- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Data Access Module: Update Cursor (Not Updating Re...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Data Access Module: Update Cursor (Not Updating Records)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I've written a Python function that is meant to update a File Geodatabase Table (Landuse) based on a Feature Class (Watershed). I'm using a Update Cursor to update each field value where it finds a match within a Python Dictionary of HydroID and in return I use the "Shape_Area" as part of my calculations to update each field value.
There are eight landuse fields that I want to update using the same formula for each HydroID match:
- Commercial_Forestry
- Cultivated
- Indigenous
- Mines
- Natural_Vegetation_Forest
- Urban
- Waterbodies
- Wetlands
So instead of specifying each field through its index position manually, I step into a for loop and loop through each field updating the field value based on the formula. The problem that I'm having is that the Update Cursor is not updating the rows, although I'm calling updateRow() afterwards.
Is there anyway I can get around the following without having to specify each field through its index position manually?
# calculate percentage of landuse per watershed
def landuse_percentage(watershed, output_pivot):
watershed_fields = ["HydroID", "Shape_Area"]
valuedict = {r[0]: (r[1:]) for r in arcpy.da.SearchCursor(watershed, watershed_fields)} # @UndefinedVariable
landuse_fields = [f.name for f in arcpy.ListFields(output_pivot)[1:]]
print(landuse_fields)
with arcpy.da.UpdateCursor(output_pivot, landuse_fields) as upcur: # @UndefinedVariable
for row in upcur:
keyvalue = row[0]
if keyvalue in valuedict:
print(keyvalue)
for landuse in row[1:]:
landuse = (landuse*(30*30))/(valuedict[keyvalue][0])*100
upcur.updateRow(row)
print(landuse)
landuse_percentage(watershed, output_pivot)Python Code: for loop over each field
12366 (HydroID)
- 0.962788133178 - (Landuse percentage based on Shape Area)
- 62.0189203295
- 31.8703202065
- 0.123498273168
- 13.8522293032
- 1.24419729078
- 1.02530804735
- 2.19975286437
Python Console: Correct Values printed but table not updated.
# calculate percentage of landuse per watershed
def landuse_percentage(watershed, output_pivot):
watershed_fields = ["HydroID", "Shape_Area"]
valuedict = {r[0]: (r[1:]) for r in arcpy.da.SearchCursor(watershed, watershed_fields)} # @UndefinedVariable
landuse_fields = [f.name for f in arcpy.ListFields(output_pivot)[1:]]
with arcpy.da.UpdateCursor(output_pivot, landuse_fields) as upcur: # @UndefinedVariable
for row in upcur:
keyvalue = row[0]
if keyvalue in valuedict:
row[1] = (row[1]*(30*30))/(valuedict[keyvalue][0])*100
row[2] = (row[2]*(30*30))/(valuedict[keyvalue][0])*100
row[3] = (row[3]*(30*30))/(valuedict[keyvalue][0])*100
row[4] = (row[4]*(30*30))/(valuedict[keyvalue][0])*100
row[5] = (row[5]*(30*30))/(valuedict[keyvalue][0])*100
row[6] = (row[6]*(30*30))/(valuedict[keyvalue][0])*100
row[7] = (row[7]*(30*30))/(valuedict[keyvalue][0])*100
row[8] = (row[8]*(30*30))/(valuedict[keyvalue][0])*100
upcur.updateRow(row)
landuse_percentage(watershed, output_pivot)Python Code: specifying index position of each field manually.
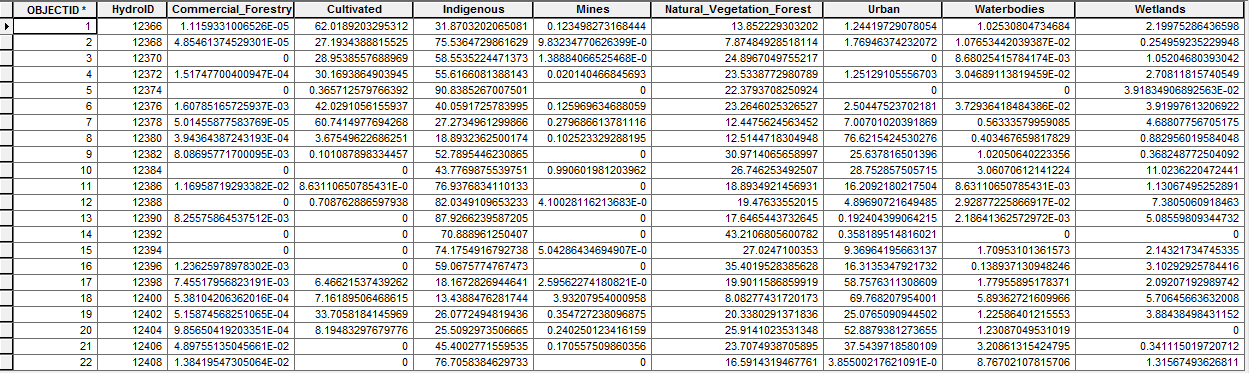
Landuse: Updated Table using second Python Function
So any help how to loop through each each instead of having to manually specify the index position will be appreciated.
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The built-in enumerate function is what you want:
with arcpy.da.UpdateCursor(output_pivot, landuse_fields) as upcur: # @UndefinedVariable for row in upcur: keyvalue = row[0] if keyvalue in valuedict: print(keyvalue) for i, landuse in enumerate(row[1:], 1): row = (landuse*(30*30))/(valuedict[keyvalue][0])*100 upcur.updateRow(row) print(row)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The built-in enumerate function is what you want:
with arcpy.da.UpdateCursor(output_pivot, landuse_fields) as upcur: # @UndefinedVariable for row in upcur: keyvalue = row[0] if keyvalue in valuedict: print(keyvalue) for i, landuse in enumerate(row[1:], 1): row = (landuse*(30*30))/(valuedict[keyvalue][0])*100 upcur.updateRow(row) print(row)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Luke
The following worked perfectly, thanks  . Would you mind helping me understand why my original for loop didn't work as the printed results within the console were correct?
. Would you mind helping me understand why my original for loop didn't work as the printed results within the console were correct?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Peter Wilson wrote:
Would you mind helping me understand why my original for loop didn't work as the printed results within the console were correct?
Because you were modifying the landuse variable, not the row elements. Basically this is what you were doing
row = ['a','b'] for i, landuse in enumerate(row): landuse = landuse + "x" print landuse, row
ax a bx b
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Luke
Thanks so much, now I understand where I was going wrong, much appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Could you share a small part of your data to see if we can reproduce the problem? I would like to see what is happening...
For not having to specify the index manually you could do something like this.
for i in range(1, len(landuse_fields) + 1): row = (row*(30*30))/(valuedict[keyvalue][0])*100
... or perhaps you like the index of the field name in the list of fields better:
for fld_name in landuse_fields: i = landuse_fields.index(fld_name) row = (row*(30*30))/(valuedict[keyvalue][0])*100
However, this is no explanation for not updating the fields in the updatecursor. I normally prefer not to overwrite values i the fields (areas to percentage), for problems that will happen when a script is run more than once
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Xander
Thanks for the following, you are correct that I generally also don't update the original field values based on the calculations, due to bugs or errors. The landuse table that I have used is a output from Zonal Histogram that represents the number of cells for each landuse within each watershed. The following is generated within a separate function just before the following, so the risk of the values being overwritten is managed.