- Home
- :
- All Communities
- :
- Industries
- :
- Water Utilities
- :
- Water Utilities Questions
- :
- Re: If you’re using the Attribute Assistant, we ne...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
If you’re using the Attribute Assistant, we need your help!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We’re doing some research into how the Attribute Assistant is being used. We’d like to see what rules you are using and how you configured your dynamic value table.
This information will help us plan for the future. We want to know what are the most common rules. We also want to see your gnarly and complicated rules to see how far the Attribute Assistant is being pushed.
So please share your dynamic value table along with any comments you have in this thread. We appreciate your help on this effort!
Thanks,
Mike
ArcGIS Solutions
PS: If you don’t know what the Attribute Assistant is (or aren’t sure if you are using it already) no worries. You can learn more about Attribute Assistant on the ArcGIS Solution site here.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mike,
Is there any way to put the feature class that the validation is for at the top of the window somewhere? In the case of a MasterStreetName change, the edits could cascade down to multiple features and this validation window could pop up multiple times for different feature classes (road centerlines, nodes, site address points). It can get confusing. Or maybe I just have my DynamicValue table set up incorrectly...
Either way, a feature class name at the top of the window would help.
Thanks,
Jace
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How about this: 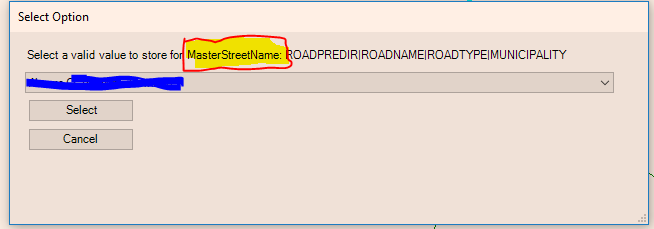
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I like it. That will help clarify what table the verification is for. Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mike,
The validation windows can still be confusing if they don't inform the user about which fields are the source and which are the destination, in fact they may look identical in some instances. Even as the DynamicValue table editor, I get confused when I have to validate values on Road Centerlines for the new segment's information, the "from" street info, and the "to' street info. In all three cases the validation window (with your new addition) would show:
Select a valid value to store for RoadCenterline: FULLNAME,MUNICIPALITY,STCODE
Ideally, the validation window would tell you which table's fields are being updated and what the source table and fields are as well.
Template - Fields from DynamicValue table in <>
Validating <TABLENAME> (<FIELDNAME>), select valid value(s) from <VALUEINFO>
Example 1 - New road segment with "from" and "to" street validations
Validating RoadCenterline (FULLNAME,MUNI1,STCODE), select valid value(s) from MasterStreetName|FULLNAME,MUNICIPALITY,STCODE
Validating RoadCenterline (FRSTNM,MUNI2,FRSTNBR), select valid value(s) from MasterStreetName|FULLNAME,MUNICIPALITY,STCODE
Validating RoadCenterline (TOSTNM,MUNI3,TOSTNBR), select valid value(s) from MasterStreetName|FULLNAME,MUNICIPALITY,STCODE
Example 2 - Creating or updating Nodes on street intersections
Validating Nodes (FULLNAME1,MUNI1,STCODE1), select valid value(s) from MasterStreetName|FULLNAME,MUNICIPALITY,STCODE
Validating Nodes (FULLNAME2,MUNI2,STCODE2), select valid value(s) from MasterStreetName|FULLNAME,MUNICIPALITY,STCODE
I hope I'm making sense.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Logged the issue here: https://github.com/Esri/local-government-desktop-addins/issues/286
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We’ve been testing the AA in our SDE (10.5.1)/Oracle environment, and while we don't have at present an issue, per se, with the GenerateID table working (it increments properly, as expected), my issue is one of HOW it works?
The documentation, beyond stating that the GenerateID table must be in the SAME database/schema as the dataset(s) it’s utilized for, is largely lacking in any instructions regarding the setting of actual permissions. Several other threads with users’ questions underscored the fact that you must not version the table – which, of course, makes sense on its face, to avoid duplicate ID gneration – but, doesn’t address how the table is ultimately able to be written to, given the permissions that are not granted to it. Because of this, my initial perception from our test environment was that the GenerateID table (with no additional permissions granted) had to be loaded into our MXDs as the Schema User (owner) – which is a major security concern. I eventually, if not somewhat randomly, granted the GenerateID table the same edit role as my versioned data, but having to explicitly grant Insert/Update/Delete (which did not get granted automatically, since it’s not versioned). I then resourced the GenerateID table in my MXD as myself (not the Schema User), and to my amazement, it worked. We’ve since had three of us here in our dept. all make some test edits in our own edit versions on the same dataset, and we’re successfully reading and writing back to the GenerateID table (loaded using each of our own account credentials), and are able to refresh it to see the new max ID values as updated by our counterparts.
What method is the AA using behind-the-scenes to force its way through the permissions wall? It’s clear that the permissions alone which I granted are insufficient to allow this table to be edited, since when I attempt to Start Editing, I get the customary error/warning that the table in question is not editable since it’s not versioned. Is AA passing some hidden credentials to allow it to write back to the table – and, if so, where is it getting these, given that the schema credentials exist in no other data layer loaded in said MXD? Is it passing some heretofore unmentioned “skeleton key” credentials that allow it to bypass otherwise assigned roles?
Beyond simply my curiosity, the answer to this is important from a database admin POV, since I need to be able to troubleshoot future scenarios, should something inexplicably stop working. And because I am on the hook for permissions/security issues, I can’t afford to have a blind spot where a user-issued write-back to a non-versioned schema-owned table is concerned.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No magic in the AA. We are using the connection info from the layer in the map. The code is fairly basic to make the unversioned edit. You can review it here. Search for unversionedEdit. We are using ITransaction to make an edit outside the edit sessions - ITransactions Interface
If you tried editing an unversioned table in ArcMap and it does not work, make sure to enable non versioned editing in the editor options. Once you change this, see if you can make an edit to the table.
On a side note, we found that there is a chance for duplicate IDs when more than one user is bulk loading data. As the transactions are happening so fast, the client side logic to generate an ID fails. We added a beta capability that supports the use of a stored procedure against the generate id table to ensure no dup ids get generated. Here is an example - local-government-desktop-addins/GetSequenceStoreProcedure at master · Esri/local-government-desktop-...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mike,
I guess that’s where I’m remaining confused… It was my understanding that even if a feature class is enabled for non-versioned editing, the edit still needs to be done using the same valid credentials that would be required otherwise. In the case of the GenerateID table, only the Schema User (under which the table was created and data loaded) has that level of privileges. The individual editor/user account (under whose credentials the table was loaded into the MXD) does not have these privileges, yet is apparently able to write to the table, nonetheless. Does the ITransactions Interface, by nature, bypass the otherwise applied SDE permissions in doing what it does?
Gavin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We would like to use AA to check for slopes of pipes. From what I've read and tried, this is not possible unless the inverts all have the same elevation, which is a situation I have never encountered in 18 years.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The configuration below is what I'm using to calculate the slopes, and it seems to be working well. I do admit that I'm still somewhat new to utility data, so it's possible I'm overlooking something important, but maybe this will still provide a good jumping-off point?
Fields Needed:
Manholes:
HIGHELEV (elevation of the invert into the manhole)
INVERTELEV (elevation of the invert leading out of the manhole)
Mains:
UPELEV (to be calculated)
DOWNELEV (to be calculated)
UPFIXED (if the upstream end of the main connects from a different invert than the INVERTELEV recorded in that manhole; useful for manholes that drain in two directions)
DOWNFIXED (if the downstream end of the main connects to a different invert than the HIGHELEV recorded in that manhole; useful for manholes with multiple incoming pipes)
SLOPE (to be calculated)
Rules (in order):
| Table Name | Field Name | Value Method | Value Info |
|---|---|---|---|
| Mains | UPELEV | FROM_JUNCTION_FIELD | INVERTELEV |
| Mains | DOWNELEV | FROM_JUNCTION_FIELD | HIGHELEV |
| Mains | UPELEV | EXPRESSION | UPFIXED |
| Mains | DOWNELEV | EXPRESSION | DOWNFIXED |
| Mains | SLOPE | EXPRESSION | round(((([UPELEV] - [DOWNELEV]) / [SHAPE_Length]) * 100), 2) |
If UPFIXED/DOWNFIXED are null, then they won't overwrite the previous calculations, resulting in a situation like so:
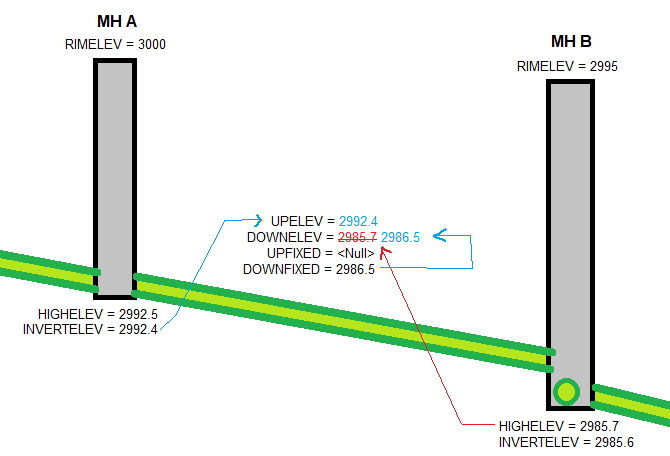
The main gets its UPELEV value from Manhole A's INVERTELEV, and (temporarily) the DOWNELEV from Manhole B's HIGHELEV. But that HIGHELEV is actually recording the elevation of a different pipe flowing into Manhole B (viewed in cross section here). So the elevation of this main's downstream end is recorded in the DOWNFIXED field, which overwrites the previous value (because this rule is applied after the first). Meanwhile, since there's no need for an UPFIXED value, the <Null> doesn't overwrite the initial UPELEV that was calculated.
Now just apply the slope calculation, and you're good to go. Hope this helps!