- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Export Data Changes Message tool won't validate Re...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Export Data Changes Message tool won't validate Replica parameter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
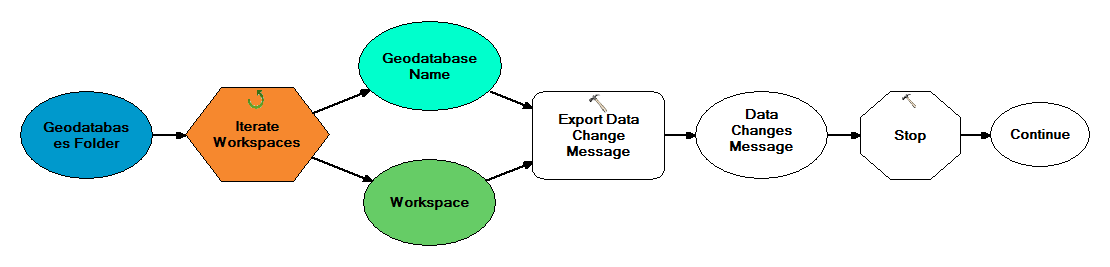
I've created a model that iterates through a folder to find file geodatabases, then exports data changes messages from each file geodatabase using the Export Data Change Message tool. For simplicity, the name each checkout is the same as the name of the geodatabase.
I've used an iterator to iterate through each of the file geodatabases in the folder, to get a Workspace variable representing the file geodatabase, and a string variable representing the name of the geodatabase. If I use the string variable representing the name of the geodatabase as the input to the Replica parameter in the Export Data Change Message tool, the tool will not validate and the model will fail. If I manually enter the name of the replica, then the model executes without error.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Often when I have validation messages like this, I will take the suspect input and run it through the Calculate Value tool to convert it into the data type the tool is expecting, for example:
Expression:
r"%Geodatabase Name%"Date type: String
I am wondering though whether the name of the first geodatabase is not passing validation due to special characters, in which case you can get fancier with Calculate Value
Expression:
f(r"%Geodatabase Name%")Code block:
def f(nm):
return arcpy.ValidateTableName(nm)Data Type: String
Another approach to handling validation problems with ModelBuilder (which crop up often as schema validation code [mine and Esri's] can be buggy) is to bypass ModelBuilder pre-run validation by running tools inside Calculate Value:
Expression:
f(r"%Geodatabase Name%", r"%Workspace%")Code block:
def f(nm, wk):
r = arcpy.ExportDataChangeMessage_management(...)
return r.getOutput(0)Data Type: String
One more thing: I may be missing something but I don't think Stop and Continue are necessary, the model will iterate and end after the last iterator pass without them.