- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- sql_clause in arcpy.da.SearchCursor is NOT honori...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
sql_clause in arcpy.da.SearchCursor is NOT honoring "ORDER BY"
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am working on a script that is attempting to use ORDER BY. The results I'm seeing are unordered. I've dug quite a bit in GeoNet and elsewhere to no avail. My data is in a FGBD, my understanding is ORDER BY should work...
I'm hoping that there is something wrong with the logic in my script, and someone might help me identify it.
In a nutshell the script selects a group of features based on FEAT_SEQ, the selection is then sorted by a RANK field (NOT WORKING), the first row is then written to a new feature class. All of this is working except for the ordering. The output simply writes the first row, unsorted.
- The TableSelect, selects features in a FC by the FEAT_SEQ field. The FEAT_SEQ is a result of the identify duplicate tool.
- This selection is intended to be "sorted" by the ORDER BY using the SearchCursor
- Finally the first row is written to a new FC
Seq_Count = 0 #counter for FEAT_SEQ selection
for i in range(5): #loop - range 7631 (all)? for full run
Seq_Count = Seq_Count + 1 # adds 1 to Seq_Count
Where = "FEAT_SEQ =" + str(Seq_Count) #sets sql expreassion to Seq_Count #
print("Looping Seq #" + str(Seq_Count)) # prints Seq_Count # for ref.
arcpy.TableSelect_analysis(DUPES, Out, Where) # selects
#print("Selection Complete - saved to cleanscript.gdb/SelSection") # loop done
### load selection from previous output, evalute winner, save winner to winnigselection
with arcpy.da.SearchCursor(Out, field_names = fieldnames, sql_clause = (None, 'ORDER BY RANK')) as searchCursor: #orders search by ranked
with arcpy.da.InsertCursor(winnerTable, fieldnames) as iCur:
row = next(searchCursor) #goes to first row (previouly ordered by rank)
#print(row)
iCur.insertRow(row)
#print("insert complete")
#del iCur #seems like you do this for housekeeping
#del searchCursor #seems like you do this for housekeeping
result = arcpy.GetCount_management(winnerTable) #counts output to winnerTable
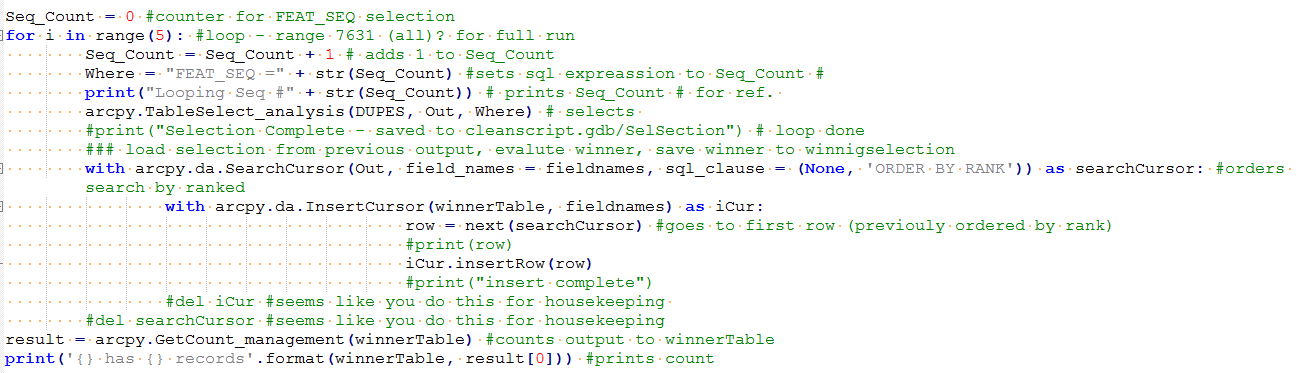
print('{} has {} records'.format(winnerTable, result[0])) #prints countThe sql_clause is on line 9 (shown below)
with arcpy.da.SearchCursor(Out, field_names = fieldnames, sql_clause = (None, 'ORDER BY RANK')) as searchCursor:screenshot of same code (in case it is easier to read)
Thanks in advance for any insights anyone has to offer!
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Your problem is this line:
Out = r"in_memory/Selection" In-memory workspaces, both the legacy in_memory and newer memory, are not full-fledged geodatabases. The newer memory workspace does support more geodatabase functionality than the older in_memory, but Esri doesn't clearly document all the improvements in the newer workspace.
I did some quick testing, and SQL ORDER BY is honored using the newer memory workspace. If you aren't using ArcGIS Pro already, I encourage you to switch and also switch to using the newer in-memory workspace.
See Write geoprocessing output to memory—ArcGIS Pro | Documentation :
Write geoprocessing output to memory
Writing geoprocessing outputs to memory is an alternative to writing output to a geodatabase or file-based format. It is often significantly faster than writing to on-disk formats. Data written into memory is temporary and is deleted when the application is closed, so it is an ideal location to write intermediate data created in a ModelBuilder model or Python script.
Memory-based workspaces
ArcGIS provides two memory-based workspaces where geoprocessing outputs can be written.
Caution:
- Memory-based workspaces do not support geodatabase elements such as feature datasets, representations, topologies, geometric networks, or network datasets.
- Folders cannot be created in memory-based workspaces.
- Since memory-based workspaces are stored in your system's physical memory, or RAM, your system may run low on memory if you write large datasets into the workspace. This can negatively impact processing performance.
memory
memory is a new memory-based workspace developed for ArcGIS Pro that supports output feature classes, tables, and raster datasets.
To write to the memory workspace, specify an output dataset path beginning with memory\ and including no file extension—for example, memory\tempOutput.
You can add memory datasets to a map in ArcGIS Pro.
in_memory
Legacy:
in_memory is the legacy memory-based workspace built for ArcMap that supports output feature classes, tables, and raster datasets.
To write to the in_memory workspace, specify an output dataset path beginning with in_memory\ and including no file extension—for example, in_memory\tempOutput.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
If you can share a subset of data, that is most helpful. If not, can you create an example data set that generates the same behavior?
Looking at the code, where is "Out" being defined? And, for troubleshooting, take the loop out of it. Get the code working with a single FEAT_SEQ and then introduce the loop.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Good Idea Joshua Bixby. I've removed the loop and I'm seeing the same result. I'm attaching the GDB and the script. Lines 13, 18, and 20 will need to be re-pathed to your workspace to function. Out is defined in line 20.
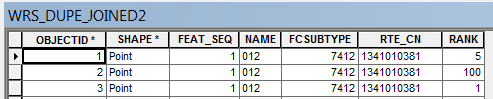

As you can see above for FEAT_SEQ = 1, the row rank 5 (the first row) is being written. If it were ordered I'd expect the values of 1 to be written, or 100 if it were somehow reversed.
I'll put the code below as well for ref.
#### Wesley Garrett - 20200715
# script selects items based on feat_seq, exports to a feature class, that feature class is sorted and the top rank is selected & written to the winner feature class
# used in modernization / label table to eliminate duplicate instances of fcsubtypes, chooses higheest ranked
# duplicates must be indentified prior (using find identical tool) uses FEAT_SEQ
# rank and rank field must be calculated / created prior (Expression_rank_fcsubtype_alltypes.cal) uses RANK (use python parser)
######################
print ("Loading Arcpy...")
import arcpy
print ("Setting Environment...")
from arcpy import env
env.workspace = r"T:\FS\NFS\WOEngineering\GMO-GTAC\Project\DDC\Workspace\wdgarrett\roadsshield\cleanscript.gdb"
arcpy.env.overwriteOutput = 1
print("loading paths...")
DUPES = r"T:\FS\NFS\WOEngineering\GMO-GTAC\Project\DDC\Workspace\wdgarrett\roadsshield\cleanscript.gdb\WRS_DUPE_JOINED2" # table to be clenaed
Out = r"in_memory/Selection" #to improve speed
winnerTable = r"T:\FS\NFS\WOEngineering\GMO-GTAC\Project\DDC\Workspace\wdgarrett\roadsshield\cleanscript.gdb\winnerTable" # winner output (uses copy of Dupes to start) Schema of DUPES and winnerTable need to match
#copies DUPES to winnerTable for output
arcpy.Copy_management(DUPES, winnerTable)
print("Copy for winnerTable")
#clean winnerTable prior to run
arcpy.TruncateTable_management(winnerTable)
print("winnerTable Cleared")
#get fields names and assign to fields
dsc = arcpy.Describe(DUPES)
fields = dsc.fields
print("DUPES Fields")
for field in dsc.fields:
print "%-22s %s %s" % (field.name, ":", field.type)
#print field.name + " = " + field.type
print("WinnerTable Fields")
dscwinner = arcpy.Describe(winnerTable)
for field in dscwinner.fields:
print "%-22s %s %s" % (field.name, ":", field.type)
#print field.name + " = " + field.type
out_fields = [dsc.OIDFieldName, dsc.shapeFieldName] #fields to not include this could include length etc. if not using tables
fieldnames = [field.name if field.name != 'Shape' else 'SHAPE@' for field in fields if field.name not in out_fields]
print("Out Fields")
print(out_fields)
print("Field Names")
print(fieldnames)
Seq_Count = 0
Seq_Count = Seq_Count + 1 # adds 1 to Seq_Count
Where = "FEAT_SEQ =" + str(Seq_Count) #sets sql expreassion to Seq_Count #
arcpy.TableSelect_analysis(DUPES, Out, Where) # selects
### load selection from previous output, evalute winner, save winner to winnertable
with arcpy.da.SearchCursor(Out, field_names = fieldnames, sql_clause = (None, 'ORDER BY RANK')) as searchCursor: #orders search by ranked
with arcpy.da.InsertCursor(winnerTable, fieldnames) as iCur:
row = next(searchCursor) #goes to first row (previouly ordered by rank)
print(row)
iCur.insertRow(row)
result = arcpy.GetCount_management(winnerTable) #counts output to winnerTable
print('{} has {} records'.format(winnerTable, result[0])) #prints count
print("End / Done")
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am slightly at loss why you don't feed the SQL clause used in the "Table Select" tool directly into the arpy.da.SearchCursor. If I am right, this should just work and give the same results, and maybe then the ORDER BY will work as well, as there is an actual SQL clause to combine it with.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Your problem is this line:
Out = r"in_memory/Selection" In-memory workspaces, both the legacy in_memory and newer memory, are not full-fledged geodatabases. The newer memory workspace does support more geodatabase functionality than the older in_memory, but Esri doesn't clearly document all the improvements in the newer workspace.
I did some quick testing, and SQL ORDER BY is honored using the newer memory workspace. If you aren't using ArcGIS Pro already, I encourage you to switch and also switch to using the newer in-memory workspace.
See Write geoprocessing output to memory—ArcGIS Pro | Documentation :
Write geoprocessing output to memory
Writing geoprocessing outputs to memory is an alternative to writing output to a geodatabase or file-based format. It is often significantly faster than writing to on-disk formats. Data written into memory is temporary and is deleted when the application is closed, so it is an ideal location to write intermediate data created in a ModelBuilder model or Python script.
Memory-based workspaces
ArcGIS provides two memory-based workspaces where geoprocessing outputs can be written.
Caution:
- Memory-based workspaces do not support geodatabase elements such as feature datasets, representations, topologies, geometric networks, or network datasets.
- Folders cannot be created in memory-based workspaces.
- Since memory-based workspaces are stored in your system's physical memory, or RAM, your system may run low on memory if you write large datasets into the workspace. This can negatively impact processing performance.
memory
memory is a new memory-based workspace developed for ArcGIS Pro that supports output feature classes, tables, and raster datasets.
To write to the memory workspace, specify an output dataset path beginning with memory\ and including no file extension—for example, memory\tempOutput.
You can add memory datasets to a map in ArcGIS Pro.
in_memory
Legacy:
in_memory is the legacy memory-based workspace built for ArcMap that supports output feature classes, tables, and raster datasets.
To write to the in_memory workspace, specify an output dataset path beginning with in_memory\ and including no file extension—for example, in_memory\tempOutput.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks so much! That was the problem. I switched to outputting to a GDB for the selection and everything worked as it should. Unfortunately I can't use Pro for this in the long run. We don't have the option at this time for enterprise applications.
Good new though, it is working, albeit a little slower than it's already snails pace.
Thanks again!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
When I see a workflow using cursors in loops, more often than not there is a better/quicker workflow that leads to the same results. If I understand what you are trying to do, it is very similar to what someone asked in Rank features by Field A for each unique value in Field B . The code I provided in that thread was adapted from Deleting records from tabular intersect table based on 'PERCENTAGE' field .
I made a copy of the WRS_DUPE_JOINED2 and ran the following code, which ran in a few seconds, and I think provides the results you are looking for here.
from arcpy.da import UpdateCursor
from itertools import groupby
from operator import itemgetter
fc = # path to feature class
case_fields = ["FEAT_SEQ"]
sort_field, sort_dir = "RANK", "ASC"
sql_orderby = "ORDER BY {}, {} {}".format(
", ".join(case_fields),
sort_field,
sort_dir
)
with UpdateCursor(fc, "*", sql_clause=(None, sql_orderby)) as cur:
case_func = itemgetter(
*(cur.fields.index(fld) for fld in case_fields)
)
for key, group in groupby(cur, case_func):
row = next(group)
for row in group:
cur.deleteRow()- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Wow! That ran in ~10 seconds. A much better solution. I had been running my version prior, after 2.5 hours it had barely broken 1000 records. I would have been waiting 500+ hours (20 days).
Much appreciated!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Josh! I'll give that a try.