- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Data Management Questions
- :
- I am trying to calculate a field where i want to e...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
I am trying to calculate a field where i want to exclude any null values. For example. Field calulate field X with any value that is not null from field Y. I have been messing with python, but just can not seem to get this to run properly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If field X <> Null
then field calculate field Y with field X.
(using 10.4)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
since you are learning, nulls of any sort are treated as boolean False
>>> a = ""
>>> if a:
... print(a)
... else:
... print("null string")
...
null string
>>> a = "hello"
>>> if a:
... print(a)
... else:
... print("null string")
...
hello
>>>
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Only thing I might add is this leverages Falsy behavior in python. 2.3.1 Truth Value Testing
Something to keep in mind is that 0 can also be Falsy along with a few other values (empty strings etc).
Using
if value: (falsy)
is None
is not None
or even
isintance() built in is what I see over and over again. 😃
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes confusing isn't it... you have to know what an object or what it belongs to... a common mistake in numpy
>>> a = np.NaN
>>> isinstance(a,np.NaN)
Traceback (most recent call last):
File "<string>", line 1, in <module>
TypeError: isinstance() arg 2 must be a class, type, or tuple of classes and types
>>> type(np.NaN)
<type 'float'>
because you can't use zero... and the list goes on
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good to know about np.NaNs for that. I have been running into issues with that at work recently. NP methods for scrubbing NaNs seem best, but I have found masked arrays to be annoying in practice. Pandas seems to handle it a little better on the surface.
Do you have any good articles on np.NaN types specifically Dan?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Did you try searching GeoNet for an existing answer? I am quite sure this type of conditional field calculation has been covered a time or two. That said, see if the following works for you (apply to Field Y using Python parser):
!field_x! if !field_x! else !field_y!
!field_x! if !field_x! is not None else !field_y!
UPDATE:
Although my original code would have worked for most data types, it could have given incorrect answers with string fields.
Python doesn't have a data type called NULL/Null/null. The Python Built-in Types documentation states for the null object, "There is exactly one null object, named None (a built-in name)." If you are used to working with NULL in databases and SQL; be careful, None in Python doesn't behave exactly the same as NULL even though None is referred to as "the null object" in some documentation.
In Python there are several falsy values, i.e., values that are not false but evaluate to false in a Boolean context. Some common examples are None (the NoneType), "" (empty string), [] empty list, () (empty tuple), and 0 (the number zero). When using the Python parser with the Field Calculator or cursors with ArcPy, NULLs need to be converted, and Esri has chosen to convert them to None, which is understandable given the built-in data types available with Python.
The issue with my original code is that an empty string would have compared as False, the same as None, but an empty string is not NULL. Changing the code to explicitly check for None solves this issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm having problems getting this code to work in Field Calculator (as part of model). To try and make the background short: I have a model where I use a series of Select by Attribute then Calculate Field to score features on the value in the first field. It is being adapted for a webmap using Server, and apparently it can't use layers (so Jayanta's suggestion below won't help). I'm now using a series of Select, Calculate Field (in the output from Select), Join Field back to the original feature class, then another Calculate Field in the original feature class based on the value in the similar field in the output from Select.
Because there are multiple iterations of this sequence, I need to structure the last Calculate Field so that when the value is NULL/None, it doesn't overwrite what's been written in there before. I tried !field_x! if !field_x! is not None but I get the following error:
ERROR 000539: SyntaxError: unexpected EOF while parsing (<expression>, line 1)
Failed to execute (Calculate Field (2)).
I tried putting if !field_x! is not None in the code block, but I get the following warning:
ERROR 000989: Python syntax error: Parsing error
Indentation error: unexpected indent (line 1)
Any help you can offer is appreciated. Thanks a lot!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Deb,
The ! delimeter can only be used in the main Calculate Field expression, the value of the field for that row is subsituted in. So Joshua Bixby's approach would be to put this in the expression field parameter, not the code block. (Note this fancy but useful construct was a late (2.5) addition to Python: the ternary if.)
!Field_Y! if !Field_X! is None else !Field_X!Another approach to consider is to use Model Builder's Calculate Value tool and write a function for the code block that uses an update cursor. This is a desirable method when the 'if then' logic gets more complex. A limitation of this is that update cursors don't work on tables with an active join, but since you're using the Join Field tool (which does permanent joins by copying data across, not placing a join on the table) an update cursor would work for you.
# Calculate Value
# Expression
update(r"%input features%", !Field_X!, !Field_Y!)
# Code Block
def update(ds, fx, fy):
with arcpy.da.UpdateCursor(ds, [fx, fy]):
for row in rows:
if row[0] == None:
row[0] = row[1]
rows.updateRow(row)
return ds
# Data Type: Feature Class (or feature layer, table, etc)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks a lot! I haven't really worked much with more complex calculations, so this is good information for me. I updated my expression to include the else !Field2! at the end, and it worked. I had tried finding a way to make it pass the features where the Field1 value was null, but obviously that wasn't the right solution.
However, just before reading your message, I also got it to work by using the attached code block and expression (not as elegant though). 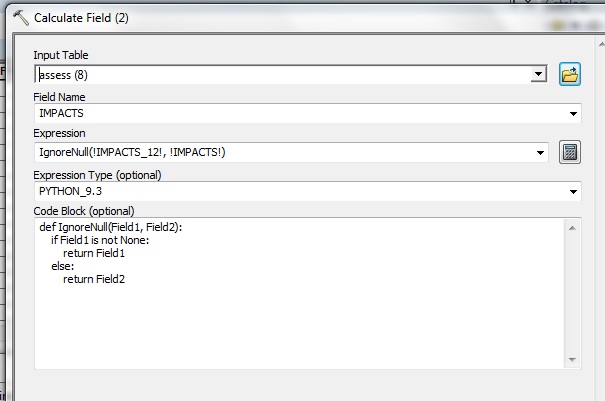
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you could do it using field calculator of attribute table, just follow these steps
1. Select by Attributes with following expression:
"Y" IS NOT NULL
2. Once selected, I would use Field Calculator on field "X", with the following expression
"Y"
Think Location