- Home
- :
- All Communities
- :
- Products
- :
- Mapping
- :
- Mapping Questions
- :
- Re: labeling a layer with the values of stand-alon...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
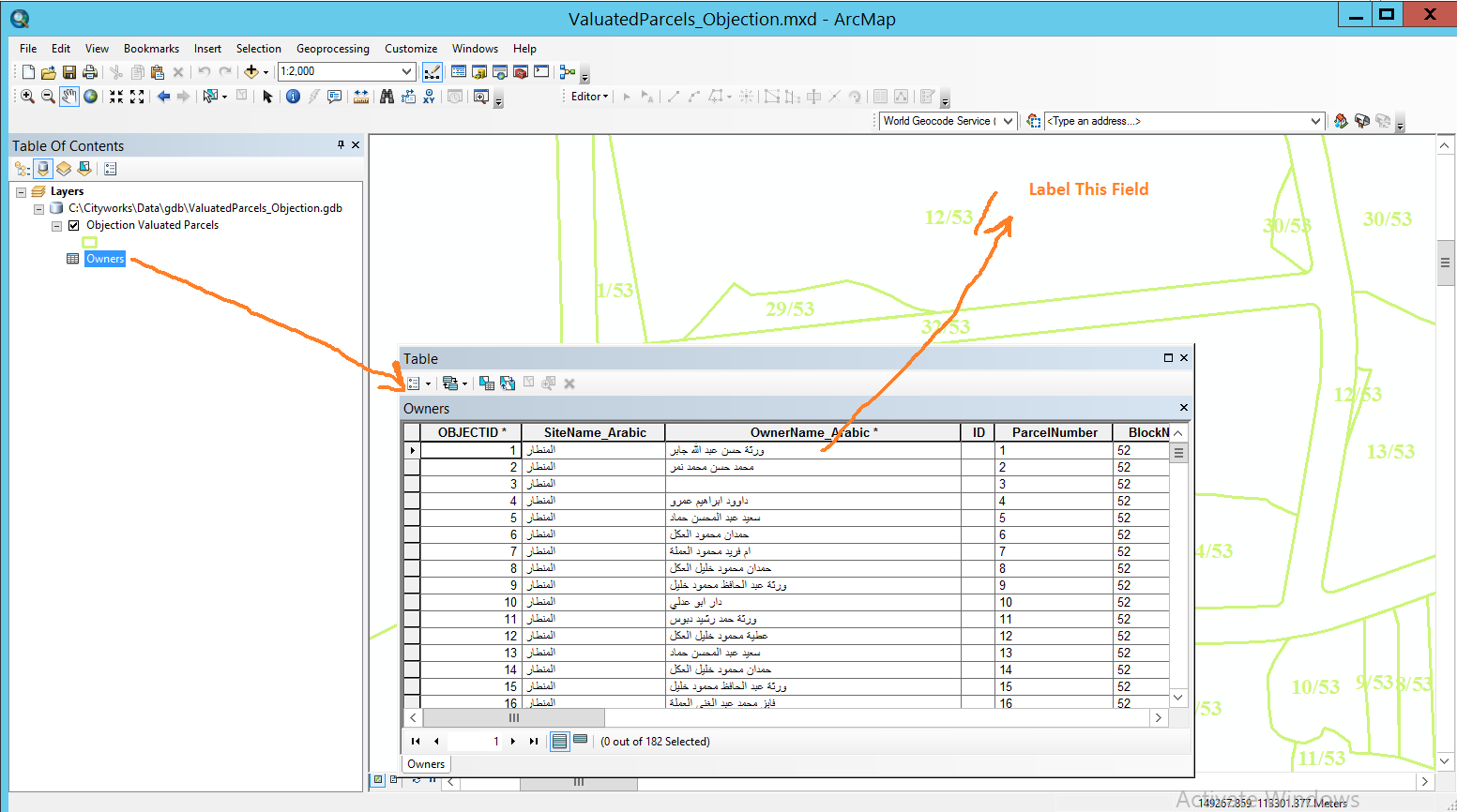
labeling a layer with the values of stand-alone table (that is associated to the layer with 1-Many relationship),
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi All,
I wondering how could we labeling a layer with the values of stand-alone table (that is associated to the layer with 1-Many relationship),
For example, I wanted to label the parcels with their owners knowing that the parcel layer is associated with owners table with 1-Many relationship.
What might be the best practice to perform this task?
Thanks in advance,
Rawan
Solved! Go to Solution.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I have commented out line 31 and line 43. Line 31 was indented wrong and causing it to interfere with the label generation beyond the first label, so I indebted it one more level (11/24/16 at 9:11 AM Pacific time). Line 43 creates a count that you apparently do not want, except where no owners exist I assume. Try this code:
# Initialize a global dictionary for a related feature class/table
relateDict = {}
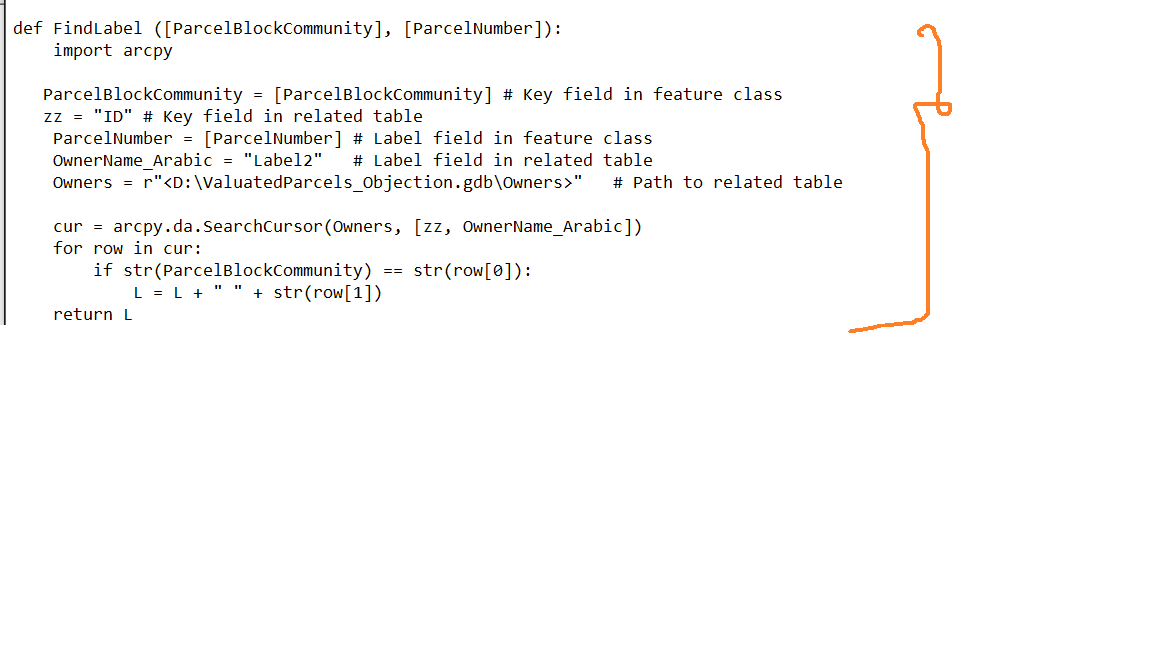
def FindLabel ( [ParcelBlockCommunity], [ParcelNumber] ):
# declare the dictionary global so it can be built once and used for all labels
global relateDict
# only populate the dictionary if it has no keys
if len(relateDict) == 0:
# Provide the path to the relate feature class/table
relateFC = r"C:\Users\main\Documents\ArcGIS\ValuatedParcels_Objection.gdb\Owners"
# create a field list with the relate field first (ParcelBlockCommunity),
# followed by sort field(s) (ParcelNumber), then label field(s) (OwnerName_Arabic)
relateFieldsList = ["ParcelBlockCommunity", "OwnerName_Arabic"]
# process a da search cursor to transfer the data to the dictionary
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
# store the key value in a variable so the relate value
# is only read from the row once, improving speed
relateKey = relateRow[0]
# if the relate key of the current row isn't found
# create the key and make it's value a list of a list of field values
if not relateKey in relateDict:
# [searchRow[1:]] is a list containing
# a list of the field values after the key.
relateDict[relateKey] = [relateRow[1:]]
else:
# if the relate key is already in the dictionary
# append the next list of field values to the
# existing list associated with the key
relateDict[relateKey].append(relateRow[1:])
# delete the cursor, and row to make sure all locks release
del relateRows, relateRow
# store the current label feature's relate key field value
# so that it is only read once, improving speed
labelKey = [ParcelBlockCommunity]
# start building a label expression.
# My label has a bold key value header in a larger font
expression = u'<FNT name="Times New Roman" size="14"><BOL>' + [ParcelNumber] + '</BOL></FNT>'
# determine if the label key is in the dictionary
if labelKey in relateDict:
# sort the list of the list of fields
sortedList = sorted(relateDict[labelKey])
# add a record count to the label header in bold regular font
# expression += u'\n<FNT name="Times New Roman" size="10"><BOL>Owner Count = {}</BOL></FNT>'.format(len(sortedList))
# process the sorted list
for fieldValues in sortedList:
# append related data to the label expression
# my label shows a list of related
# cross streets and measures sorted in driving order
expression += u'\n' + fieldValues[0]
# clean up the list variables after completing the for loop
del sortedList, fieldValues
else:
expression += '\n<FNT name="Arial" size="10"><BOL>Owner Count = 0</BOL></FNT>'
# return the label expression to display
return expressionThis code separates each owner into its own line separated by a hard return. If you want more than one owner listed per line you will have to define the maximum number of characters you will allow per line and modify the loop at lines 45 to 49 to handle that format, but I am not prepared to suggest code that will accomplish that. You should request help with that in a separate post or on a Python forum.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
No 'out-of-the-box' functionality. But you might be able to do it using python How To: Label a related table
Think Location
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
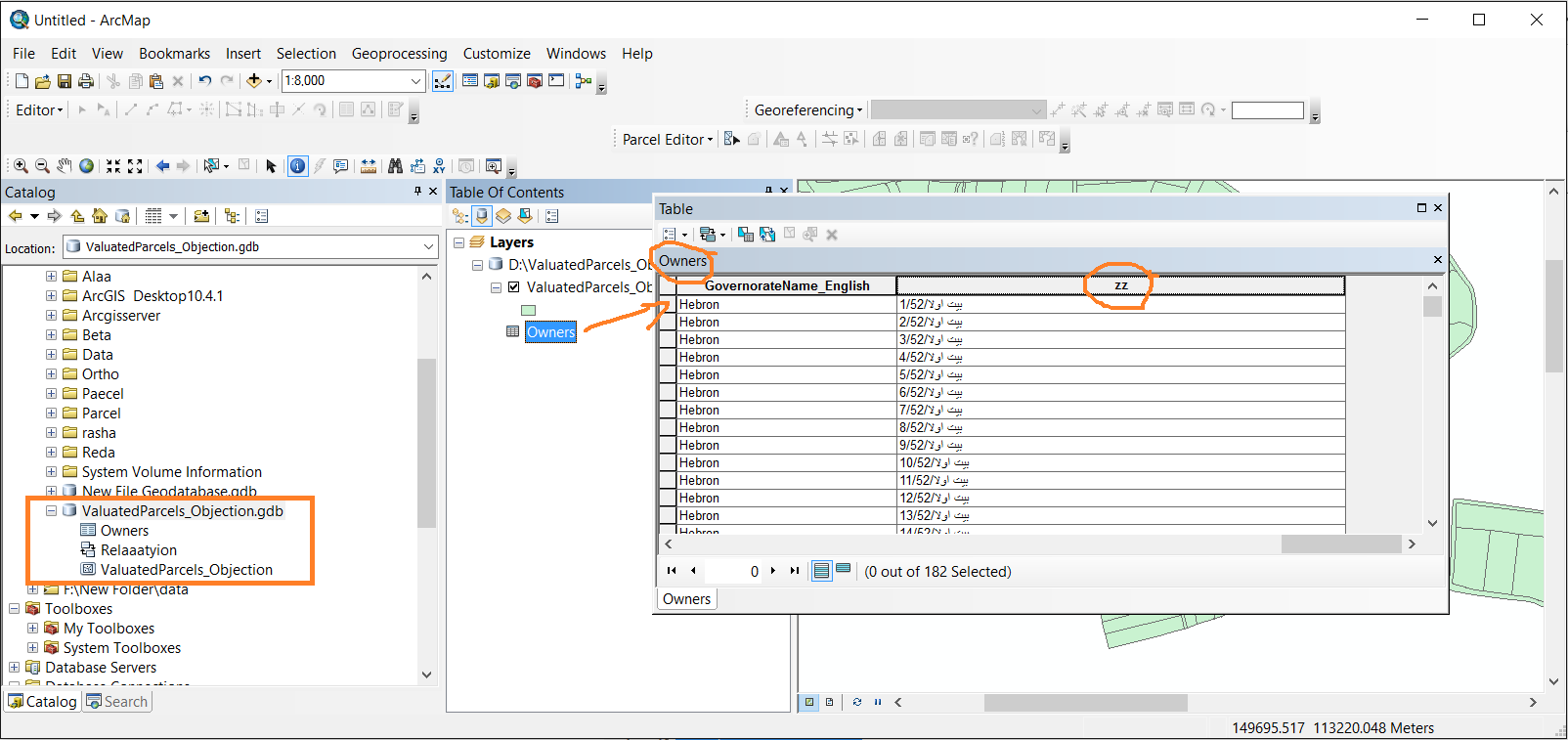
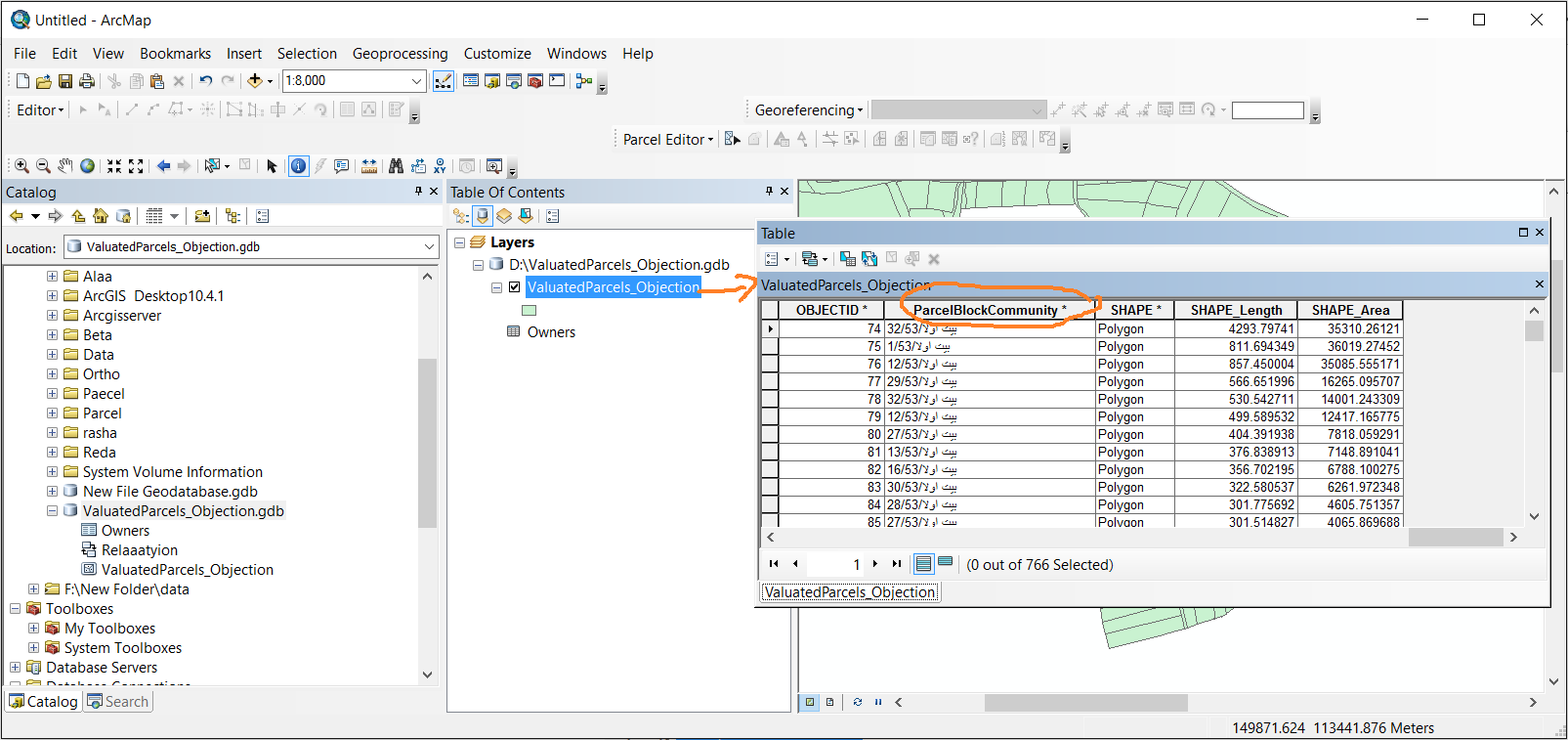
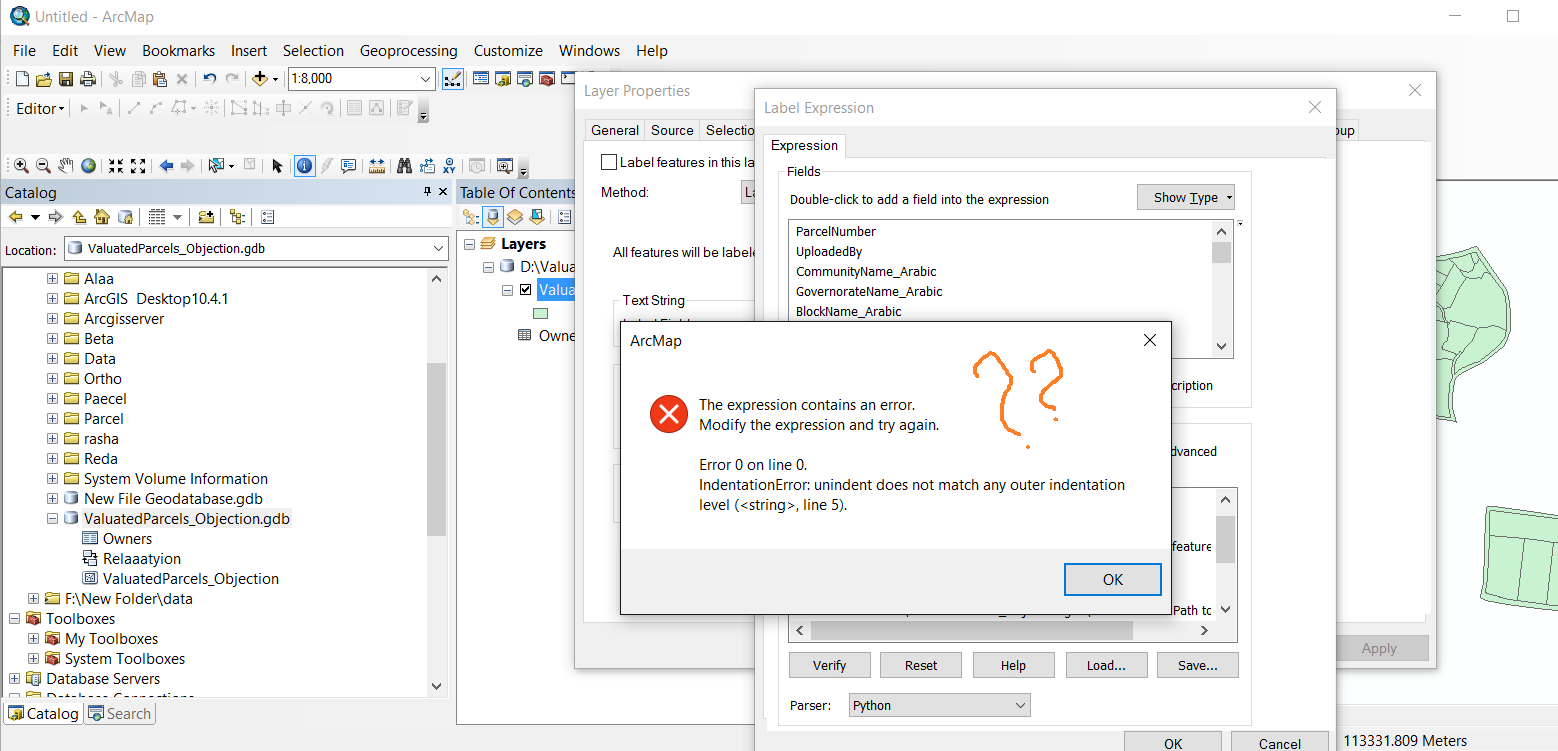
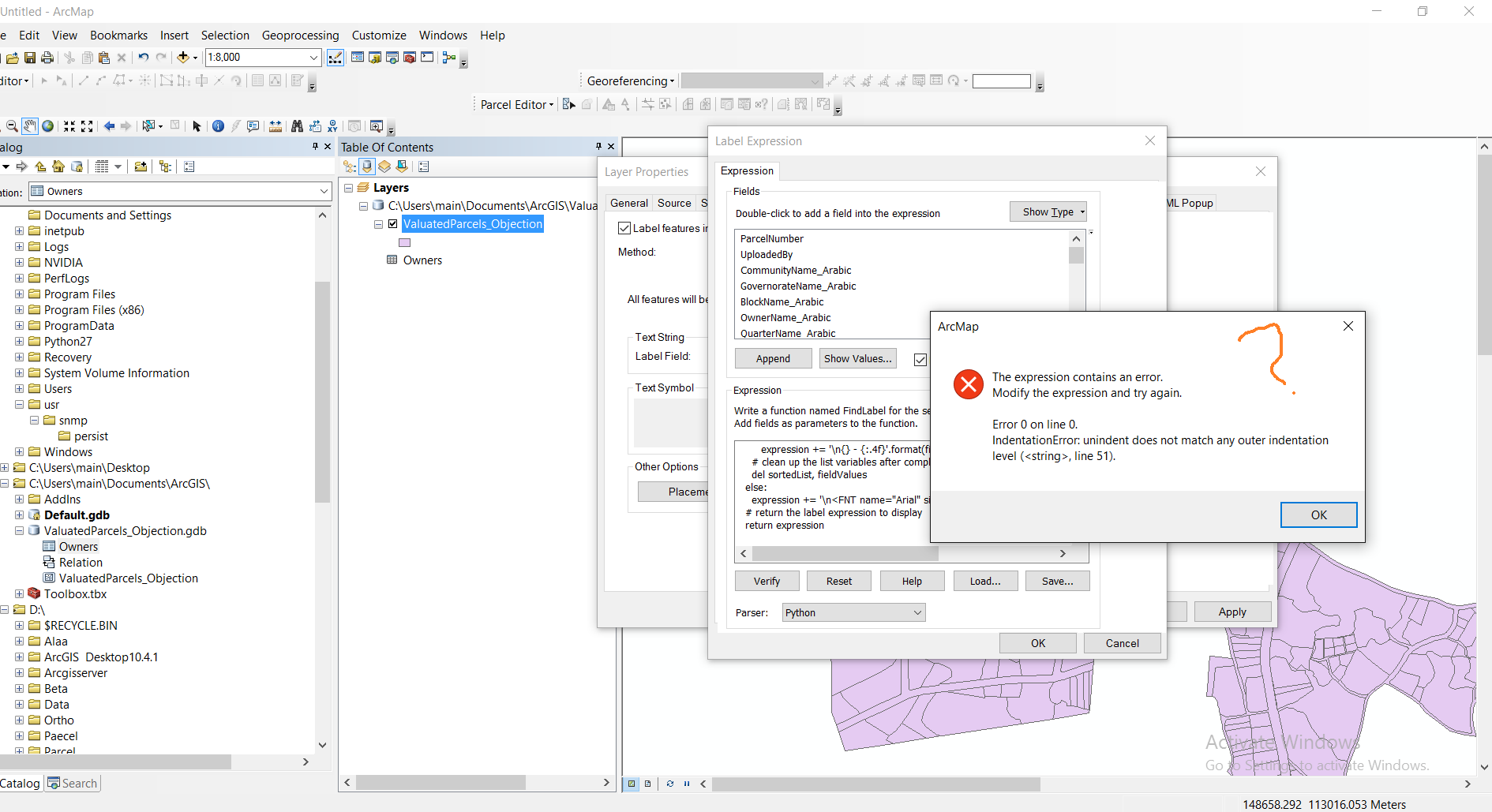
Thanks Jayanta,
but every time i run the python i got an error.
it doesn't work with me. Attached

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
See my Blog called Creating Labels with Related Table Data. This form of code can be used in the Label expression of your features. The key trick is to load the related table into a global dictionary that is created from your related table and that is loaded only when the first label is being built. All other labels simple use the previously loaded dictionary to do all data lookups.
You need to change the field name in the FindLabel definition to be your lookup key field in the feature class. The comments indicate the other key items you need to modify, such as the path to your related table and the names of the fields from your related table that are to be used by the label expression. The order of the listed fields from your related table determines the sort order of the listed records presented in the label expression. You would also need to modify the fixed text "Cross Street Count =" in the expression being built to fit your label fields.
A good knowledge of Python and the label format options can allow you to develop a variety of different label expressions and label layouts that work for related tables. The Blog presents a few different examples.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Use my code. The Esri code is going to run incredibly slowly, since it rebuilds the search for each label. My code runs 10 to 100 times faster. You are wasting your time with the code you have written.
At the same time it is apparent from your lack of understanding of the error code returned that you are a novice in Python. Therefore, it will be easier for me to ask you for the information I will need to revise my code for your particular data and make the modifications myself.
Are you using Arcmap 10.1 or higher?
What is the key field in the feature class?
What is the corresponding key field in the related table?
What is the path to the related table?
What are the field names from the related table you want to show?
If the is in Arabic, what is the name of the font you would use for uniform spacing?
That is a start. I may have more questions later. Once you have a basic working example for your data, you will be responsible to learn python well enough to make exact customizations of the label format to meet your ultimate needs, using the example I provide as a baseline reference.
Please respond to my initial code attempt on stackexchange to your parallel post arcgis desktop - Labeling a layer with the values of stand-alone table (that is associated to the la...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dear Richard,
Many thanks for your response, and Kindly note the following:
- I use ArcMap 10.4.1
- The key field in feature class is “ParcelBlockCommunity”
- The key field in the table is “ParcelBlockCommunity”
- The location of related table| 😧 \Valuatedparcels_objection.gdb\owners
- I want to show the field of OwnerName_Arabic from the related table
- I want to choose the time new roman |14
I tried to use your code and to edit it to be suitable with my case, but I still have the following error.
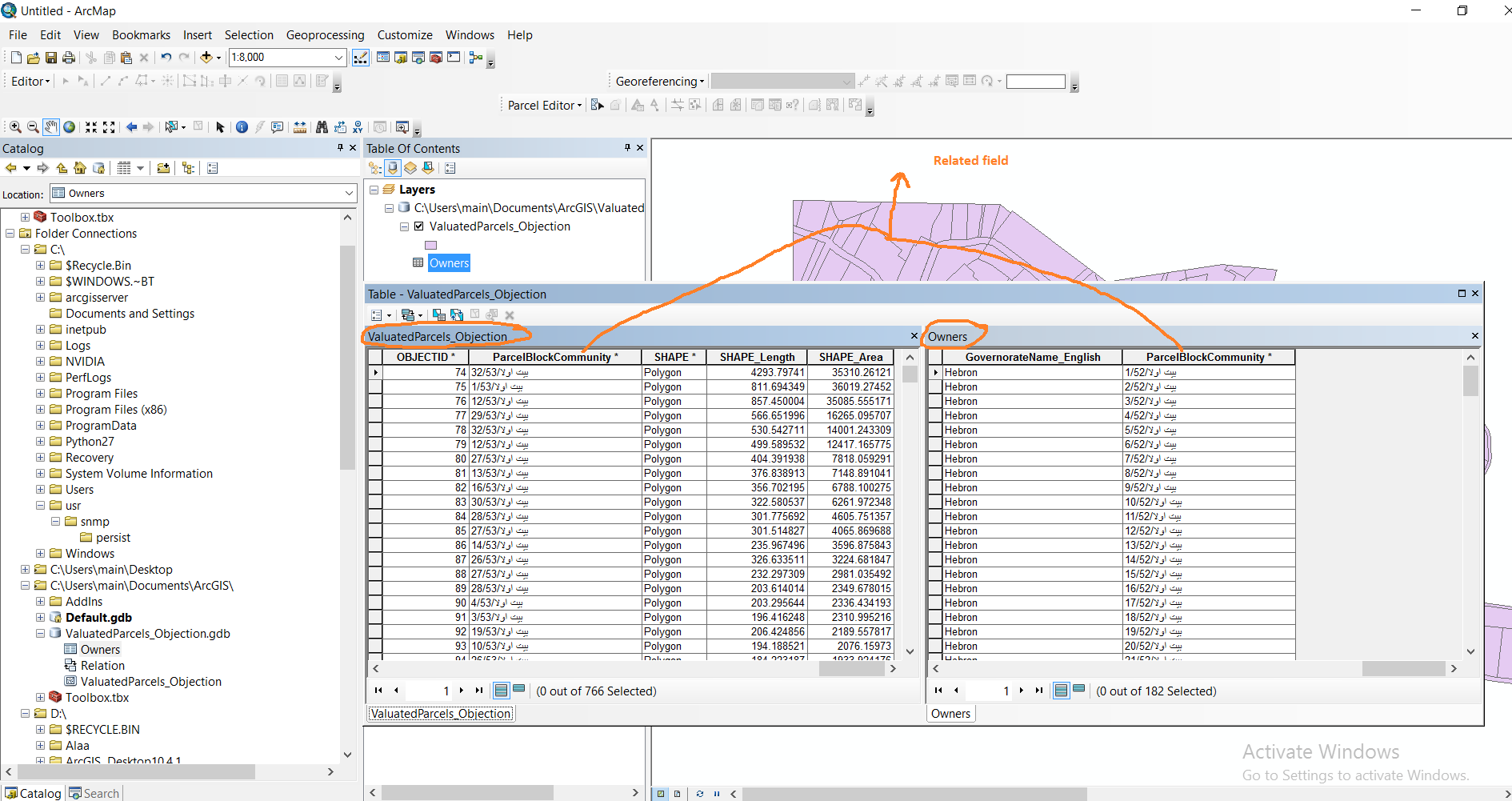
I will upload the data and the python, if you have a time please have a look on them.
http://www.mediafire.com/file/8mbqgv7awatso7m/ValuatedParcels_Objection.gdb.rar
http://www.mediafire.com/file/8a0yd2ldcf4rvwz/python%282%29.txt
Thanks in advance,
Rawan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You are apparently not aware that the indentation of lines in Python has to conform to the Python rules for code block levels. Indentations are required to be at the same level for all lines that are at the same code block level, and certain lines of code, like if and for statements have to be followed by an additional indent level to form a new code block level controlled by those lines of code. Indentation must be observed even by commented lines. Python also requires all variable capitalization to be exact, otherwise you will generate errors or logic bugs in your code.
rather than uploading your code to another website, you should post the code you have edited within your post. It is easier to post on StackExchange, since you just have to highlight your code and press the {} button to make it format within a code window. In GeoNet you have to press the ... button and then apparently choose the More and choose Syntax Highlighter. Paste your code into the dialog and Choose Python for the format.
Times New Roman should work if you are just listing a single field from your related table, since you do not need to have multiple columns of data align together. If you want more than one field and any kind of table column formatting you would need to choose a fixed space font.
I believe I have corrected the indentation problems, but I cannot test it with my data, so let me know if the error still appears and the line number it reports. Do not attempt to alter or customize the label format of my code to your tastes. Before you do that you need to see a working example of the original label format I created as a baseline. Then you can modify that code to a new format after you are better able to understand the rules of Python.
I changed the path to use the D drive, but I do not believe that the path is valid, since it includes User rather than a User name. Please verify the full path in Windows explorer and match it exactly. If you do not want to hard code a specific user name and instead need to have this part of the path adapt on the fly to the user name of the computer in use, then the code would have to be modified to use the os python module to obtain the user name on the fly.
# Initialize a global dictionary for a related feature class/table
relateDict = {}
def FindLabel ( [ParcelBlockCommunity] ):
# declare the dictionary global so it can be built once and used for all labels
global relateDict
# only populate the dictionary if it has no keys
if len(relateDict) == 0:
# Provide the path to the relate feature class/table
relateFC = r"D:\Users\main\Documents\ArcGIS\ValuatedParcels_Objection.gdb\Owners"
# create a field list with the relate field first (ParcelBlockCommunity),
# followed by sort field(s) (ParcelNumber), then label field(s) (OwnerName_Arabic)
relateFieldsList = ["ParcelBlockCommunity", "OwnerName_Arabic"]
# process a da search cursor to transfer the data to the dictionary
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
# store the key value in a variable so the relate value
# is only read from the row once, improving speed
relateKey = relateRow[0]
# if the relate key of the current row isn't found
# create the key and make it's value a list of a list of field values
if not relateKey in relateDict:
# [searchRow[1:]] is a list containing
# a list of the field values after the key.
relateDict[relateKey] = [relateRow[1:]]
else:
# if the relate key is already in the dictionary
# append the next list of field values to the
# existing list associated with the key
relateDict[relateKey].append(relateRow[1:])
# delete the cursor, and row to make sure all locks release
del relateRows, relateRow
# store the current label feature's relate key field value
# so that it is only read once, improving speed
labelKey = [ParcelBlockCommunity]
# start building a label expression.
# My label has a bold key value header in a larger font
expression = '<FNT name="Times New Roman" size="14"><BOL>{}</BOL></FNT>'.format(labelKey)
# determine if the label key is in the dictionary
if labelKey in relateDict:
# sort the list of the list of fields
sortedList = sorted(relateDict[labelKey])
# add a record count to the label header in bold regular font
expression += '\n<FNT name="Times New Roman" size="10"><BOL>Owner Count = {}</BOL></FNT>'.format(len(sortedList))
# process the sorted list
for fieldValues in sortedList:
# append related data to the label expression
# my label shows a list of related
# cross streets and measures sorted in driving order
expression += '\n{}'.format(fieldValues[0])
# clean up the list variables after completing the for loop
del sortedList, fieldValues
else:
expression += '\n<FNT name="Arial" size="10"><BOL>Owner Count = 0</BOL></FNT>'
# return the label expression to display
return expression- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Dear Richard,
Thank you a lot for your effort, I tried to read a lot about python to learn how could I use it.
I tried your code and yes theirs a mistake in the link.
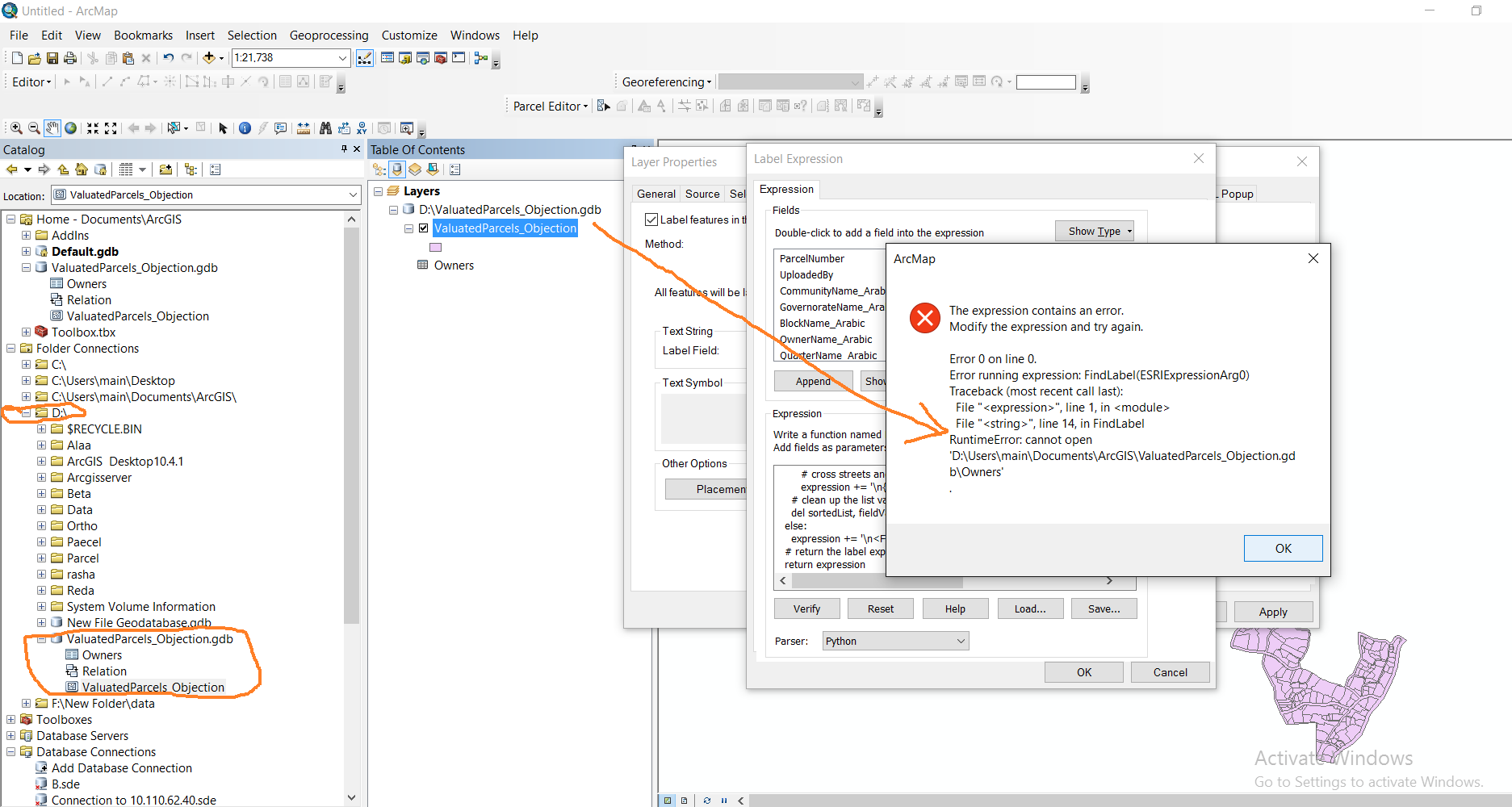
I tried to change the path but I have another error.
# Initialize a global dictionary for a related feature class/table
relateDict = {}
def FindLabel ( [ParcelBlockCommunity] ):
# declare the dictionary global so it can be built once and used for all labels
global relateDict
# only populate the dictionary if it has no keys
if len(relateDict) == 0:
# Provide the path to the relate feature class/table
relateFC = r"C:\Users\main\Documents\ArcGIS\ValuatedParcels_Objection.gdb\Owners"
# create a field list with the relate field first (ParcelBlockCommunity),
# followed by sort field(s) (ParcelNumber), then label field(s) (OwnerName_Arabic)
relateFieldsList = ["ParcelBlockCommunity", "OwnerName_Arabic"]
# process a da search cursor to transfer the data to the dictionary
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
# store the key value in a variable so the relate value
# is only read from the row once, improving speed
relateKey = relateRow[0]
# if the relate key of the current row isn't found
# create the key and make it's value a list of a list of field values
if not relateKey in relateDict:
# [searchRow[1:]] is a list containing
# a list of the field values after the key.
relateDict[relateKey] = [relateRow[1:]]
else:
# if the relate key is already in the dictionary
# append the next list of field values to the
# existing list associated with the key
relateDict[relateKey].append(relateRow[1:])
# delete the cursor, and row to make sure all locks release
del relateRows, relateRow
# store the current label feature's relate key field value
# so that it is only read once, improving speed
labelKey = [ParcelBlockCommunity]
# start building a label expression.
# My label has a bold key value header in a larger font
expression = '<FNT name="Times New Roman" size="14"><BOL>{}</BOL></FNT>'.format(labelKey)
# determine if the label key is in the dictionary
if labelKey in relateDict:
# sort the list of the list of fields
sortedList = sorted(relateDict[labelKey])
# add a record count to the label header in bold regular font
expression += '\n<FNT name="Times New Roman" size="10"><BOL>Owner Count = {}</BOL></FNT>'.format(len(sortedList))
# process the sorted list
for fieldValues in sortedList:
# append related data to the label expression
# my label shows a list of related
# cross streets and measures sorted in driving order
expression += '\n{}'.format(fieldValues[0])
# clean up the list variables after completing the for loop
del sortedList, fieldValues
else:
expression += '\n<FNT name="Arial" size="10"><BOL>Owner Count = 0</BOL></FNT>'
# return the label expression to display
return expression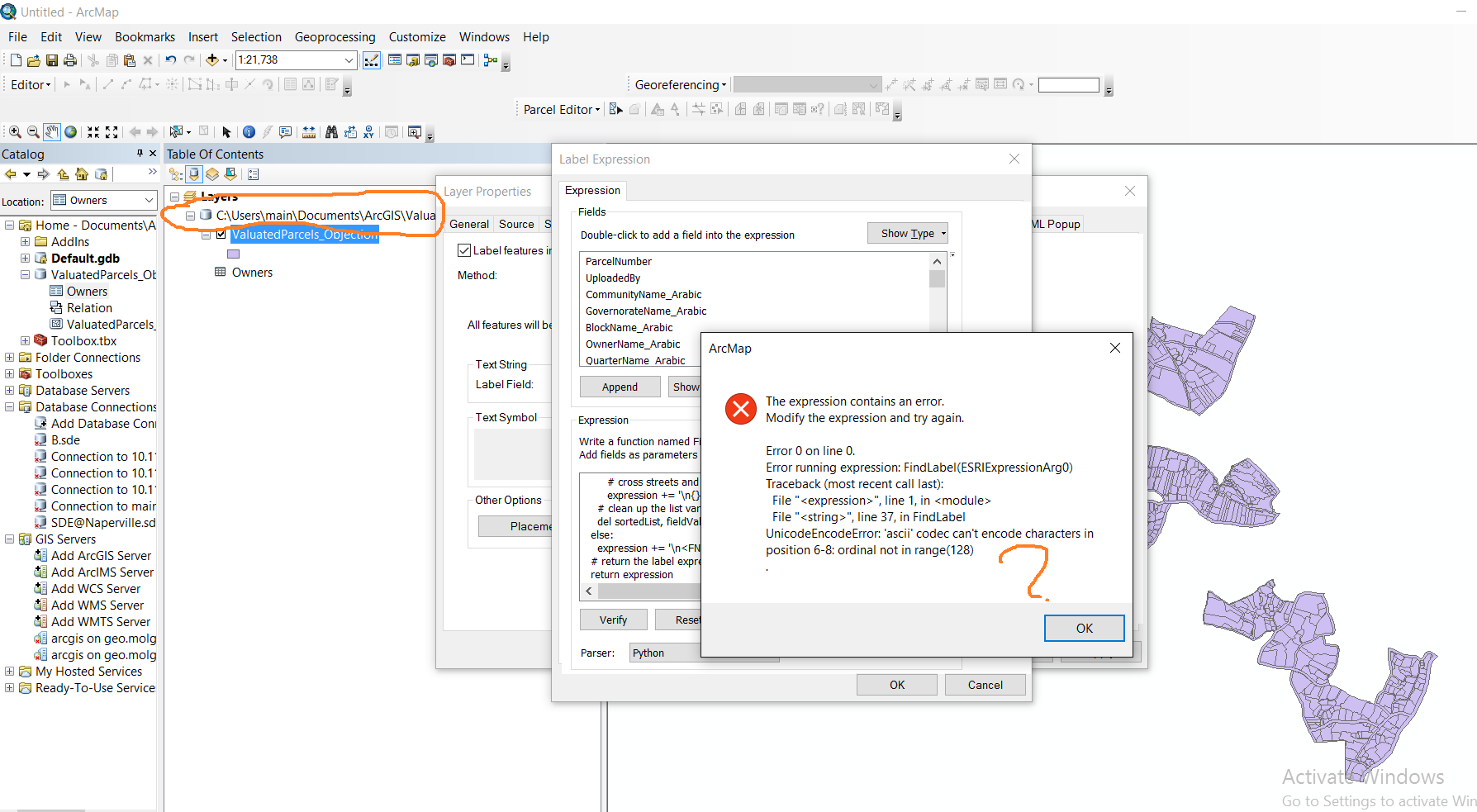
What might be the issue here?
Thanks in advance,
Rawan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am not sure what this error means. There could be several possible things this is indicating. So, line 37 needs to be simplified to do only the most basic label unformatted to see if the problem is caused by the formatting codes or not.. Please change line 37 to just be:
expression = '{}'.format(labelKey)Let me know if this fixes the error for line 37 and if a new error appears on line 43, where more formatting codes were used. Once a plain, unformatted label is created we can try adding back some formatting options.
Are any Arabic characters that are not in the range of a standard ascii font included in the parcel field? If the error persists it is possible the format method does not support the character set your data uses. If that is the case and the error continues try changing line 37 to:
expression = str(labelKey)If both of these still fail let me know some of the values stored in the main parcel field, particularly any values that are not made up of just standard English letters and numbers. String functions may not work and I may need to research the equivalent unicode functions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi rfairhur24,
Much appreciated for your effort, actually I tried the first option and I got the following error.
# Initialize a global dictionary for a related feature class/table
relateDict = {}
def FindLabel ( [ParcelBlockCommunity] ):
# declare the dictionary global so it can be built once and used for all labels
global relateDict
# only populate the dictionary if it has no keys
if len(relateDict) == 0:
# Provide the path to the relate feature class/table
relateFC = r"C:\Users\main\Documents\ArcGIS\ValuatedParcels_Objection.gdb\Owners"
# create a field list with the relate field first (ParcelBlockCommunity),
# followed by sort field(s) (ParcelNumber), then label field(s) (OwnerName_Arabic)
relateFieldsList = ["ParcelBlockCommunity", "OwnerName_Arabic"]
# process a da search cursor to transfer the data to the dictionary
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
# store the key value in a variable so the relate value
# is only read from the row once, improving speed
relateKey = relateRow[0]
# if the relate key of the current row isn't found
# create the key and make it's value a list of a list of field values
if not relateKey in relateDict:
# [searchRow[1:]] is a list containing
# a list of the field values after the key.
relateDict[relateKey] = [relateRow[1:]]
else:
# if the relate key is already in the dictionary
# append the next list of field values to the
# existing list associated with the key
relateDict[relateKey].append(relateRow[1:])
# delete the cursor, and row to make sure all locks release
del relateRows, relateRow
# store the current label feature's relate key field value
# so that it is only read once, improving speed
labelKey = [ParcelBlockCommunity]
# start building a label expression.
# My label has a bold key value header in a larger font
expression = '{}'.format(labelKey)
# determine if the label key is in the dictionary
if labelKey in relateDict:
# sort the list of the list of fields
sortedList = sorted(relateDict[labelKey])
# add a record count to the label header in bold regular font
expression += '\n<FNT name="Times New Roman" size="10"><BOL>Owner Count = {}</BOL></FNT>'.format(len(sortedList))
# process the sorted list
for fieldValues in sortedList:
# append related data to the label expression
# my label shows a list of related
# cross streets and measures sorted in driving order
expression += '\n{}'.format(fieldValues[0])
# clean up the list variables after completing the for loop
del sortedList, fieldValues
else:
expression += '\n<FNT name="Arial" size="10"><BOL>Owner Count = 0</BOL></FNT>'
# return the label expression to display
return expression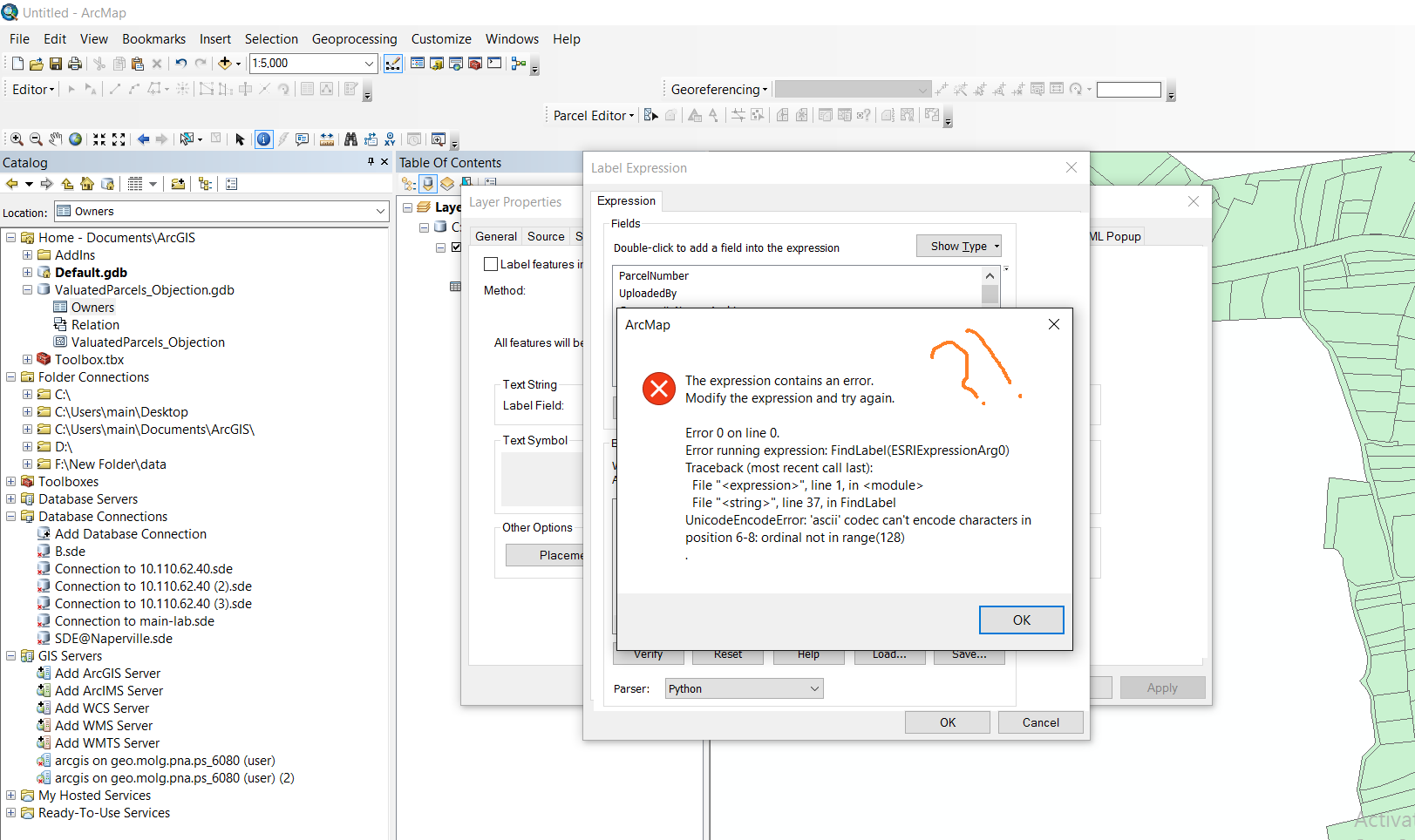
And when I tried the other also I have the following error:
# Initialize a global dictionary for a related feature class/table
relateDict = {}
def FindLabel ( [ParcelBlockCommunity] ):
# declare the dictionary global so it can be built once and used for all labels
global relateDict
# only populate the dictionary if it has no keys
if len(relateDict) == 0:
# Provide the path to the relate feature class/table
relateFC = r"C:\Users\main\Documents\ArcGIS\ValuatedParcels_Objection.gdb\Owners"
# create a field list with the relate field first (ParcelBlockCommunity),
# followed by sort field(s) (ParcelNumber), then label field(s) (OwnerName_Arabic)
relateFieldsList = ["ParcelBlockCommunity", "OwnerName_Arabic"]
# process a da search cursor to transfer the data to the dictionary
with arcpy.da.SearchCursor(relateFC, relateFieldsList) as relateRows:
for relateRow in relateRows:
# store the key value in a variable so the relate value
# is only read from the row once, improving speed
relateKey = relateRow[0]
# if the relate key of the current row isn't found
# create the key and make it's value a list of a list of field values
if not relateKey in relateDict:
# [searchRow[1:]] is a list containing
# a list of the field values after the key.
relateDict[relateKey] = [relateRow[1:]]
else:
# if the relate key is already in the dictionary
# append the next list of field values to the
# existing list associated with the key
relateDict[relateKey].append(relateRow[1:])
# delete the cursor, and row to make sure all locks release
del relateRows, relateRow
# store the current label feature's relate key field value
# so that it is only read once, improving speed
labelKey = [ParcelBlockCommunity]
# start building a label expression.
# My label has a bold key value header in a larger font
expression = str(labelKey)
# determine if the label key is in the dictionary
if labelKey in relateDict:
# sort the list of the list of fields
sortedList = sorted(relateDict[labelKey])
# add a record count to the label header in bold regular font
expression += '\n<FNT name="Times New Roman" size="10"><BOL>Owner Count = {}</BOL></FNT>'.format(len(sortedList))
# process the sorted list
for fieldValues in sortedList:
# append related data to the label expression
# my label shows a list of related
# cross streets and measures sorted in driving order
expression += '\n{}'.format(fieldValues[0])
# clean up the list variables after completing the for loop
del sortedList, fieldValues
else:
expression += '\n<FNT name="Arial" size="10"><BOL>Owner Count = 0</BOL></FNT>'
# return the label expression to display
return expression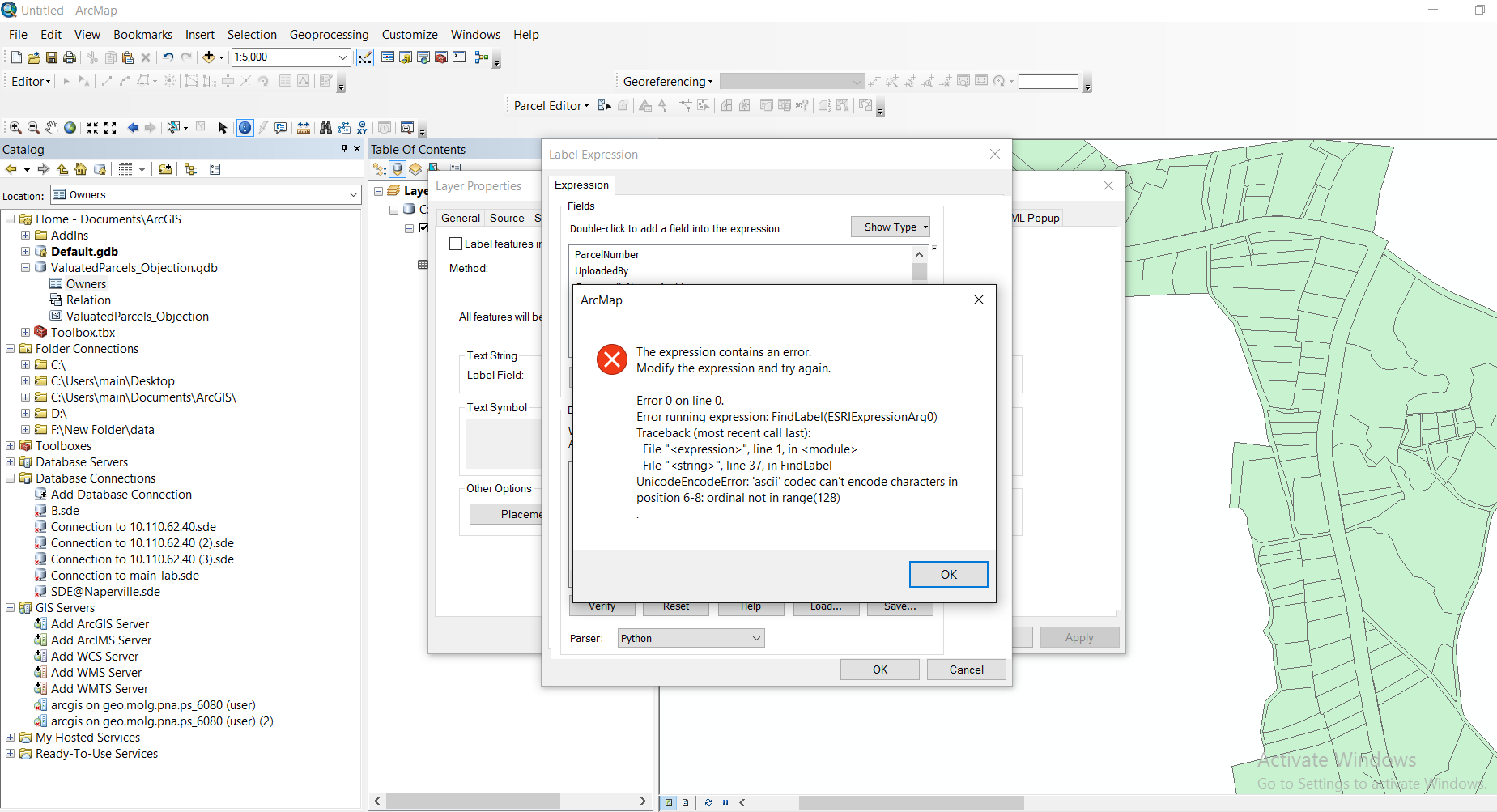
One more thing, the related table contains a field with Arabic character and I need this field to be labeled. There are in the range of standard ascii font.
Thanks in advance,
Rawan