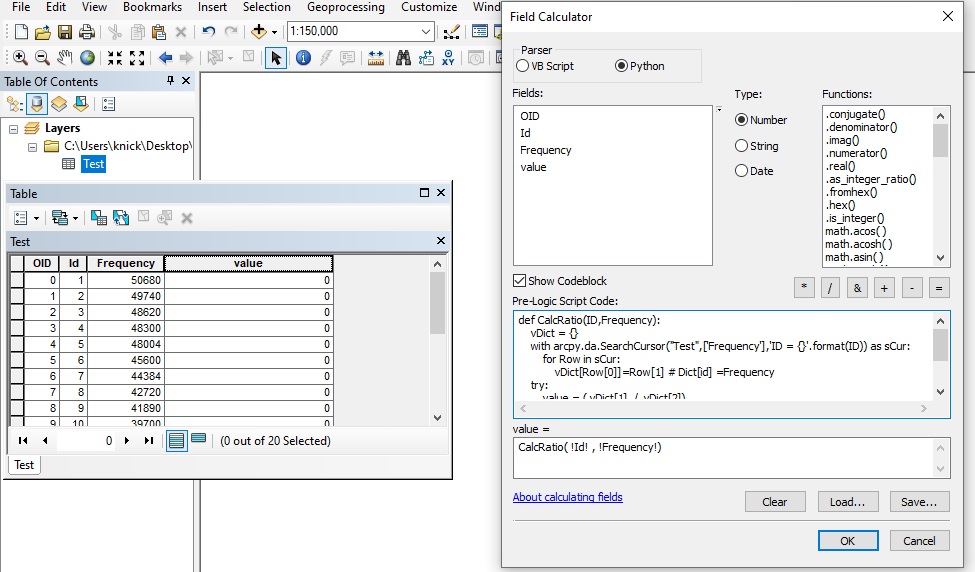
I have to calculate the Ratio between rows (sequentially, i.e., row1/row2, row2/row3 and so on) of a specific field based on the ID field and have to assign the results to a separate field.
Here is the code and the error message:
def CalcRatio(ID,Frequency😞
vDict = {}
with arcpy.da.SearchCursor("Test",['Frequency'],'ID = {}'.format(ID)) as sCur:
for Row in sCur:
vDict[Row[0]]=Row[1] # Dict[id] =Frequency
try: value = ( vDict[1] / vDict[2])
except: value = -1
return valueMessage:
ERROR 000539: Error running expression: CalcRatio( 1 , 50680) Traceback (most recent call last):
File "<expression>", line 1,
in <module> File "<string>", line 5,
in CalcRatio IndexError: tuple index out of range
Here is the data
OID Id Frequency
0 1 50680
1 2 49740
2 3 48620
3 4 48300
4 5 48004
5 6 45600
6 7 44384
7 8 42720
8 9 41890
9 10 39700
10 11 38530
11 12 38207
12 13 38106
13 14 37303
14 15 37205
15 16 36527
16 17 35301
17 18 31674
18 19 28890
19 20 24612
{kind=link}