- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Data Management Questions
- :
- sql geometry group by
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
2 issues...
1) I have 2 polygon feature classes in my SQL Server database. I want to know how many of our small polygons (parcels) are contain in the bigger polygon (municipalities) based on the centroid, but the result I want is a spatial view I can add graphically to my map. The desired map would be something like...
| Shape | Municipalities | Count |
|---|---|---|
| xxx | municipality1 | 5 |
| xxx | municipality2 | 45 |
| xxx | municipality3 | 95 |
The problem is that I don't know how to create the spatial view to add to the map because I received the error message...
"The type "geometry" is not comparable. It cannot be used in the GROUP BY clause."
when running the statement...
select b.shape,COUNT(a.shape) as shape
from admin.PARCEL a, admin.MUNICIP b
where b.SHAPE.STContains(a.Shape.STCentroid())=1 and a.PIN like '328-02%'
group by b.shape;
Tried the STUnion approach but the result is redundant geometries (municipality geometry for each parcel polygon it contains).
2) Our second concern is that we want to create an indexed view to test the statement above when succesful, and from what I understand the statement can't use subqueries to get created. I ran the group by statement without the shape and it took almost 17 hours, so we want to see if any performance improvement is detected. The parcel feature class is update daily by syncronizing a replica.
Any ideas or suggestions are welcome.
Thanks
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Although you may have a reason for doing this with sql geometries as opposed to a geoprocessing approach, with a processing time of over 17 hours and only the need for daily updates you should at least consider a geoprocessing approach as an alternative. You can use the Feature to Point tool with the inside option to extract the centroids of the parcels and then the Spatial Join tool with the One to One option with the Municipality polygons as the target and the centroids as the join type.
Since you didn't mention how many points and polygons you were working with, I did a test on my own data as a reference. To extract over 800K parcel centroids in my County using the Feature to Point tool took 6 minutes and 13 seconds and to use the Spatial Join tool to join those points to 28 cities and the unincorporated area of my County to get the count of parcels and sum of acreages (an attribute retained by the Feature to Point tool) of the parcels in each took 23 minutes and 11 seconds. So the total processing time of both steps was 29 minutes and 24 seconds.
Anyway, hopefully that should give you an idea of how much time a geoprocessing approach should take with your data and whether or not it is a viable alternative. I would be interested in knowing how much data you were processing so I could do the same comparison.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I am not sure what your unique identifier is for municipalities, so I went with "id."
SELECT m.shape, m.municipality, s.parcel_count
FROM admin.MUNICIP m,
(SELECT sm.id, count(*) as parcel_count
FROM admin.PARCEL sp, admin.MUNICIP sm
WHERE sm.shape.STIntersects(sp.shape.STCentroid()) = 1
GROUP BY sm.id) s
WHERE s.id = m.id
If you only wanted parcel count by municipality, without the associated shape, then the subquery itself would do the job. Since you want the associated shape, you need to join the subquery results back to the municipality layer for mapping purposes.
Performance wise, I am not sure how the above code will do. You mention 17 hours, that does seem excessively long. There are several things that could be going on. One could be poor or nonexistent spatial indexes. Check the execution plan to make sure spatial indexes exist and are being used. I am also thinking that converting to a centroid on the fly could cause a performance hit. For the minimal storage hit of adding a point field, it might make sense to store both the parcel polygon and centroid and then index both of them. Also, if the parcel count isn't changing very much on a minute or hourly basis, it might be worth considering computing it once a day and storing the value for mapping and reporting.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
I did a quick performance check of the code above using pre-computed centroids stored and indexed versus generating centroids on the fly. The latter approach took over 5x longer to run, and that was on a fairly modest-sized dataset.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thinking back to the statement about a point-in-polygon query taking 17 hours to run, my guess is that you have some complex or dense municipal boundaries. SQL Server, even Enterprise Edition, doesn't seem to handle point-in-polygon queries well when there are complex or dense polygons. Some say it is tied to MS's implementation of quad-tree spatial indexes or a limitation of quad-tree indexes for spatial data. I am not deep enough into databases to really have an informed opinion, but I do have to tweak spatial indexes much more in SQL Server than in PostgreSQL/PostGIS.
For the complex/dense point-in-polygon situation, I think there is something more with how SQL Server implements some of its spatial methods. If you either don't or can't go down the geoprocessing route, I encourage you to read through this MSDN forum thread on SQL 2K8R2: Any performance hints for bulk loading data from spatial/GIS db into a data warehouse? Although the title doesn't make it seem relevant to this post, it is. The author of the thread has an approach and some code for using tessellation or on-the-fly partitioning to break up complex polygons and dramatically reduce run times. I have successfully used the technique and seen reductions of 90%+.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
This is the same issue I blogged about. True tesselation isn't necessary -- simple gridding will suffice. The important part is reducing the vertex count
- V
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Vince Angelo, I remember that blog post. It was quite interesting and good material to be referenced and looked at in relation to this discussion. I very much look forward to seeing some of the ideas discussed in that blog post come to fruition, understanding they are side projects of course.
The reason I linked to that thread in the SQL Server Spatial Forum was that I thought Jakub K's recursive-quartering tessellation scheme was fairly elegant, and quite simple to implement through a couple table-valued functions. From what I have seen, the geoprocessing/spatial functions in question do seem sensitive to vertex count, so reducing vertex count definitely helps.
For most datasets, maybe tessellation is overkill and gridding will suffice. For one of the datasets I was working with, that wasn't the case. Looking at a gridding scheme and recursive-quartering tessellation scheme that both generate similar numbers of partitions for one of the complex polygons in my dataset, one can see how the tessellation balanced out the number of vertices better.
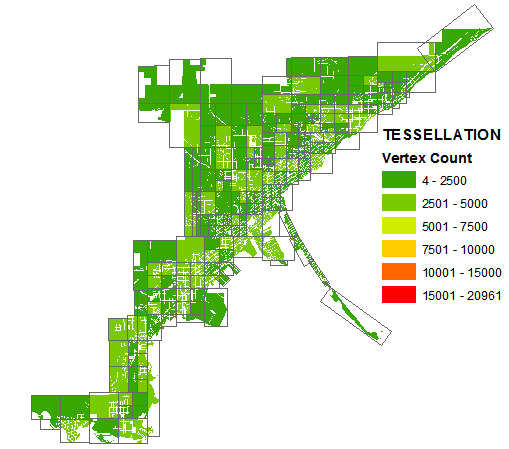
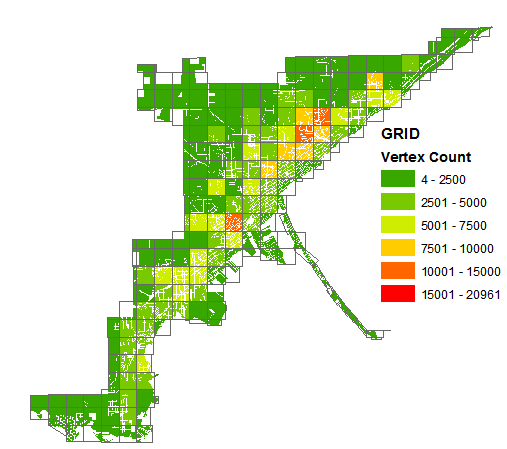
Balancing out the vertices better allowed for the next part of the geoprocessing/spatial functions to execute quicker. Using just the DBMS, no RAM caching, the recursive-quartering tessellation scheme got me in the range of 0.5 ms/feature while the gridding scheme was closer to 1.5 ms/feature. I admit I didn't spend much time on optimizing a gridding scheme, so there is likely room for improvement there, but I am not sure if a more efficient gridding scheme alone will do much better than the current overall performance of using the tessellation scheme.
I am pretty content with 0.5 ms/feature, and Jakub K's tessellation scheme got me there, so I thought I would share. I know there are techniques that can get even better performance, but for now that extra investment isn't necessary for my situation.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Although you may have a reason for doing this with sql geometries as opposed to a geoprocessing approach, with a processing time of over 17 hours and only the need for daily updates you should at least consider a geoprocessing approach as an alternative. You can use the Feature to Point tool with the inside option to extract the centroids of the parcels and then the Spatial Join tool with the One to One option with the Municipality polygons as the target and the centroids as the join type.
Since you didn't mention how many points and polygons you were working with, I did a test on my own data as a reference. To extract over 800K parcel centroids in my County using the Feature to Point tool took 6 minutes and 13 seconds and to use the Spatial Join tool to join those points to 28 cities and the unincorporated area of my County to get the count of parcels and sum of acreages (an attribute retained by the Feature to Point tool) of the parcels in each took 23 minutes and 11 seconds. So the total processing time of both steps was 29 minutes and 24 seconds.
Anyway, hopefully that should give you an idea of how much time a geoprocessing approach should take with your data and whether or not it is a viable alternative. I would be interested in knowing how much data you were processing so I could do the same comparison.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Richard, thanks for the suggestion. I was focused on a spatial view and completely forgot to test a geoprocessing approach. As Joshua mentioned, the performance hit for calculating the centroids is too much. I use the Feature to Point tool, which took about 11 minutes to complete (for approximately 1,389,663 parcels) and later ran the Spatial Join tool to obtain the number of parcels for each municipality (78 total) in about 16 minutes. Finally, since my municipality feature class is not versioned I just update the count field using SQL directly. Just need to be able to put it all together in the same script to automate the process.
Thanks again.