- Home
- :
- All Communities
- :
- Developers
- :
- Python
- :
- Python Questions
- :
- Re: Arcpy - search duplicate attributes, then upda...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Arcpy - search duplicate attributes, then update values
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi all,
Could someone point me in the right direction.
I have limited python scripting experience but know a enough (to be dangerous).
This is what I want to do.
I have a shapefile which has duplicate objects based on an "ID".
Object1: ID1 + Owner1
Object2: ID1 + Owner2
Object3: ID1 + Owner3
in this example there are 3 objects with identical ID but with 3 different owners for the same object.
What I want to do is search through the shapefiles for all identical "ID", then update a new shapefile with :
Object1: ID1 + Owner1 + Owner2 + Owner3
The new shapefile would have 3 extra columns added for the Owner field to be updated to.
so I want 1 object only but keep the owner information in the row.
thanks,
Tim
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is what I came up with:
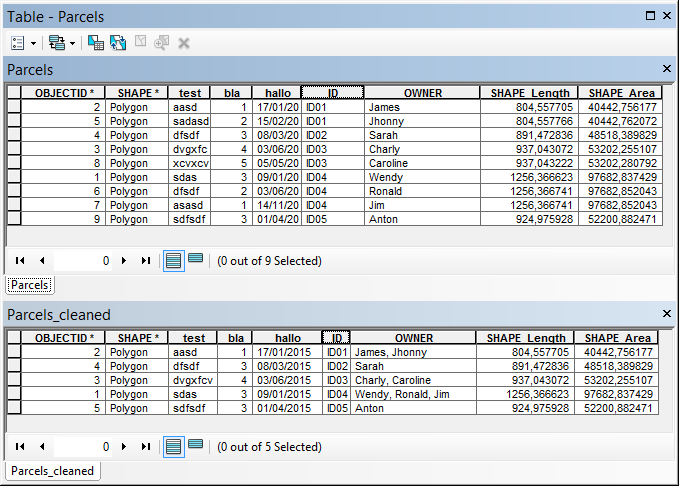
Upper table is the input featureclass, the lower table is the result (cleaned)
Using this code:
def main():
import arcpy
import os
fc_in = r"D:\Xander\GeoNet\RemoveDuplicates\test.gdb\Parcels"
fc_out = r"D:\Xander\GeoNet\RemoveDuplicates\test.gdb\Parcels_cleaned"
fld_id = "ID"
fld_owner = "OWNER"
sr = arcpy.Describe(fc_in).spatialReference
# create empty output fc
fc_ws, fc_name = os.path.split(fc_out)
arcpy.CreateFeatureclass_management(fc_ws, fc_name, template=fc_in, spatial_reference=sr)
# create dictionary with ID's te keep and related owners
flds = (fld_id, fld_owner)
dct = {}
with arcpy.da.SearchCursor(fc_in, flds) as curs_in:
for row_in in curs_in:
p_id = row_in[0]
p_owner = row_in[1]
if p_id in dct:
dct[p_id] += ", {0}".format(p_owner)
else:
dct[p_id] = p_owner
del row_in, curs_in
# now do the update:
flds = correctFieldList(arcpy.ListFields(fc_out))
with arcpy.da.InsertCursor(fc_out, flds) as curs_out:
with arcpy.da.SearchCursor(fc_in, flds) as curs_in:
# flds_in = curs_in.fields
for row_in in curs_in:
lst_row = list(row_in)
p_id = row_in[flds.index(fld_id)]
if p_id in dct:
owners = dct[p_id]
lst_row[flds.index(fld_owner)] = owners
print lst_row
# remove from dct
tmp = dct.pop(p_id)
curs_out.insertRow(tuple(lst_row))
def correctFieldList(flds):
flds_use = ['Shape@']
fldtypes_not = ['Geometry', 'Guid', 'OID']
for fld in flds:
if not fld.type in fldtypes_not:
flds_use.append(fld.name)
return flds_use
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Tim,
Have you had a look at the find identical tool
I would run the tool to find features that have duplicates and then with the created table use this to help populate your new shape file
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
So what would happen if the same ID had five different owners? Or ten different owners? You'll just have to keep increasing the number of columns to accommodate the most duplicated ID. Sounds like these are not duplicates but rather you have two key fields. I wouldn't try making extra columns for the additional owners because it will get messy. Is there some kind of dependency requiring you to format your data like this?
In your example, do each of the three objects also have different geometry/location? If the geometry is the same, maybe you could consider using a related table so you can have one object with one ID related to an owner table that has three records with the same ID and each different owner.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I think Blakes suggestion is best for this kind of data scenario. But if you still want to keep the kind of data structure you have, which is stacked polygons due to multiple owner, I don't get why the need to go through the process of modifying your data. If you are just after a report like info of how many and who are the owners of each polygon based on ID, you just write a script to spit out a csv file which does that summary and leave your data intact. That's just my two cents.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for the replies.
In this case Blake, there will only ever be 9 Owners (max).
The way I was thinking would be to create a new table with the structure I want.
Loop thru the data to get a list of Unique ID+Owner
Then populate the Owners field in the new table with the list of data.
The same IDs have identical geometry.
Thanks,
Tim
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
At first you mentioned you want the results in a shapefile but now you're saying you want a "list." If some kind of printed report is really what you're after, you could try this:
import arcpy inputTable = r"C:\temp\myworking.gdb\mytablename" fields = ["ID","OWNER"] uniqueID = {} with arcpy.da.SearchCursor(inputTable, fields) as s_cursor: for row in s_cursor: # Underscore in front of variable names only because "id" is a Python reserved word _id = row[0] _owner = row[1] uniqueID.setdefault(_id, []).append(_owner) for _id, _owners in uniqueID.items(): print _id, _owners
It uses an arcpy data access search cursor to read through your data table one row at a time. With each row, it loads the ID and owner into a dictionary (like Geoff Olson mentioned below). However, as each row is loaded, the dictionary setdefault method checks to see if that ID has already been loaded. If it has not, it will create a new dictionary key for that ID and an empty list for the dictionary value. The list append method is the one that actually adds the owner to the list. You're left with a dictionary that has keys of only unique IDs and values as a list of owners. It just prints the results to the Python interpreter window. You could also write the data to a CSV or a new feature class or shapefile.
Here's the credit for the logic I used to populate the dictionary.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I'm in the same boat as you with being a novice with Python scripting. My lastest phase of attribute manipulation has been with using dictionaries to use a one (key) to multiple (value list) data entry. I dont' know how you have your data structured, but using dictionary indices can access the particular values you want. You could probably create a row dictionary and update a dictionary of the dataset to reference for assigning the owners where you want the information to go.
rowDict = {rowID : [Owner1, Owner2, Owner3]}
fullDict.update(rowDict)
Then you can pull your owners out again
fullDict.keys().index(rowID)#this returns the index location of the key
fullDict.values()[fullDict.keys().index(rowID)]#this returns the owners for the row
You can pull each owner from the returned list about and an additional index
fullDict.values()[fullDict.keys().index(rowID)][1]
Here's an example
rowID = 76
Owner1 = "John"
Owner2 = "Sally"
Owner3 = "George"
rowDict = {rowID : [Owner1, Owner2, Owner3]}
fullDict = dict()
fullDict.update(rowDict)#updates the row of information to the full dictionary
fullDict.keys().index(rowID)#returns the owners' names
fullDict.keys().index(rowID)[1]#returns the owner's name of the second owner in the listthe second owner in the list
If the owners names are in separate objects, it's possible to update the dictionary to add the other owners names. The only way to do that is with dict.update() and the new dictionary values has to have the same key as what it's overwriting and the values then need to be a list of the owners from all the objects.
a.update({a.keys()[indexForRow_ID_For_A]:[a.values()[indexForRow_ID_For_A], b.values()[indexForRow_ID_For_B], c.values()[indexForRow_ID_For_C]]})
This would take the key value from A and update the values with the values from A, B, and C.
Like I said, my knowledge of Python is still in the novice section. If I understand what your trying to do, then perhaps dictionaries can help. I hope this helps in some way.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks Geoff,
I’ll have a play around with this approach!
Yeah I was hoping to loop through the data and create a “list” of ID+Owner for the dataset.
Then update a new field using this data.
Thanks,
Tim
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is what I came up with:
Upper table is the input featureclass, the lower table is the result (cleaned)
Using this code:
def main():
import arcpy
import os
fc_in = r"D:\Xander\GeoNet\RemoveDuplicates\test.gdb\Parcels"
fc_out = r"D:\Xander\GeoNet\RemoveDuplicates\test.gdb\Parcels_cleaned"
fld_id = "ID"
fld_owner = "OWNER"
sr = arcpy.Describe(fc_in).spatialReference
# create empty output fc
fc_ws, fc_name = os.path.split(fc_out)
arcpy.CreateFeatureclass_management(fc_ws, fc_name, template=fc_in, spatial_reference=sr)
# create dictionary with ID's te keep and related owners
flds = (fld_id, fld_owner)
dct = {}
with arcpy.da.SearchCursor(fc_in, flds) as curs_in:
for row_in in curs_in:
p_id = row_in[0]
p_owner = row_in[1]
if p_id in dct:
dct[p_id] += ", {0}".format(p_owner)
else:
dct[p_id] = p_owner
del row_in, curs_in
# now do the update:
flds = correctFieldList(arcpy.ListFields(fc_out))
with arcpy.da.InsertCursor(fc_out, flds) as curs_out:
with arcpy.da.SearchCursor(fc_in, flds) as curs_in:
# flds_in = curs_in.fields
for row_in in curs_in:
lst_row = list(row_in)
p_id = row_in[flds.index(fld_id)]
if p_id in dct:
owners = dct[p_id]
lst_row[flds.index(fld_owner)] = owners
print lst_row
# remove from dct
tmp = dct.pop(p_id)
curs_out.insertRow(tuple(lst_row))
def correctFieldList(flds):
flds_use = ['Shape@']
fldtypes_not = ['Geometry', 'Guid', 'OID']
for fld in flds:
if not fld.type in fldtypes_not:
flds_use.append(fld.name)
return flds_use
if __name__ == '__main__':
main()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
many thanks!
this works.
The only issue I had was the original shp file "owner" field had a size of 60 characters...
So when the update occurred on the new field (60 characters) it was truncating the result.
Is there a way to alter the field sizes of an existing field in arcpy?
or do you have to create a new field?
thanks to all those who replied.
Tim