- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Geodatabase Questions
- :
- File geodatabase in Windows networks very poor per...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
File geodatabase in Windows networks very poor performance
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I'll try to keep this short. I represent a large goverment organisation in Sweden. I am a GIS coordinator for the user side of the organisation and of my daily tasks is to recommend best practices, to keep performance up within the typical large organisation restraints (central SDE, network drives)
I have a benchmark script that does this:
1 - creates two file gdbs at the same location (arcpy.CreateFileGDB_management x 2)
2 - creates two empty featureclasses in one of them (arcpy.CreateFeatureclass_management x 2)
3 - exports both featureclasses with one command (arcpy.FeatureClassToGeodatabase_conversion(fcs))
4 - then exports them both again, this time one by one
When I do this on my local harddrive, i.e. my computer, it takes around 10 seconds all together to execute the script.
When I run the script on a network drive, it takes upwards of 8 to 10 minutes (!!!!!)
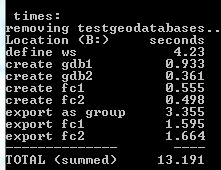
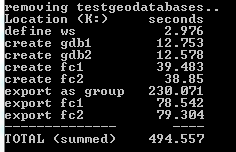
Where do I start? Any good resources I should read? I am not a windows network specialist and I have no idea why it is like this. Any feedback is greatly appreciated, thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
WIndows shares will always be slower than using a local drive and your network will determine how much slower. You've already benchmarked performance, but if you want to take ArcMap/Esri products out of it, you can use Python to create/delete files on the share or IoZone, which can provide benchmarking statistics for throughput on reading/writing to directories:
You'll likely need to involve the organizations IT staff.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree with Jonathan, it is best to look at performance outside of Esri applications first. It may be that your performance bottlenecks have little to do with Esri applications, or maybe it is just the opposite.
Are you running this on a local PC or in a centralized or virtualized environment like Citrix?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for your feedback so far.
Joshua, I am running on a physical laptop with a network connection. No Citrix or Virtual Machine.
I've hacked together a new script that creates 100 files, writes some stuff in them, reads it again, and deletes the file. Our general IT infrastructure is set up as: A centralised IT department 300 miles away that has the physical servers. They organise the networks etc.
K: - this is a DNS/DFS (?) pointer to a local server in my building. this is used to set up alias' to hide certain folders etc. Basically, so IT can better manage everyone.
J: is a direct UNC mapping to the same physical local server (that K: points to)
B: is my local harddrive.
So the script repeats the same process X times and records the overall time, as shown below. All the random filenames and paths are pregenerated.

This is my timing output:
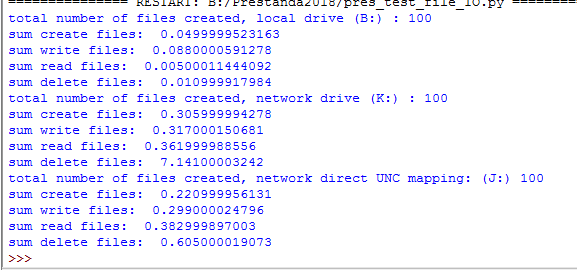
So, it appears that the delete operation is causing a lot of time. I am asuming this has to do with permissions and network control to the files. Does this give any of you really smart people an idea of where to start my search for the underlying problem?
I have heard that the fgdb format is very "chatty" in terms of network utilization, and with the approach of ArcGIS Pro, where everything is designed to work in fgdbs, we are looking for official recommendations. But for now, I'll happily take inofficials ones!
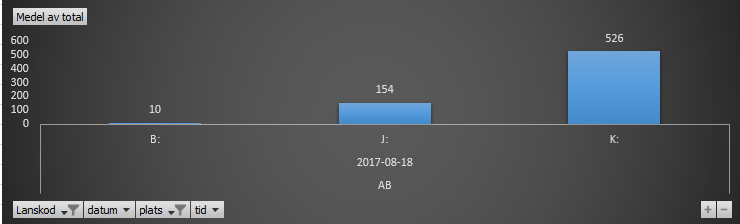
When I run my benchmark test against the UNC mapped server, I get better performance, but still not nearly as good as I would like. These are my results from averaging out several runs last year:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Although your tests are a start, the steps in your tests are not very representative of I/O patterns from ArcGIS software to a file geodatabase. That said, the results can still be used to glean some information. Looking at the results from J:, the times range from 3.4x slower (writing files) to 76.6x slower (reading files).
The results from your ArcGIS tests show that J: is taking 15.4x longer than B:. Seeing that your ArcGIS tests will involve a mixture of creating, writing, and reading files on the file system, and those operations range from 3 to 75 times slower on J: than B:, I don't think seeing a 15x slower time to J: with your ArcGIS tests is that unexpected.
I would say that what you are seeing in ArcGIS are symptoms and not the problems themselves. Optimizing SMB/CIFS performance is very involved, and it surely is outside the bounds of GIS, i.e., your IT department should not expect you (a GIS person) to be providing them direction on optimizing SMB/CIFS performance.
If your J: drive is hosted on Windows Servers, you can start by reading Performance Tuning for SMB File Servers | Microsoft Docs
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Joshua, thank you for a very helpful response. There is no doubt that I need IT's involvement, but in all honesty, it has been hard to get them to prioritize this 'niche' problem in a 10k person organisation, when they have to deal with all day-to-day support as well. I'm trying to gather enough input from here to help narrow down their search window. And yes, the solution is definitely beyond my skillset.
I have two more questions Before I go to my IT department:
1 - for ESRI / Jonathan Quinn: Are there any official recommendations from ESRI regarding setting up a large Enterprise Environment with file share servers, central SDEs, and a multiple users spread out geographically? We are your typical run-of-the-mill government organisation, using windows servers (R2012)? Any official recommendations and documentation on "best practice" etc would be greatly appreciated.
2 - During my benchmark test, there is a clear pattern evolving:
If exporting a featureclass by itself takes time t, then exporting them as a group ((arcpy.FeatureClassToGeodatabase_conversion([fc1,fc2]) takes 3 x t
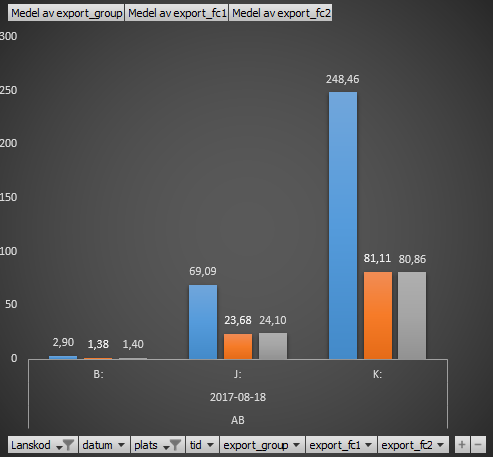
This to me sounds like that system is waiting for a lock in the file system to time out. If you have any input on what to look at more specifically (OpLocks,SMB file caches and other fancy terms I have come across..), it would be very helpful.
Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
And let me just add that the fgdb, with two featureclasses is ~150kb .. and it takes 8-10 minutes to move the data (two empty feature classes) over the network. Hence my suspicion on the network protocol and/or how fgbd are 'chatty' with their operations.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree that 8-10 minutes for ~150 KB is excessive, even on a high-latency network connection. That said, troubleshooting issues like this takes some thorough knowledge of the GIS software, IT in general, and access to certain types of tools. Honestly, it could be something like antivirus software or some other monitoring software your organization has deployed that is hanging it up.
When I come across these issues, I usually start by doing process monitoring/profiling, using something like Process Monitor - Windows Sysinternals | Microsoft Docs , to see both what ArcGIS is doing but also other processes on the computer. I would also ask the network operations group to do package captures to see where the delays or errors are happening at the network layer. I would ask the system administrators for both the SMB/CIFS server configurations as well as what warnings or errors they are seeing with your connections.
You can start to see the picture, troubleshooting is more of an art than a science, and there are no special tools or sequences of steps that will lift the rug on the root cause. If the skills or access to systems doesn't exist within the GIS shop to troubleshoot this issue, then it becomes about selling your leadership to sell leadership above them that resources need to be devoted to improving this situation.
Have you tried other tools besides Feature Class to Geodatabase? If passing a list of feature classes takes longer proportionally than passing a single feature class, what about looping over the list and passing them individually?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks again Joshua! Yes, I have tried different tools, read and writing from geodatabases vs shapefiles etc. In the past, I had a a script that did some common geoprocesses, select, clip, definition query, export selection and projection on relatively large datasets. I had copies of the data set up in shapefiles, SDE environment, fgdb on the network to simply try to figure out what the issue is.
performance testing, same operations, different datasources; SDE, fgdb, and shapefiles. H: here is the same as J: above, i.e. a UNC direct mapping to the server, where K: is a normal dfs redirect, or whatever the technical term is..
The bottom line is: file geodatabase performance is absolutely horrible in our network. I am at a loss. I am simply trying to find out here if someone has "the magic word" that I can use with my IT-department (with some reference documentation), because somewhere, someone did something 'smart' in our network configuration that causes this. We are a standard run-of-the-mill organisation in a windows server R2 2012 environment, Win7 / Win10 laptops, centralized SDE, and network drives hosted on servers.
In fact, if someone here in a similar network environment is interested in doing a benchmark test with my script I would greatly appreciate it. Contact me at: kristian.herner@lansstyrelsen.se
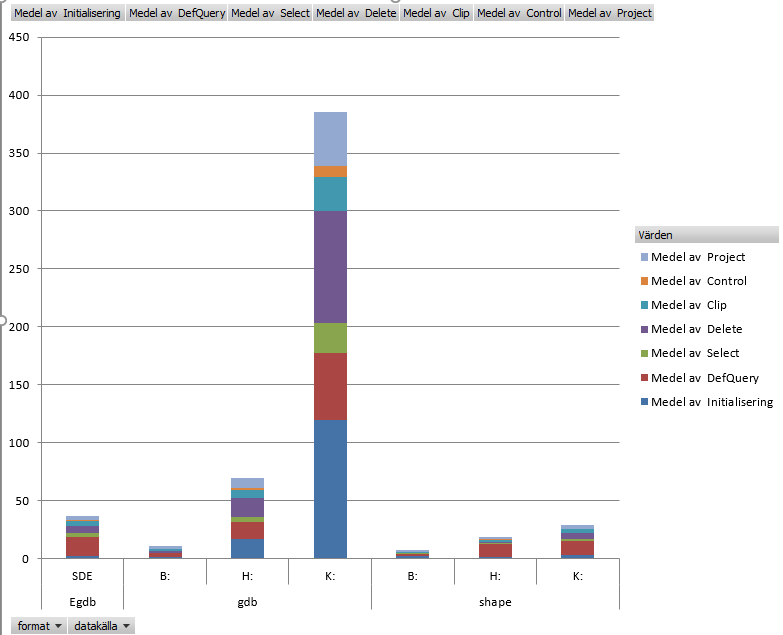
Edit: In the above, the y-scale indicates times in seconds to perform the operations, "H:" is the same as J: above, a direct UNC mapping to the network drive.
This script answers a simply question: "can you help me find all the school building in a certain municipality and deliver it with a different projection?" - so I 'Initialize' my workspace, use 'definition query' to get all the buildings with "school" attribute from a pool of 1 million+ buildings, I 'select by attribute' the municipality polygon, 'Clip' the these two files and 'project' the result to an outfile. I then use a da.cursor to 'control' the number of objects in the outfile, to verify the script ran succesfully. This operation took about 8 seconds with shapefiles on my local drive on average and about 6-7 minutes from geodatabases on my network drive.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the past, I had a a script that did some common geoprocesses, select, clip, definition query, export selection and projection on relatively large datasets.
...
somewhere, someone did something 'smart' in our network configuration that causes this
I read those two lines as saying you have done this same workflow in the past and it ran much faster. If so, how long ago did it change? What were the speeds, ball park, when it used to run better? Between now and then, has anything changed in your GIS software? New programs, versions, etc...?