- Home
- :
- All Communities
- :
- Products
- :
- Data Management
- :
- Data Management Questions
- :
- Attribute table to CSV
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Hi, I have an attribute table with 5 million rows. I would like to export this to csv. Unfortunately my first tries are not successful. I have tried table to excel and export to txt file & dbf file. From my searches in google and here in the community, I cannot believe that just a csv export will require python or an additional install or a third party software. Am I missing any built in tool? . I would appreciate if you can guide a beginner since I have no idea how to run a python program. Or could give me any guidance how to achieve a CSV from table.
Thank you.
Ronald
UAE
Solved! Go to Solution.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You can use Export Feature Attribute to ASCII tool to achieve the desired output.
See below snapshot.
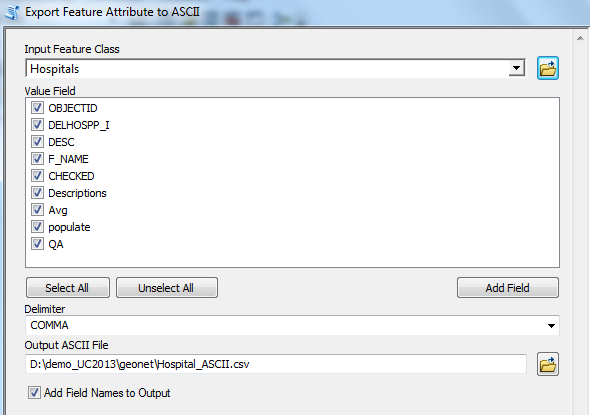
Think Location
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Thank Tim, I'll try it tomorrow. I'll see if I can make it work, I have not used any python tool before. I hope it is just an install.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
It is a little more involved. Within the MXD where your data is, open ArcToolbox. Within the toolbox window right click some white space and choose "Add toolbox". NAvigate to the folder where you unzipped the attached file and select the "Excel and CSV Conversion Tools.tbx" toolbox.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
You can use Export Feature Attribute to ASCII tool to achieve the desired output.
See below snapshot.
Think Location
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Jayanta Poddar - just wondering if there is an import from ascii to table tool. I've been searching but haven't come across one. You can add a csv as a data source, and then I guess you can export that as a table. It would be cool to have a utility like in Access that takes it straight in.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Joe... I have ascii imports but ascii, do you mean ascii to raster?? If it is for tabular data, then use NumPyArrayToTable to bring in tabular data and TableToNumPyArray to go back, And to get the text data into numpy... it has lots of cool tools for importing data into structured and/or recarrays (check my blog, or email me with specifics of format you are working with)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Joe,
Are you looking for Table To Table—Help | ArcGIS for Desktop ?
This tool supports the following table formats as input:
- Geodatabase
- dBASE (.dbf)
- Comma-separated values (.csv)
- Tab-delimited text (.txt)
- Microsoft Excel worksheets (.xls or .xlsx)
- INFO
- VPF
- OLE database
- In-memory table views
Think Location
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Saw the table to table tool listed but didn't notice that it accepts csv or txt files as input. While I avoid txt or csv files as much as I can, sometimes the need arises. I notice the table to table tool doesn't care for pipe ( | ) delimited files which is often times what I get. The Access import wizard is great for those:

Dan_Patterson - I was just wondering out loud....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
Contents of a table called pipe.txt... totally not fancy could have leading trailing whatever, but your pipes are there
a|bc|efgh|ijk
Anything is possible, including rearranging, alternate dtypes (numbers, text etc)
dt = [('A', '<U5'), ('B', '<U5'), ('C', '<U5'), ('D', '<U5')] # arbitrarily set width and dtype
txt = np.loadtxt("c:/temp/pipe.txt", dtype=dt, delimiter="|") # pipes as separator
txt
array(('a', 'bc', 'efgh', 'ijk'),
dtype=[('A', '<U5'), ('B', '<U5'), ('C', '<U5'), ('D', '<U5')])
txt['A'] # a single slice of a columns
array('a',
dtype='<U5')
txt[['A', 'C', 'B', 'D']] # slice column while rearranging
Out[26]:
array(('a', 'efgh', 'bc', 'ijk'),
dtype=[('A', '<U5'), ('C', '<U5'), ('B', '<U5'), ('D', '<U5')])