- Home
- :
- All Communities
- :
- Products
- :
- Geoprocessing
- :
- Geoprocessing Questions
- :
- Re: ArcPy script to search, get value, compare to ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
ArcPy script to search, get value, compare to field names and sum field values
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
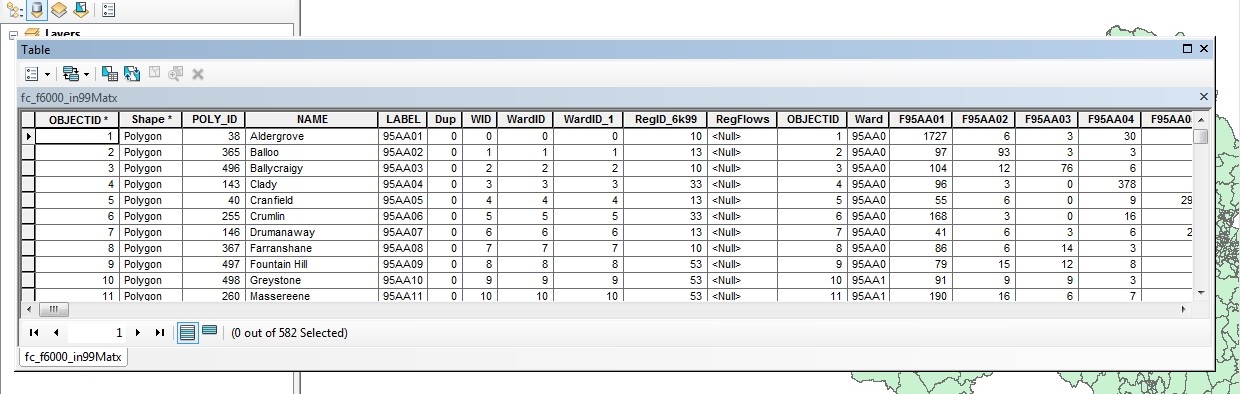
I am looking to write a script to loop through each of the region ID numbers ("RegID_6k99"), select all of the areas which have that number, for these areas look at the area label and sum the cell values for the row based only where field names are the same as those belonging to the region.
I have written the code as follows:
>>> import arcpy
>>> fieldlist = arcpy.ListFields("C:/Temp/lorraine/NIData.gdb/fc_f6000_in99Matx")
>>> for field in fieldlist:
print field.name
>>>fc = "C:/Temp/lorraine/NIData.gdb/fc_f6000_in99Matx"
>>> regfield = "RegID_6k99"
>>> cursor = arcpy.SearchCursor(fc)
>>> for row in cursor:
print(row.getValue(regfield))
>>> for row in cursor:
if row.getValue(regfield)=="1":
row.getValue(LABEL)
print row.getValue(LABEL)
I have a search cursor to get a certain value. So I need to increment this upwards and I need to link the selection to the field name (fieldlist) and sum the values in those cells to a new column.
Help! I'm stuck. Don't know how to implement these last stages. Any advice gratefully accepted. Lorraine
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
result = [row[0] for row in arcpy.da.SearchCursor(
outFC,
("RegID_6k99"))]
unique = set(result)
lengthDict = {}
for uni in unique:
where = "\"RegID_6k99\" = '%s'" % (uni)
lengths = [row[0] for row in arcpy.da.SearchCursor(
fc,
("Shape_Length"),
where)]
lengthDict[uni] = sum(lengths)
for each in lengthDict.keys():
print "%s: %s" % (each, lengthDict[each])This should print out the total lengths for each RegID_6k99 value.
<< no warranties expressed or implied >>
note: use the '#' button to add code tags to your post
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
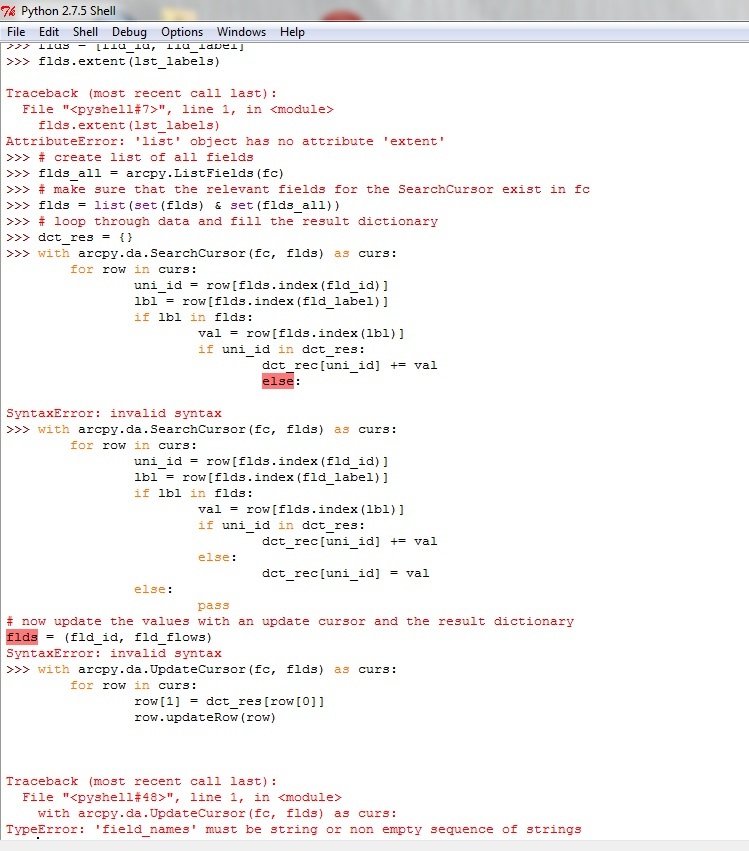
Many thanks Mark for your reply. This has been really useful. I have been working through it and have tried to modify it slightly. I have run into some errors (see attached jpg) and I don't think it does exactly what I want it to do. I don't think I explained the task very well initially. So I will need to modify the code further but its definitely (thanks to your help) going in the right direction.
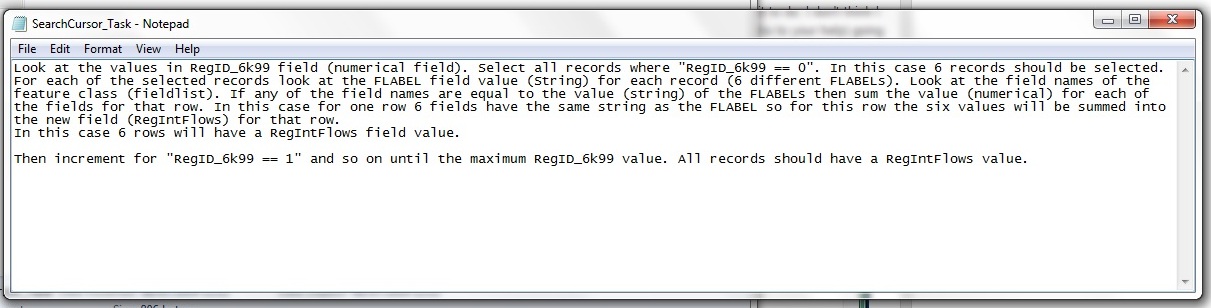
I have attached a txt file explaining what I am trying to do. Any other suggestions greatly accepted. I have been working on this for many days - nearly pulling my hair out. The task is critical to proceed. The number of records does not change but the assigned region value for each record can have an exponential amount of permutations which I need to test. Therefore automation is crucial.
Many thanks again
Lorraine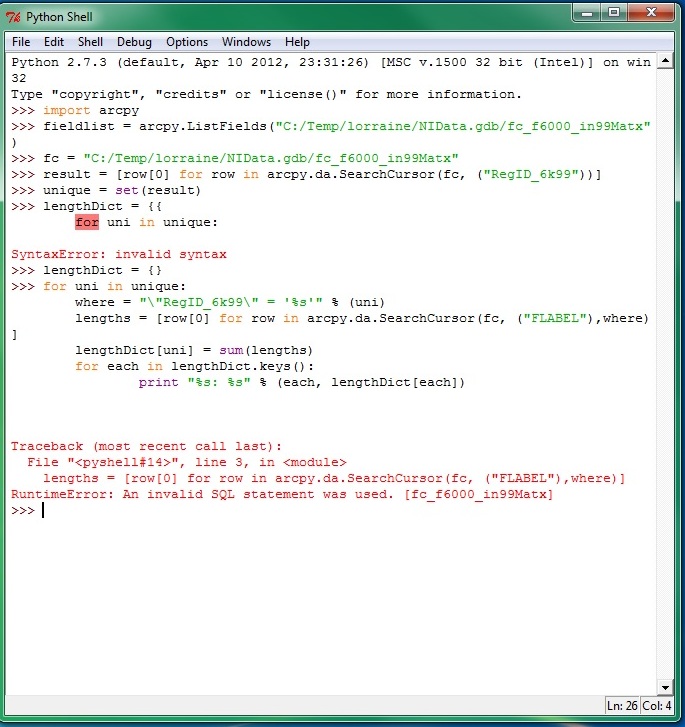
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've modified the script to include looking at the field name but I need to sort out the if else statement at the end.
Help please!!
Any comments greatly appreciated
Lorraine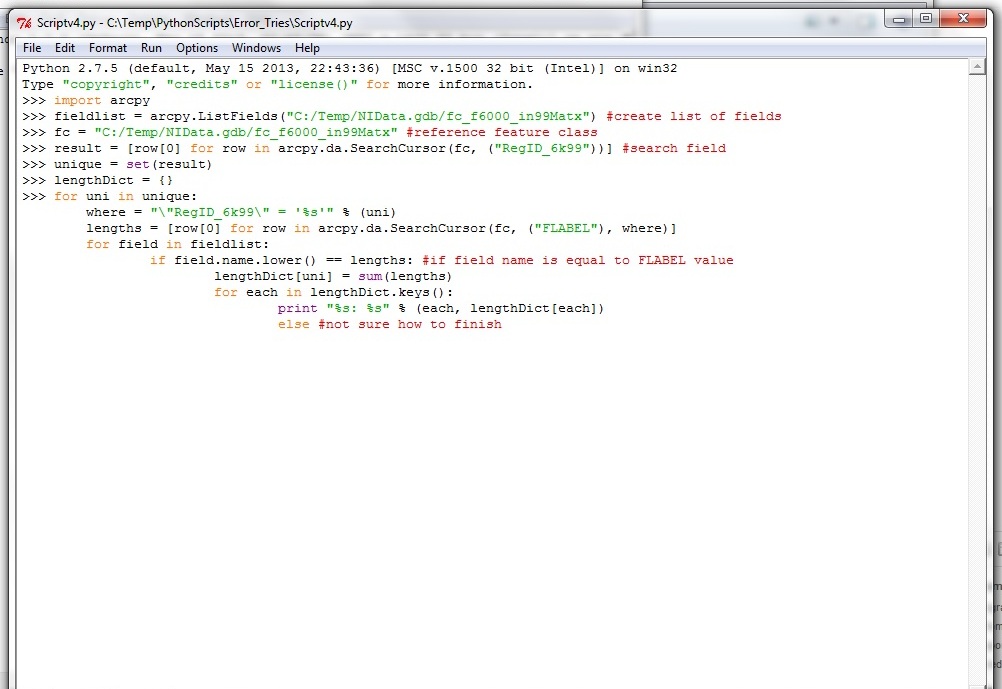
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Lorraine,
Please have a look at the code below:
import arcpy
fc = "C:/Temp/lorraine/NIData.gdb/fc_f6000_in99Matx"
fld_id = "RegID_6k99"
fld_label = "FLABEL"
fld_flows = "RegIntFlows"
# create a unique list of all the FLABEL values
lst_labels = list(set([row[0] for row in arcpy.da.SearchCursor(fc, (fld_label))]))
# Create the list of fields to be used in the SearchCursor
flds = [fld_id, fld_label]
flds.extent(lst_labels)
# create list of all fields
flds_all = arcpy.ListFields(fc)
# make sure that the relevant fields for the SearchCursor exist in fc
flds = list(set(flds) & set(flds_all))
# loop through data and fill the result dictionary
dct_res = {}
with arcpy.da.SearchCursor(fc, flds) as curs:
for row in curs:
uni_id = row[flds.index(fld_id)]
lbl = row[flds.index(fld_label)]
if lbl in flds:
val = row[flds.index(lbl)]
if uni_id in dct_res:
dct_rec[uni_id] += val
else:
dct_rec[uni_id] = val
else:
# lbl in field FLABEL does not exist as field
pass
# now update the values with an update cursor and the result dictionary
flds = (fld_id, fld_flows)
with arcpy.da.UpdateCursor(fc, flds) as curs:
for row in curs:
row[1] = dct_res[row[0]]
row.updateRow(row)
First of all I have not tested the code, so this might not work at all. If you are willing to attach a part of your data to this thread, I could test the code and tweak it where necessary...
I'll try to explain what I intent to do in the code:
- on line 8, a unique list of all the values in the field FLABEL is created. This will be used later on to define the fields for the search cursor
- on line 11 and 12, the actual list of fields created (all the FLABEL values and the RegID_6k99 field and the FLABEL field)
- on line 15 a list of fields is created (all fields in the featureclass)
- on line 18 the list of fields (from line 12) is tested against the available fields in the featureclass
- on line 22 a search cursor is started to read for each record the RegID_6k99 and the FLABEL (please note the I'm using flds.index(fieldname) to determine the index number to access the correct field in the row tuple)
- on line 26, there is a test to see if the FLABEL value actually exists as fieldname in the fc
- on line 27, the value is read for the FLABEL value field
- lines 28 - 31 add the value to the result dictionary. The dictionary will contain each RegID_6k99 value and the sum of the values
- on line 38 a update cursor is defined which will update the RegIntFlows value of the cursor assuming the field RegIntFlows already exists
I hope this makes sense to you and that the code actually runs. If not, please let me know and I see what I can do.
Kind regards,
Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@XanderBakker, thank you so much for taking the time and effort to look at this, this is really helpful. I was completely stuck with it. You are brilliant. The code sounds as if it will do exactly as I want it to do.
I've tried running the code but I get an error with the list and update cursor. Any ideas?
I have zipped up feature class and attached it here. If you could take a look that would be great.
Many thanks Xander
Lorraine
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Lorraine,
Thanks for sending the dataset. This way I could test the code and noticed that I had quite a number of errors in the script.
Please observe the corrected code that "did something" (you should verify if the values correspond to what you expected).
import arcpy
# fc = "D:/Xander/tmp/NIData.gdb/test_copy"
fc = "C:/Temp/lorraine/NIData.gdb/fc_f6000_in99Matx"
fld_id = "RegID_6k99"
fld_label = "FLABEL"
fld_flows = "RegIntFlows"
# create a unique list of all the FLABEL values
lst_labels = list(set([row[0] for row in arcpy.da.SearchCursor(fc, (fld_label))]))
# Create the list of fields to be used in the SearchCursor
flds = [fld_id, fld_label]
flds.extend(lst_labels)
# create list of all fields
flds_all = [fld.name for fld in arcpy.ListFields(fc)]
# make sure that the relevant fields for the SearchCursor exist in fc
flds = list(set(flds) & set(flds_all))
# loop through data and fill the result dictionary
dct_res = {}
with arcpy.da.SearchCursor(fc, flds) as curs:
for row in curs:
uni_id = row[flds.index(fld_id)]
lbl = row[flds.index(fld_label)]
if lbl in flds:
val = row[flds.index(lbl)]
if uni_id in dct_res:
dct_res[uni_id] += val
else:
dct_res[uni_id] = val
else:
# lbl in field FLABEL does not exist as field
pass
# now update the values with an update cursor and the result dictionary
flds = (fld_id, fld_flows)
with arcpy.da.UpdateCursor(fc, flds) as curs:
for row in curs:
row[1] = dct_res[row[0]]
curs.updateRow(row)
Some of the errors in the code where:
- line 13 I write "flds.extent()" when this should be "flds.extend()"
- line 16 has been changed. The ListFields returns field objects and not the field names. line changed to use a List Comprehension to generate the list of field names
- Line 30 and 32 referred to a variable called "dct_rec" in stead of "dct_res"
- Line 42 tried to do an updateRow on the row object when this should be called on the curs object
At least I learned a thing that I shouldn't try to do these kind of things without a dataset...
Hope this works for you.
Kind regards,
Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Xander, thank you so much. I knew I was missing the ability to get the values from the cursor, just didn't know how to go about it.
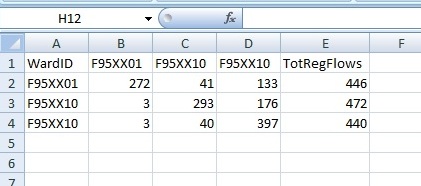
I have run the code on data. The intended field (TotRegFlows) is being updated but I am not sure how the figure is calculated. Each row (or Ward) should have a unique total. By running the code, all rows with the same RegID_6k99 value has the same. I have calculated the correct totals manually for two RegID_6k99 values. I have attached a screendump of one example where RegID_6k99 = 4. In the example there are 3 wards with a region ID of 4. the FLABELs of these wards are F95XX01, F95XX10, F95XX11. Correct flow totals are shown in the attached screendump.
The values from running the code for these three rows or wards are all 962. I can't spot where this value is coming from.
Do you think the error could be related to the sorting of fields? Should include a print somewhere along the way to check expected values?
Xander, thanks for your help, I really appreciate it
Lorraine
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Lorraine,
Try this code, it creates the same value you are expecting:
import arcpy
# fc = "D:/Xander/tmp/NIData.gdb/test_copy"
fc = "C:/Temp/lorraine/NIData.gdb/fc_f6000_in99Matx"
fld_id = "RegID_6k99"
fld_label = "FLABEL"
fld_flows = "RegIntFlows"
# create a unique list of all the FLABEL values
lst_labels = list(set([row[0] for row in arcpy.da.SearchCursor(fc, (fld_label))]))
# Create the list of fields to be used in the SearchCursor
flds = [fld_id, fld_label]
flds.extend(lst_labels)
# create list of all fields
flds_all = [fld.name for fld in arcpy.ListFields(fc)]
# make sure that the relevant fields for the SearchCursor exist in fc
flds = list(set(flds) & set(flds_all))
# create a dictionary with for each RegID_6k99 a list of corresponding FLABEL fields
dct_ref ={}
flds2 = (fld_id, fld_label)
with arcpy.da.SearchCursor(fc, flds2) as curs:
for row in curs:
uni_id = row[0]
lbl = row[1]
if uni_id in dct_ref:
lst_lbls = dct_ref[uni_id]
if not lbl in lst_lbls:
lst_lbls.append(lbl)
else:
lst_lbls = [lbl]
dct_ref[uni_id] = lst_lbls
# loop through data and fill the result dictionary
flds.append(fld_flows)
with arcpy.da.UpdateCursor(fc, flds) as curs:
for row in curs:
uni_id = row[flds.index(fld_id)]
if uni_id in dct_ref:
lst_lbls = dct_ref[uni_id]
val = 0
for lbl in lst_lbls:
if lbl in flds:
val += row[flds.index(lbl)]
else:
print " - lbl {0} in field FLABEL for RegID_6k99 = {1} does not exist as field".format(lbl, uni_id)
row[flds.index(fld_flows)] = val
curs.updateRow(row)
else:
print "key uni_id {0} not found in dct_ref".format(uni_id)
What has changed is this:
- lines 22 - 34 creates a dictionary with unique FLABELS per RegID_6k99
- lines 37 - 52 the search cursor and update cursor have been replaced by a single update cursor.
- line 42 reads the list of FLABELS for the current RegID_6k99
- lines 44 - 46 sums the relevant values
- line 49 stores the value in the flow field
Kind regards,
Xander
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Lorraine,
What I understood is that the code should sum the values for all records for a RegID_6k99. That's why the result is higher than you expected. Based on what you are showing, it seems that the calculation should be affected for each row. This means that there is no need to have both the Search cursor and the Update cursor. A single Update cursor will do.
Before I start with the changes in the code, let me get some things clear:
- in the image I suppose that cells A4 and D1 should be "F95XX11" in stead of "F92XX10".
- the example show all the records (3) for RegID_6k99 = 4
- the FLABEL field for those 3 records contains the values F95XX01, F95XX10 and F95XX11
- for each record those fields (F95XX01, F95XX10 and F95XX11) should be summed (in case RegID_6k99 = 4)
If this is the case we will need to create an initial dictionary that stores the 1:n relation of RegID_6k99 and FLABEL. In the update cursor we will need to read this dictionary to determine which fields to sum.
If this is what you are looking for, let me know and I'll dive into that.
Kind regards,
Xander