- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Geodatabase Questions
- :
- Re: Code field based on rank of another field.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi all,
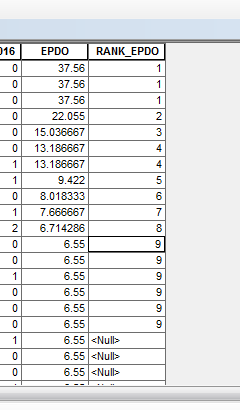
I would like to have all the records in a table given a rank value based on the values in another field. The caveat is that there are tied rankings. For example in the attached screen cap, EPDO is the data to rank, and RANK_EPDO is field to store the rank. Anyone aware of any tools in ArcGIS that will accomplish this?
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
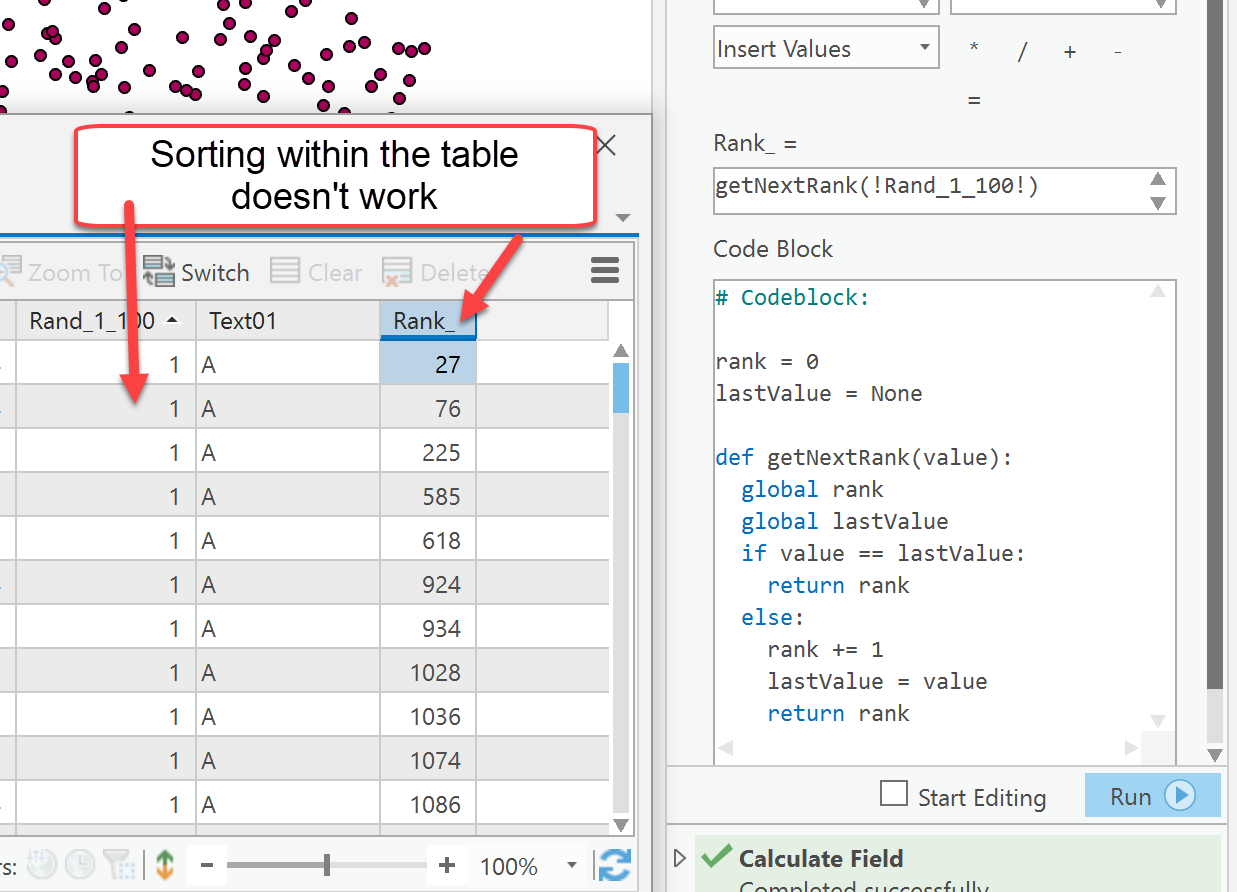
BTW, If you just sort the table, the code won't work unless it is permanently sorted.
Here is an example where the key field was sorted (many values of 1) and notice the ranks are essentially those of the objectid as they were encountered.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
That is one way that tied ranks are dealt with... It is sometimes referred to as 'rankmin'.
I bet your next rank is 15 and there is no 10,.... 14 is there?
What you are supposed to do is randomly choose from on of the 9's to represent their kindred
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
BTW, If you just sort the table, the code won't work unless it is permanently sorted.
Here is an example where the key field was sorted (many values of 1) and notice the ranks are essentially those of the objectid as they were encountered.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Good catch, I only tested that against data that was already coincidentally sorted that way on another field. I'm going to delete my earlier post so it doesn't mislead anyone.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
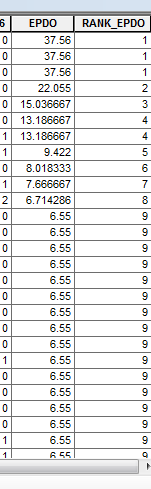
Thanks all. As mentioned, as long as the table is permanently sorted first w/ the Sort Tool, the above code works.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I got the above code to work to rank my data overall by score (descending - so high score gets a rank of 1), but I would also like to rank scores by 1 or 2 other fields for example within Watershed and within Watershed and County. Is there a way to add this to the code in Calculate Field?
For example
| Score | Watershed | County | Overall Rank | Rank_win_Watershed | Rank_win_WatershedCounty |
| 30 | A | 1 | 5 | 2 | 1 |
| 10 | A | 1 | 7 | 3 | 2 |
| 70 | A | 2 | 1 | 1 | 1 |
| 25 | B | 1 | 6 | 2 | 1 |
| 40 | B | 2 | 4 | 1 | 1 |
| 30 | C | 1 | 5 | 3 | 1 |
| 60 | C | 2 | 2 | 1 | 1 |
| 55 | C | 2 | 3 | 2 | 2 |
Many thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
In case anyone comes across this and doesn't/can't have permanently sorted data...
Was thinking about this some more this evening, trying to come up with a way to solve the case where the dataset isn't permanently sorted using the field calculator... Don't think it's possible using the calculator since to the best of my knowledge you can't do a look-ahead/sort, but using the Python window this should work:
def applyRanks(layerName, valueField, rankField):
# Read the values from the dataset
allValues = set()
with arcpy.da.SearchCursor(layerName, [ valueField ]) as searchCursor:
for row in searchCursor:
allValues.add(row[0])
# Create a value/rank lookup
lookup = { value : rank + 1 for (rank, value) in enumerate(sorted(allValues, reverse=True)) }
# Set the ranks on the rows
with arcpy.da.UpdateCursor(layerName, [valueField, rankField]) as updateCursor:
for row in updateCursor:
row[1] = lookup[row[0]]
updateCursor.updateRow(row)Once added to the Python window, a call like this (using the fields from the original question) should apply the ranks:
applyRanks("theLayerName", "EPDO", "RANK_EPDO")- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thanks for the code!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Without using an ORDER BY clause with your cursors, this approach could result in the rankings generated by the search cursor being incorrectly applied with the update cursor.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
As Dan spoke to in his first reply, there are multiple ways to handle ranking when ties are involved. You appear to be using dense ranking, which is fine, but I would argue is not the "default" or most common technique for dealing with ties. If you are working with dense rankings, I recommend your column heading include the word "dense" or an abbreviation for it.
Modifying the code from one of my responses on GroupBy 2 columns and keep all fields, I came up with a single-pass cursor approach that uses 1 or more sorting columns:
from itertools import count, groupby
fc = # path to feature class or table
sort_fields = ["EPDO"]
rank_field = "RANK_EPDO"
sql_orderby = "ORDER BY {}".format(", ".join(sort_fields))
with arcpy.da.UpdateCursor(fc,
sort_fields + [rank_field],
sql_clause=(None, sql_orderby)) as cur:
cntr = count(1)
for key, group in groupby(cur, lambda x: x[:-1]):
dense_rank = next(cntr)
for row in group:
cur.updateRow(row[:-1] + [dense_rank])
del cur