- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Geodatabase Questions
- :
- Using sde.next_rowid in T-SQL
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Using sde.next_rowid in T-SQL
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
SQL Server 2016
ArcGIS 10.5
I want to insert into a registered table using set processing using sde.next_rowid.
I do this in Oracle as:
INSERT INTO MYTABLE (OBJECTID, SITE_ID)
SELECT SDE.GDB_UTIL.NEXT(ROWID ('OWNER','MYTABLE'), SITE_ID FROM MYVIEW;
In SQL Server ESRI documentation examples I see selecting the objectid, writing down the number, and then hard coding it into the insert statement.
This will be a nightly job that will insert thousands of rows, so set processing is required.
I try
INSERT INTO MYTABLE
SELECT SDE.NEXT_ROWID ('OWNER','MYTABLE'), SITE_ID
FROM OWNER.MYVIEW;
and get
Cannot find either column "SDE" or the user-defined function or aggregate "SDE.NEXT_ROWID", or the name is ambiguous.
I can use SDE.NEXT_ROWID to query like so:
DECLARE @id as integer
EXEC sde.next_rowid 'OWNER', 'MYTABLE', @id OUTPUT;
SELECT @id "Next ObjectID";
and this works just fine.
I'm new to SQL Server, I'm sure it's a syntax issue.
Any insights are appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
The example in the documentation isn't saying, or even suggesting, you write the value down and then hard wire it into a query. The example is trying to demonstrate that you need to retrieve the value first before using it later in a query.
What about:
DECLARE @myval int
EXEC sde.next_rowid 'OWNER', 'MYTABLE', @myval OUTPUT
INSERT INTO MYTABLE
SELECT @myval, SITE_ID
FROM OWNER.MYVIEW; - Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Joshua, thanks for the answer. I've been out of the office and am now getting back to this, I'll give this a try and let you know. This is the 10.5 documentation that I was referring to, but your example may help for sure.
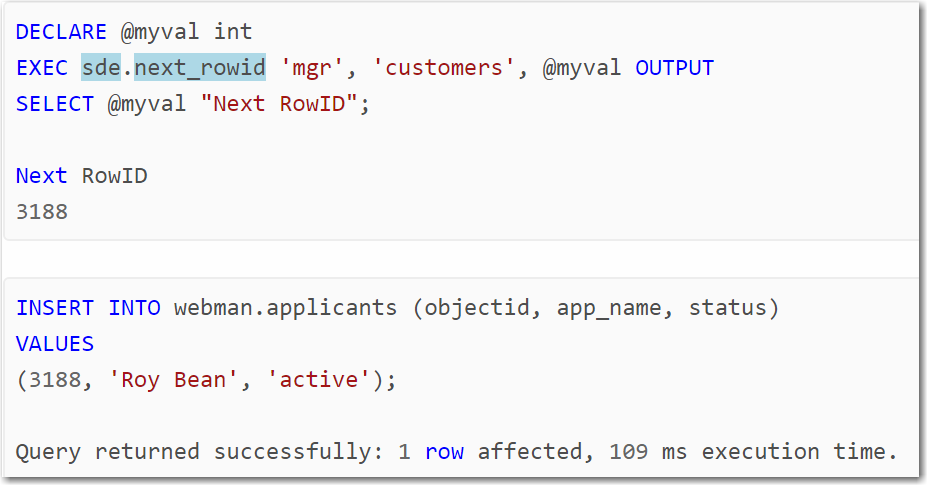
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Joshua,
You example worked great for the first row. For example, the sde.next_rowid returns as 30279. The first row entered has an object id of 30279. The insert statement has 33,000 rows to add, but this doesn't get the next row id, it uses objectid. So it would have to be in a loop, as shown in this article:
How To: Insert geometry from XY coordinates using SQL
But I don't want a loop, I want set processing as opposed to iterative.
For example, in Oracle the statement
INSERT INTO MYTABLE (OBJECTID, SITE_ID)
SELECT SDE.GDB_UTIL.NEXT(ROWID ('OWNER','MYTABLE'), SITE_ID FROM MYVIEW;
Inserts into MYTABLE the uniqueid from next_rowid for all 33,000 rows.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Looking back, I forgot to ask, is this versioned data? You said it is registered but didn't explicitly say whether it was versioned or not. If it is versioned, then you can use the versioned view to do the inserts and it does the OBJECTID for you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
No, it is not versioned.
I've simplified it to taking a non-registered table and inserting into a registered table with an objectid.
Same problem, but trying to make it clearer.
Goal: Populate a target table of 4 columns. 3 columns come from another table, 1 column is derived from a (third-party) stored procedure. For performance reasons I want to use set processing, not cursors or iterative processing.
Source Table: county_source
county varchar(3)
countyname varchar(12)
Target Table: county_target
county varchar(3)
countyname varchar(12)
objectid int
The objectid for each row comes from a stored procedure, like so:
EXEC sde.next_rowid 'OWNER', 'COUNTY_TARGET', @objectid OUTPUT;
I need to insert into county_target with an objectid, where one of the columns come from the stored
procedure. The insert will be a select from county_source.
------------------------------
The code that I am using is wrong as the stored procedure doesn't fire.
DECLARE @objectid as INT
declare @sql as varchar(100)
declare @owner as varchar(10) = 'SDECREATOR'
declare @table as varchar(25) = 'County_Target'
set @sql = 'exec sde.next_rowid, @owner, @table, ' + convert(varchar(5),@objectid) + 'OUTPUT';
INSERT INTO [SDECREATOR].[County_Target]
(OBJECTID, COUNTY, COUNTY_NAME)
SELECT @sql,
COUNTY,
COUNTY_NAME
FROM [SDECREATOR].[County_Source];
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hello All
I just started looking into this as we are starting to try some new things here using sql server to create new features. We did some experimenting last week and we were able to get something to work. Once I started reading some documentation I am a little concerned that we may get into trouble in the future. What we are doing is creating an inner join in sql using a table and a feature class. We then output the matching records to a non-versioned feature class using the shape from the feature class used in the join. We are using a recid identity field to write into the objectid of the output feature class. What we do is truncate the output feature class before inserting the new records. It has been running every 2 minutes for the last week and seems to be functioning like we want. Everything I read says to not mess with the ObjectID, but the workaround using "next_rowid" seems a little much if we are using an Identity field from another table. Has anyone experienced what may happen when you insert values into an objectid of a non-versioned feature class if it is truncated prior to the insert?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi Mark. I'm curious to see how this works in the long term. I'm coming from Oracle, where updating the objectid is easier because the next_rowid is a function. We've been using SDE there for a very long time, and from experience, my biggest rule is to never mess with SDE from SQL, always use SDE to do the work. There are so many inter-dependencies in the GDB and metadata tables that you may think you're okay, and then all of a sudden realize an issue is cropping up. I used to try and go around SDE for performance and ease of use, but vowed to abandon that idea after we had to recover the database back to a point-in-time before I touched it. I don't have enough experience with SDE and MS SQL yet to comment, but I'm interested in what others have to say.
Sherrie
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Yes that was always our rule of thumb too. We had some old sql DBAs that tried to back door GIS and really screwed things up. That was probably 15 years ago and before using sql geometry. I think using sql geometry has really opened the door to opportunities. The reason that we had to do this was because there is such an overhead with ESRI joins using map services and the operations dashboard. We are using the operations dashboard to view electrical outage information coming from our CIS system. There are multiple widgets on our dashboard updating every 2 minutes. When doing the join through esri the update was happening on all 7 widgets every 2 minutes and our sql server (server) was overwhelmed.
One good thing I guess is not having to recover this information as it is updated every 2 minutes and the only thing that comes from esri is the shape of the points. Doing the join once on the sql side and writing the data to a feature class has optimized the operation dashboard greatly and reduced overhead. Doing the join with esri was trying to match 12,000 meters in 7 different widgets every 2 minutes and was a huge bottleneck.
Hopefully it will continue to run and not cause issues, I can't believe they don't have a sql function that will operate like oracle. We do not have to edit the data so unregistering as versioned removes a lot of the interdependence. I guess if we have to we can try to create the ObjectID using an iterator and a loop, but adds a lot of logic over what we currently have in place.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I found a work around in another post that I can't find anymore. Basically you create a temporary table to store the OBJECTIDS, perform a join with your table, and then perform the insert. This approach works well for a small number of records but becomes slow for larger sets (>100,000). I use this approach often so if you can think of improvements please share.
------------------------------
declare @OBJECTID int
declare @ids table(
OBJECTID INT
)
declare @RowCnt int
declare @MaxRows int
select @MaxRows = count(*) from INPUT_TABLE
select @RowCnt = 1
while @RowCnt <= @MaxRows
begin
EXEC sde.next_rowid 'OWNER', 'TABLENAME', @OBJECTID OUTPUT
insert into @ids (OBJECTID) values(@OBJECTID)
Select @RowCnt = @RowCnt + 1
end
insert into TARGET_TABLE(OBJECTID, COLUMN1, COLUMN2, COLUMN3)
select
ids.OBJECTID,
COLUMN1, COLUMN2, COLUMN3
from (
select
ROW_NUMBER() OVER(ORDER BY (select null)) AS RowNumber,
COLUMN1, COLUMN2, COLUMN3
from INPUT_TABLE
) as attr
join (
select
*,
ROW_NUMBER() OVER(ORDER BY [objectid]) AS RowNumber
from @ids
) as ids
on attr.RowNumber = ids.RowNumber