- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: using arcpy.da.walk to inventory data and expo...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
using arcpy.da.walk to inventory data and export metadata to csv
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm a novice when it comes to arcpy and am trying to develop a script that will use arcpy.da.walk to inventory our GIS data. As it goes through the folders/gdbs of data that we have, I want it to export a few items to a csv for each feature class (for now I'd be happy with feature class path, filename, spatial reference name and metadata purpose). I've gotten the script to work up until the metadata purpose part. Once I add the lines: my script does not return anything. Without those lines, I recieve a csv file with feature class path, filename, and spatial reference name, but if I include the lines my csv file is empty. No errors, just empty. My script (included below) is based off of: https://arcpy.wordpress.com/tag/os-walk/ and http://gis.stackexchange.com/questions/34729/creating-table-containing-all-filenames-and-possibly-me.... Any help is greatly appreciated! EDITED: Some feature classes may not have a spatial reference defined, and many feature classes may not have any metadata associated. I still want these in the csv, but those fields can either be blank or say something along the lines of "No spatial reference defined" and "No metadata purpose defined". |
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I converted this thread to a question (was a discussion) so eventually you will be able to mark it as answered.
I agree with Blake that you are headed in the right direction....but also make sure you export an attribute that you know will be in every metadata record like the title/name of the FC (if you are not already...haven't looked in detail at your latest version).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Well, I got it working. I tried inserting three if statements (1 for each metadata component), but it would only print my else value ("No Abstract") even if there was a value for the abstract. Instead, I inserted three try/except statements (again, 1 for each metadata component I was trying to grab) and it's working great! Thank you both for your help 
The only missing piece as far as I can tell is a known issue with arcpy.da.Walk, which is that it does not list rasters within gdb. I'm not sure why that's the case, but it only lists fc within the gdb even though it will list rasters that are within a folder. Not sure how to get around that. In a perfect world I would include an if statement somehow (if gdb ...arcpy.ListRasters) but I don't know where to start on that.
#This script uses arcpy.da.walk to inventory the data contained within a folder. It only captures feature classes, shapefiles and raster bands.
#For each feature class, shapefile or raster band it exports to a csv: file path, data name, data type, spatial reference name, metadata purpose, metadata abstract, and metadata publication date
#For those feature classes that are missing any of the metadata items, it prints "No Purpose", "No Abstract" and/or "No Publication Date".
#A known issue with this script is that it does not include rasters contained with .gdb (this is an issue with arcpy.da.walk). It may be able to be fixed with an if statement
#(something along the lines of "If gdb...arcpy.ListRasters") but I have not tried to do that.
#This script was created with the help of https://arcpy.wordpress.com/2012/12/10/inventorying-data-a-new-approach/ and https://community.esri.com/thread/30556
#Three variables need to be updated each time this script is run on a new workspace...those variables are commented below (outfile, xmlfile and workspace when calling inventory_data).
#Created 12/1/2016
#Created by: Shannon Groff
import os
import arcpy
import csv
from xml.etree.ElementTree import ElementTree
from arcpy import env
arcpy.env.overwriteOutput = True
def inventory_data(workspace, datatypes):
for path, path_names, data_names in arcpy.da.Walk(
workspace, datatype=datatypes):
for data_name in data_names:
yield os.path.join(path, data_name)
AGSHOME = arcpy.GetInstallInfo("Desktop")["InstallDir"]
translatorpath = AGSHOME + "Metadata\\Translator\\ARCGIS2FGDC.xml"
#These two variables need to be updated each time this script is run on a new workspace
outfile = r"C:\GIS\Records\Data Management\Inventories\GIS_Data_Inventory.csv"
xmlfile = r"C:\GIS\Records\Data Management\Inventories\Inventory\TempInventoryError\GIS_Data_Inventory.xml"
with open (outfile, 'wb') as csvfile:
csvwriter = csv.writer(csvfile)
#You need to update workspace in the line below
for feature_class in inventory_data(r"C:\GIS\Data\Natural_Environment\Species_and_Habitats\Species_Data", "FeatureClass"):
try:
desc = arcpy.Describe(feature_class)
sr = desc.spatialReference
arcpy.ExportMetadata_conversion(feature_class, translatorpath, xmlfile)
tree = ElementTree()
tree.parse(xmlfile)
spot = tree.find("idinfo/descript/purpose")
try:
purpose = tree.find("idinfo/descript/purpose").text
except:
purpose = "No Purpose"
try:
abstract = tree.find ("idinfo/descript/abstract").text
except:
abstract = "No Abstract"
try:
pubdate = tree.find ("idinfo/citation/citeinfo/pubdate").text
except:
pubdate = "No Publication Date"
csvwriter.writerow([desc.path.encode('utf-8'), desc.file.encode('utf-8'), desc.dataType.encode('utf-8'), sr.name.encode('utf-8'), purpose.encode('utf-8'), abstract.encode('utf-8'), pubdate.encode('utf-8')])
except Exception:
e = sys.exc_info()[1]
print(e.args[0])
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
another post that uses this code:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am trying to get all of the tags from the metadata, add them to a list, then convert the list to a comma-separated string to insert as a value in the excel.
sample xml:
<keywords> <theme> <themekt>None</themekt> <themekey>polygon</themekey> <themekey>area</themekey> <themekey>population</themekey> <themekey>boundaries</themekey> <themekey>households</themekey> <themekey>society</themekey> <themekey>demographics</themekey> <themekey>farming</themekey> </theme> <theme> <themekt>ISO 19115 Topic Categories</themekt> <themekey>society</themekey> <themekey>boundaries</themekey> <themekey>farming</themekey> </theme> <place> <placekt>None</placekt> <placekey>U.S. Counties</placekey> <placekey>United States</placekey> <placekey>Counties</placekey> </place> <temporal> <tempkt>None</tempkt> <tempkey>2002</tempkey> <tempkey>2004</tempkey> <tempkey>2010</tempkey> <tempkey>2012</tempkey> <tempkey>1992</tempkey> <tempkey>2011</tempkey> <tempkey>2013</tempkey> </temporal> </keywords>
Here is the code I have:
try: tagsListObjects = tree.findall("idinfo/keywords/theme/themekey") tagsList = [] for i in tagsListObjects: tagsList.append(i.text) tags = ','.join(map(str, tagsList)) except Exception as e: print (e) tags = "None"
Here is what the tagsListObjects looks like:
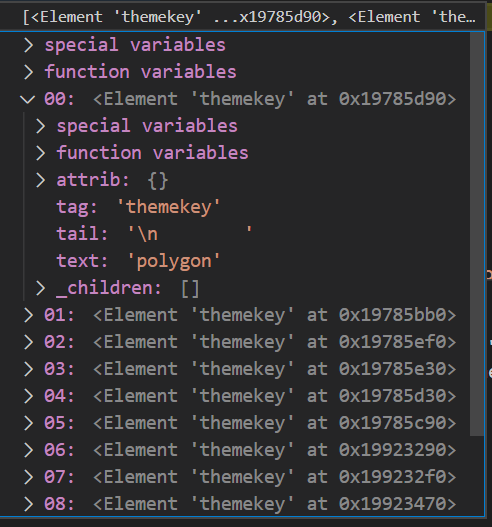
Unfortunately, the tagsList never gets anything appended, even though i.text has the appropriate text value.
A debug session takes me to line 5, then skips to the set the tags value as "None" without printing any error.
I know I will also be including place/placekey and temporal/tempkey in this string.
Any suggestions please?
Reference:
XML parsing in Python - GeeksforGeeks
how to recursively iterate over XML tags in Python using ElementTree? - Stack Overflow
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This was what got it to work:
try:
tagsListObjects = tree.findall("idinfo/keywords/theme/themekey")
tagsList = []
for i in tagsListObjects:
# themekey = i.find('/theme/themekey').text
# placekey = i.find('place/placekey').text
# temporalkey = i.find('temporal/tempkey').text
if i.text:
tagsList.append(i.text)
if tagsList:
tags = ', '.join(map(str, tagsList))
else:
tags = 'There are no tags for this item.'
except Exception as e:
print (e)
tags = "None"I'm still thinking how I will get at 'idinfo/keywords' _children's _children's
tree.findall("idinfo/keywords") returns the grandparent:
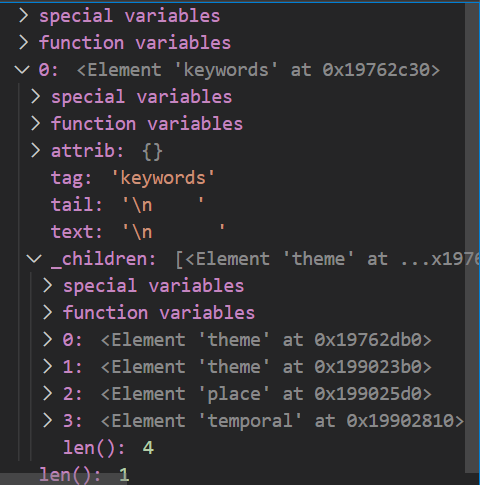
Any suggestions on this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Andres Castillo,
You should really post a new question for this. I'm still a bit unclear what you're asking.
- « Previous
-
- 1
- 2
- Next »
- « Previous
-
- 1
- 2
- Next »