0.75
for ras in lst_ras:
flds = ("VALUE", "COUNT")
dct = {row[0]:row[1] for row in arcpy.da.SearchCursor(i, flds)}
sumcnt = sum(dct.values())
threscnt = sumcnt * threshold
# print "Total number of pixels with a value = {0}".format(sumcnt)
# print "Total number of pixels within threshold = {0}".format(threscnt)
cnt, result = 0, 0
for k in sorted(dct):
cnt += dct
# print " - Value = {0}, Sum = {1}".format(k, cnt)
if cnt < threscnt:
result = int(k)
else:
break
# print "Threshold = {0}".format(result)
attExtract = ExtractByAttributes(ras, "VALUE>={0}".format(result))
outname = os.path.join(outws,"{0}{1}".format(ras, result))
attExtract.save(outname)
arcpy.CheckInExtension("Spatial")
Kind regards, Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Xander,
Thank you very much! This code works only for one raster which has both " ESRI grid" and "info" folder inside the working directory. I was n't able to keep the "info" folder of other two raster inside the working directory as the "info" folder of 1st raster is already in the working directory.
I know it is stupid question. But could you please let me know how can i keep the "info" folders of other two rasters inside the working directory?
Thank you very much for your time and help!
Regards,
Subhasis
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi again Subhasis,
Is there any particular reason why you are using ESRI grids, instead of another raster format, which wouldn't have multiple folders, such as a .tif?
If you want to to iterate over multiple rasters that are in seperate folders than have a common parent folders, you could use arcpy.da.walk, to iterate over them all in seperate folders, that way you wouldn't have to put all your info folders into a single folder. you can make a list of all the filepaths and names, then iterate over that list with your script(see example #2 in the link below)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ian,
Thanks a lot! Yes, the output I have is in ESRI grid format for 70 rasters before. So, I 'm trying to automate this process. I would follow example 2 in the link.
Regards,
Subhasis
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So, if I understand it correctly your folderstructure does not contain all raster in the same folder (workspace), but in subfolders of the workspace (so the right part if the image below):
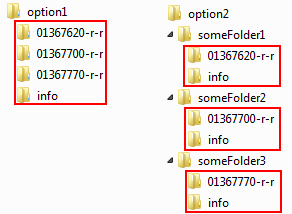
In that case the arcpy.da.Walk option (available from 10.1 SP 1) as suggested by Ian Murray is the right way to go.
The code would look like this (once again, the code is not tested):
import arcpy,os
from arcpy import env
from arcpy.sa import *
#To overwrite output
arcpy.env.overwriteOutput = True
#Set environment settings
ws = "C:/Subhasis/Test/Neshanic_Python"
env.workspace = ws
outws="C:/Subhasis/Test/Neshanic_Python/extract"
threshold = 0.75
#checkout ArcGIS spatial analyst extension license
arcpy.CheckOutExtension("Spatial")
# create a list of all rasters in current workspace
dct_ras = {}
# use arcpy.da.Walk (available from 10.1 SP1) to generate dictionary of rasters
for dirpath, dirnames, filenames in arcpy.da.Walk(ws,
topdown=True,
datatype="Raster"):
for filename in filenames:
ras = os.path.join(dirpath, filename)
dct_ras[ras] = filename
# loop through dictionary and extract path to input ras and rasname
for ras, rasname in dct_ras.items():
flds = ("VALUE", "COUNT")
dct = {row[0]:row[1] for row in arcpy.da.SearchCursor(ras, flds)}
sumcnt = sum(dct.values())
threscnt = sumcnt * threshold
cnt, result = 0, 0
for k in sorted(dct):
cnt += dct
# print " - Value = {0}, Sum = {1}".format(k, cnt)
if cnt < threscnt:
result = int(k)
else:
break
# print "Threshold = {0}".format(result)
attExtract = ExtractByAttributes(ras, "VALUE>={0}".format(result))
outname = os.path.join(outws,"{0}{1}".format(rasname, result))
attExtract.save(outname)
# return SA extension
arcpy.CheckInExtension("Spatial")
In this case I do not write the rasters to a list with simply the raster names, since they reside in different workspaces. The rasters path is used as dictionary key and the raster name is used as value. Do notice that in your structure the raster names can repeat and create output rasters with same name (in case the threshold value is equal too). Be ware of that.
Kind regards,
Xander