- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Geodatabase Questions
- :
- Fundamental flaw when opening attribute tables in ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Fundamental flaw when opening attribute tables in ArcGIS Pro?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can someone from ESRI please have a good look at this. @Kory Kramer, @George Thompson, @Vince Angelo
For some background:
- ArcGIS Pro 2.1.3 on Windows 10
- PostgreSQL 9.6 on Ubuntu 18.04 running on a Virtualbox VM executed on the Windows host
Situation:
A line layer with a valid Definition Query set present in the TOC. The layer is an ArcGIS Query Layer (so a spatial database but not an enterprise geodatabase) and references a huge Europe OpenStreetMap extract containing +/- 65M records in the line table. This line table has both valid spatial index (GIST) and attribute indexes. The display performance of the layers in Pro's Map window is adequate, and actually surprisingly fast given the huge data source.
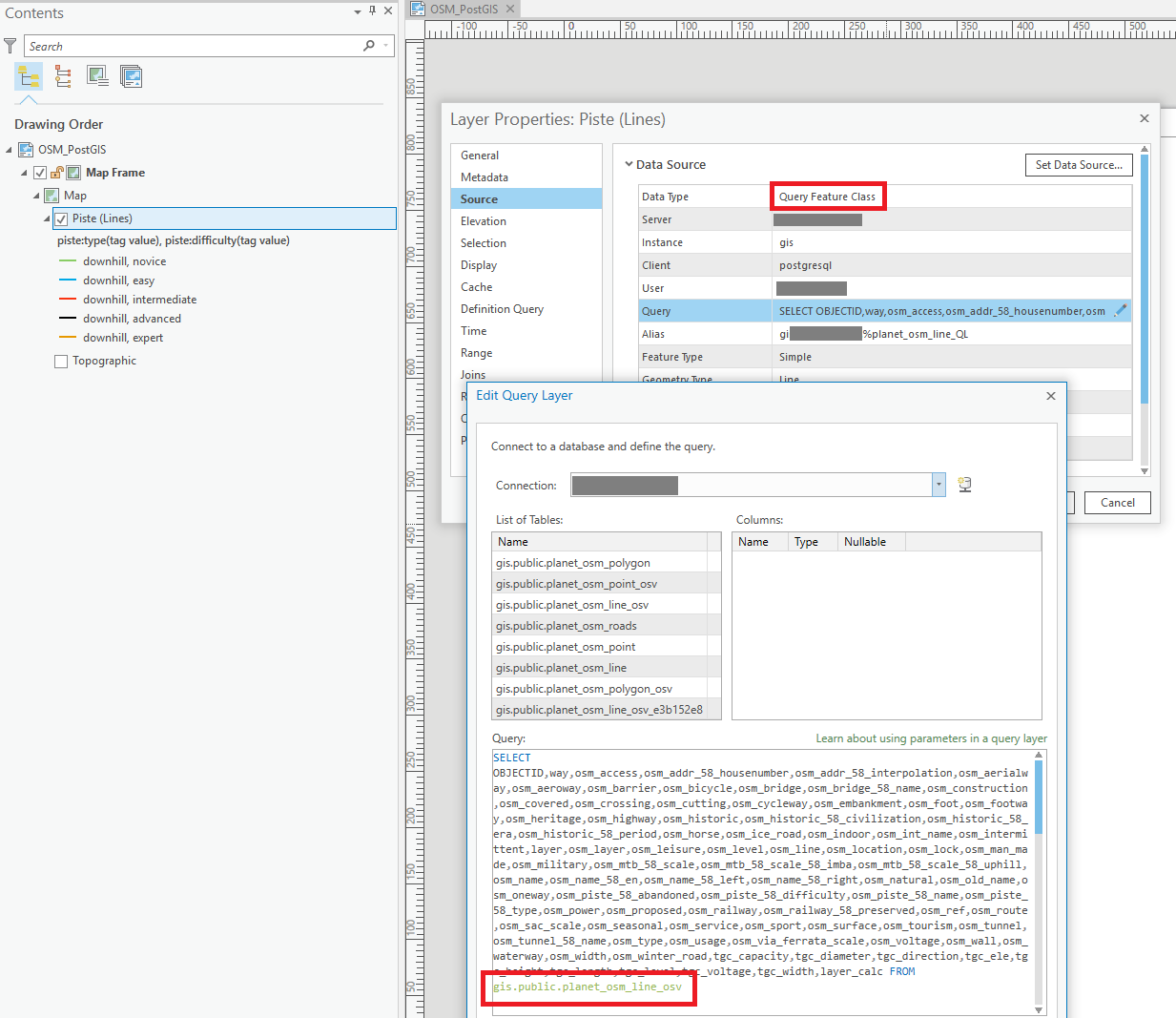
The Definition Query set on the layer, see image, references an indexed field, osm_piste_58_type:
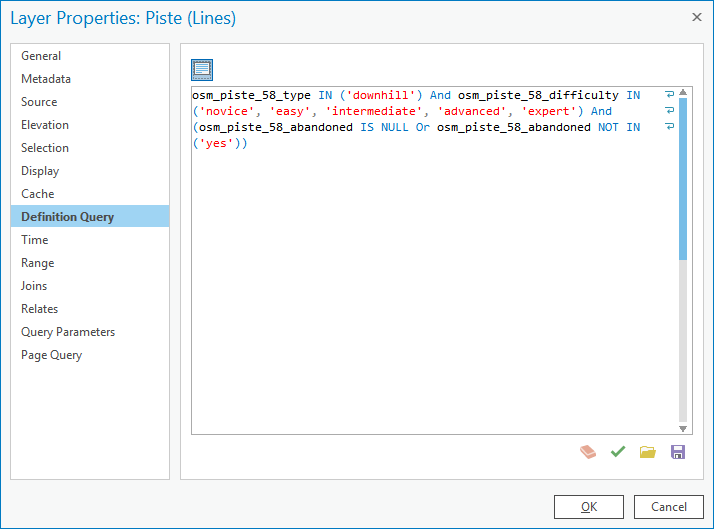
If I insert the Definition Query in DBeaver IDE, and prepend it with the necessary SELECT...FROM... that is missing in the Definition Query itself, and run an execution plan, the query runs in less than 3 seconds (2163ms) and returns 38697 rows, so just under 40k records. The execution plan shows the database correctly using the available index ("Index Scan"):

The problem:
When I attempt to open the Attribute Table in Pro by right clicking the layer and choosing "Attribute Table", Pro, instead of showing the records near instantly as it should based on the 3 seconds execution plan, instead takes > half an hour to open the Attribute Table. This is the time needed for a full table scan. When it is finished, it does show the proper 40k records, so the final selection was made.
When I enable logging in PostgreSQL and check the created log, I can see the SQL generated the moment I open the attribute table. Much to my surprise, even though the Query Layer had a Definition Query set, this Definition Query is not set on the SQL send to the database to restrict the binary cursor being created, as a consequence, the entire table seems subsequently to start being scanned in chunks of 1000 records, see the FETCH FORWARD 1000 statements in the log. This seems to go on the entire half hour, until a full table scan of all the millions of records is done, and the final table is created. As I wrote above, the final result in the Attribute Table, does correspond to the Definition Query, and is only the 38697 rows.
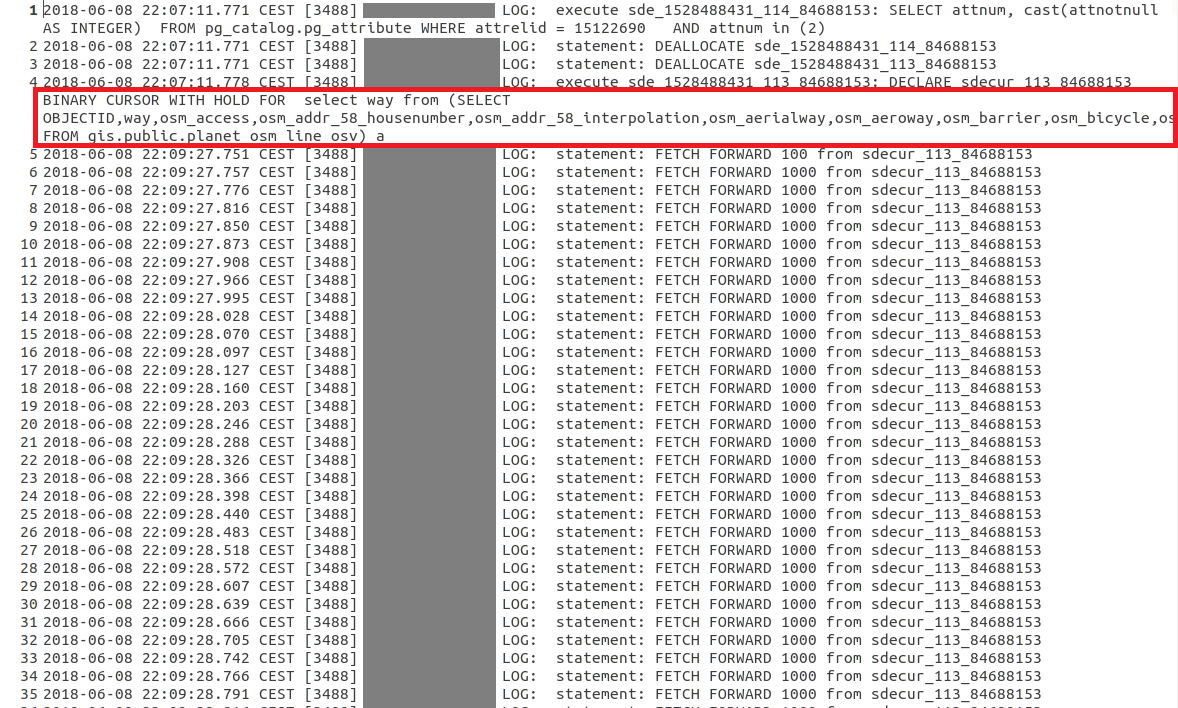
To inspect this better, I copied both the cursor statement that is initially used to create the layer (which is fast!), and compared it with the above statement representing the opening of the Attribute Table in an OpenOffice document, see the below screenshots. Notice how the first screenshot, which represent the moment the layer is created when the Pro Map document is opened and the TOC layer generated, does contain the Definition Query in the WHERE statement. This WHERE statement is omitted though, in the second screenshot that represents the opening of the Attribute Table:
- Creation of Query Layer: 
- Opening Attribute Table:

Am I missing something here, or fundamentally misunderstanding what is going on and misinterpreting this data? Why is there no WHERE statement submitted to the database when opening the Attribute Table of a (Query) Layer?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Michael Volz schreef:
@Marco:
...
Would you consider the behavior in the below thread another fundamental flaw with a query layer going back to database for a full table scan:
Can't tell from your description. You really need to be a bit more specific in the problem description. How did you "perform a query on the data to get a subset" or "create a selection from the subset of values"? What tools or menu options did you exactly use?
As to being presented with a list of unique values not related to the selection / query:
- In my opinion, it would be better if there was at least an option to have the presented unique values restricted to the initial query, or the full list of unique values of a column.
- Being presented with the full list of unique values of the entire column does not necessarily mean a full table scan is taking place. If there is a proper index on the column, the database likely returns the necessary result from there. Do you see any indications of a true full table scan, like (extremely) long delays on layers with many records, like I did?
The reason why I called the issue I presented a "fundamental flaw" is that I really think any system like a GIS that works with huge datasets, should try to avoid doing full table scans at all cost. Full table scans on giant datasets are costly, and can cause a huge amount of unnecessary network traffic in a case like the one presented here.
If there is any source for a SQL restriction, like a spatial constraint (being zoomed in), or any form of valid attribute selection (whether directly included in a Query Layer's source SQL statement or in the Definition Query of the layer as in my case), it should be applied. In fact, there is a discrepancy here as well in Pro, if you look at my Original post, you can see that ArcGIS Pro, does append the Definition Query to the SQL used to create the Query Layer when I open the saved Map document, it just doesn't do it when the attribute table is being opened.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marco,
I am unable to forward this to a specific analyst. You would need to create a technical support case. It sounds like there needs to be a specialist to look into this behavior.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@George Thompson,
At your request I just send in a support question to the Dutch branch of ESRI, pointing them to this GeoNet thread. Don't know if they will respond though, but hopefully they will. I referenced your request in the e-mail by the way, I hope you don't mind.
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No worries. That works for me.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think I have another interesting observation to share, that also reveals some of the "inner workings" of Query Layers, and their intertwinement with what ESRI used to call SDE but is actually the foundation of the access to databases in ArcGIS products.
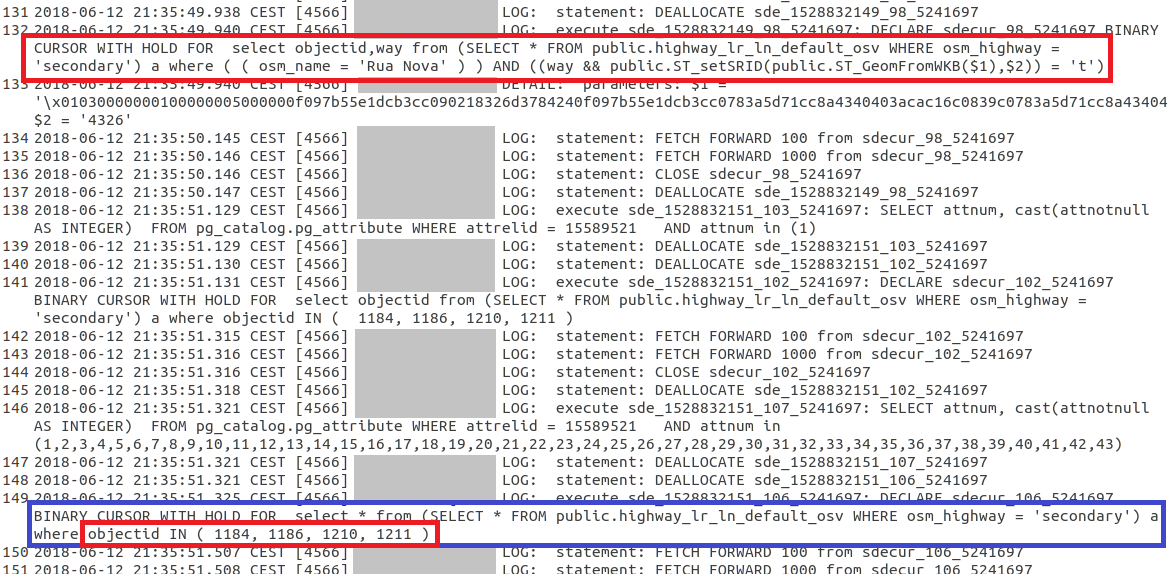
If you look at the screenshot, you see again two SQL statements, this time run against a much smaller PostgreSQL database than the original one I posted about, but a comparable situation with a Query Layer. The first highlighted SQL statement was issued to the database once I clicked the layer visible in the TOC, and shows actually two WHERE clauses: one I added to the Query Layer's SQL statement directly: WHERE osm_highway = 'secondary', and the other one I added as a Definition Query of the same layer: where ((osm_name = 'Rua Nova')).
Further down highlighted in blue is the SQL statement that was fired when the I opened the attribute table. There are in fact four records that have satisfy the osm_name = 'Rua Nova' clause, however, interestingly, this clause is not included as the WHERE statement, but instead the actual OBJECTIDs of the records corresponding to the clause mentioned.
It appears, once a layer is created, all the OBJECTIDs corresponding to the layer's defining SQL statements, are likely kept in memory and submitted to the database in one long IN (...) statement. That is the "inner workings" I meant. So Pro does submit a WHERE clause in this case, even though it is not the one I expected.
Even more puzzling of course, is that this seems to work for this small layer, but failed on the giant 65M record layer. Now I am pretty sure, and there is of course no reason for this, that Pro won't attempt to build an IN (...) clause for 65M records all at once, which would probably fail, but instead likely only needs to build such IN (...) statement for the first 2000 records or so that an attribute table usually displays once it opens (you can't show 65M records on a screen at once...). But even this likely limited operation seems to fail in the case of this giant layer.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have been doing a bit further investigation, and I think I now better understand what happens. To explain this, look at the following to scenario's:
1) A Query Layer with a SELECT * FROM TABLE_NAME type query, and a layer's Definition Query set to e.g. FIELD_NAME = 'X', so no WHERE clause included in the SQL statement of the Query Layer, but only in the Definition Query.
This situation always triggers a full table scan. It seems ArcGIS only evaluates the Query Layer's SQL statement when communicating with the database, and ignores the Definition Query. The Definition Query is only evaluated after or during the full table scan at what must be the ArcGIS Pro application level, instead of in the database. Opening an attribute table of a very large table of such a layer, is thus very slow due to the full table scan.
If there is no Definition Query set and you attempt to open the Attribute Table, Pro also seems to do a full table scan. I think it shouldn't, it should only request the first 100 or 2000 or whatever number of records of the table, and present those to the user, e.g. using a LIMIT request to the database. Since there is no Definition Query set, it doesn't really matter what records of the (potentially huge) underlying table are shown to the user. Any records will do. This would be much faster.
2) A Query Layer with a SELECT * FROM TABLE_NAME WHERE FIELD_NAME = 'X' type query, so the WHERE statement included directly in the Query Layer's SQL, and a layer's Definition Query empty or some other query.
This situation does cause Pro to send WHERE clauses to the database, albeit being based on OBJECTIDs. If the WHERE only selects a small amount of records from the total records set of the table it references, the Query Layer's attribute table will open fast.
So the big take away from this is that, whenever possible and especially with huge database tables with tens of millions of records, you should always directly insert a subsetting WHERE statement in the Query Layer's SQL statement directly, and not in the Definition Query.
You would in essence expect these two scenarios to be equivalent, but from the application point of view - at least with the current implementation! - a Query Layer with no WHERE in the SQL of the Query Layer itself, but just in the Definition Query, is the equivalent of just dragging and dropping the entire spatial database table in the TOC.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For comparison, I have now also looked at what happens in ArcMap, and there does seem to be some vital differences.
What I did:
- Drag & drop the huge table in ArcMap (You can't actually do this yet in Pro by the way!) from ArcMap's Catalog window. ArcMap then opens a dialog about the need to calculate the "spatial extent". This is also a slow operation in ArcMap, which also seems linked to a full table scan (which I also do not fully understand, can't this information be derived from the spatial index much faster?). The SQL of the resulting Query Layer is equivalent to the SELECT * FROM TABLE_NAME of the last post, albeit with the * wildcard replaced by a full list of all the database columns of the source table.
- Without any Definition Query set, I opened up the Attribute Table in ArcMap. This is still a slightly costly operations, taking one or a few minutes, but not nearly as bad as in Pro taking half an hour in the same situation.
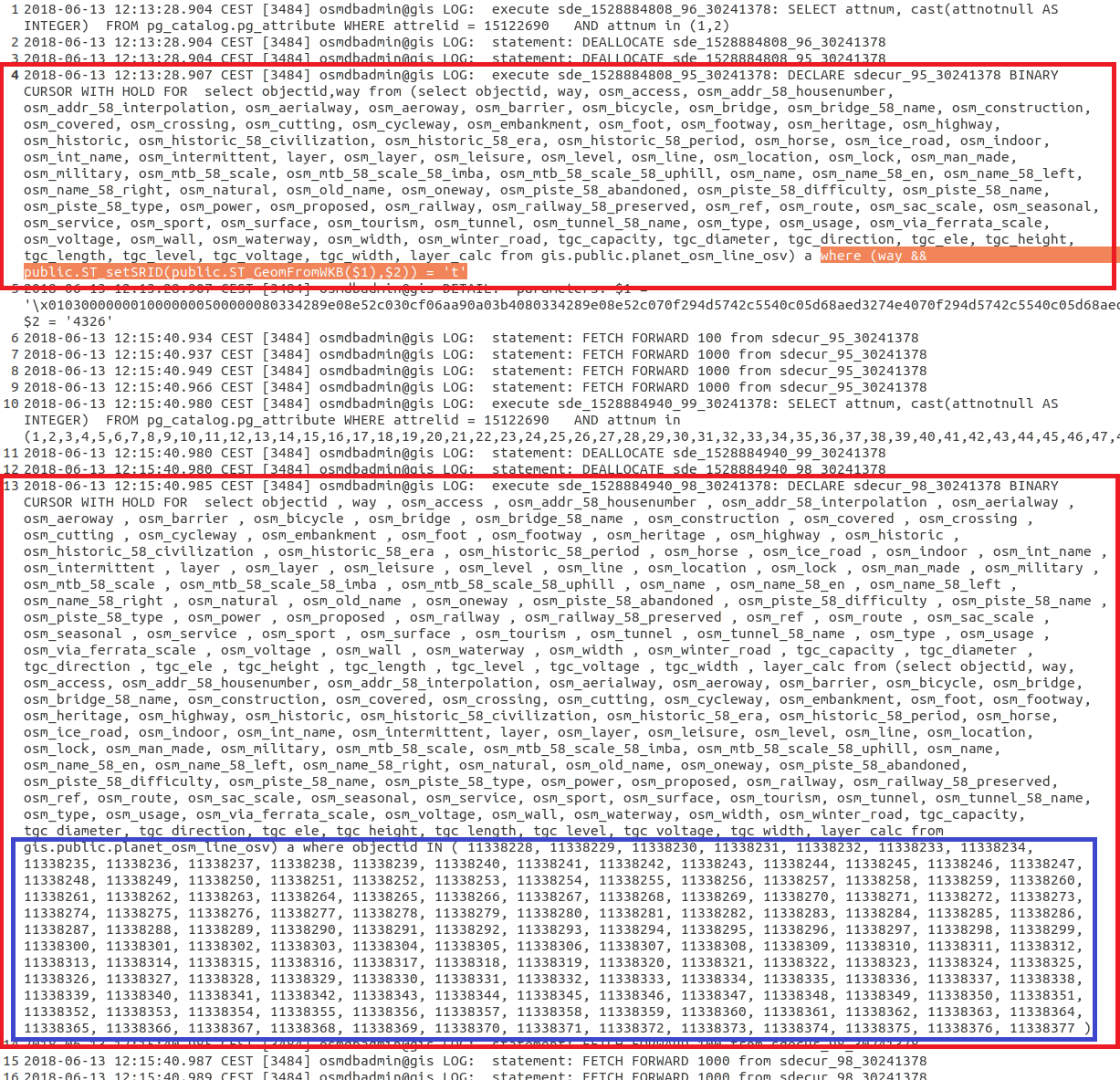
Now, when I look at the PostgreSQL logs, I see at least one difference with Pro. Opening the attribute table seems to happen in two steps. Notice that when the first BINARY CURSOR is created, the SQL statement contains a WHERE clause with what appears to be a spatial constraint. I think I saw this step happening in Pro as well.
Anyway, when you look at the second highlighted BINARY CURSOR being created, which represent the moment ArcMap really starts creating the actual contents for the Attribute Table of the Query Layer, you will notice (highlighted in blue) that ArcMap actually does restrict the record set to the first 100 records or so, by inserting their OBJECTIDs as part of the a large IN (...) statement.
I also did another observation regarding ArcGIS Pro: when I open the Attribute Table the first time, it takes half an hour. Any subsequent opening of the Attribute Table is much faster, and seems equivalent to ArcMap.
As a consequence, I am now getting convinced that the behavior I am seeing is actually NOT A BUG, but a change in how ESRI decided to handle Query Layers and specifically the calculation of the spatial extent of such Query Layer:
- In ArcMap, when you drag a spatial database in the TOC, a dialog opens up explicitly warning you that the "spatial extent" (Calculate Extent is the title of the small dialog) is being calculated and that this may be a costly operation (likely due to the full table scan taking place in the background), and even offers override options by allowing you to manually enter them, or use the Spatial Reference's maximum extent.
- In ArcGIS Pro, no such dialog pops up. Instead, it seems to leave a kind of "unitialized" layer in the TOC. What then happens is that Pro appears to start calculating this spatial extent the first time you open up the Attribute Table or use some geoprocessing tool on the layer, like I have witnessed with the "Apply Symbology From Layer" tool that takes forever to open up when such a Query Layer layer is present. Afterwards, this information seems cached, and being re-used the next time you e.g. open the Attribute Table of the Query Layer.
While Pro's implementation takes away the "annoying" spatial extent calculation dialog that pops up in ArcMap, the ArcMap method, with an explicit calculation when you add the data, is far more desirable for large layers, as it won't lock up the application in an unexpected manner for long periods of time without the user knowing why.
If I am right, I also think the calculation of the spatial extent of Query Layers really needs to be reviewed by ESRI and find out if there isn't a much more efficient way to do this, e.g. by taking a "random sample" of e.g. 1% of the records in case of large tables. It now seems to require a full table scan both in ArcMap and Pro, which is outrages in the context of database tables of tens of millions of records. I do not know if there are restrictions I don't understand, that ESRI has to abide by, that cause the current implementation in ArcMap and Pro regarding this, but it would be highly desirable to have a much more efficient method for this, thus taking away a performance bottleneck on Query Layers based on millions of records.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Excellent analysis. I hope this leads to a solution where both ArcMap and ArcPro handle query layers better than they currently handle them. IMHO this appears to be a bug in both software packages, thus I would think it should be fixed in both ArcMap (ESRI is still fixing bugs even if they are not making enhancements to the software) back to at least v10.5.x and their software of the future (Pro).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Marco:
Are you creating a materialized view or logical view for your query layer from the Postgre database?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Michael,
I have explored all three possibilities:
1) - Inserting complex SQL statements straight into the Query Layer's SQL (which is of course, and slightly understandably, the least optimal option from a performance perspective).
2) - Created "logical" or normal spatial views at the database level using the ESRI "Create Database View" geoprocessing tool (although this could just as well be done using PostgreSQL compatible tools like the DBeaver I have been using) and inserting the same SQL of the first option as view definition.
3) - Materializing the views created in 2) and accessing these from ArcGIS using a Query Layer (note again this is non-geodabase spatial database). Of course, this option is by far the most performant, especially since you can index the materialized views as well, which I did.
Nonetheless, all three options ultimately require a Query Layer to access the data, the Query Layer's SQL statement just simplifies with options 2) and 3).
Although I have written in my last post that part of the issues I see, may not be a bug but "by design", I do still think the chosen solutions for handling Query Layers are suboptimal concerning the spatial extent calculation and the usage of a potential Definition Query on the layer to limit the number of records:
A "Definition Query" is exactly what its name describes: it is supposed to "define" what records belong to a layer. Ignoring the Definition Query in the context of a Query Layer as seems to happen in the specific cases I encountered, is at the very least sub optimal.
Anyway, as I also wrote before, there may be issues or limitations ESRI has to deal with that I cannot really understand right now. Let's see what ESRI has to tell when I get a response on my support call. I have at least had confirmation of the Dutch branch of ESRI that they put this call through to ESRI inc, so let's wait for the response.