- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Enterprise
- :
- ArcGIS Enterprise Questions
- :
- Re: Is it a good GIS system design to architect a ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Is it a good GIS system design to architect a second ArcGIS Server as a failover? If so what would the DNS Alias structure look like?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
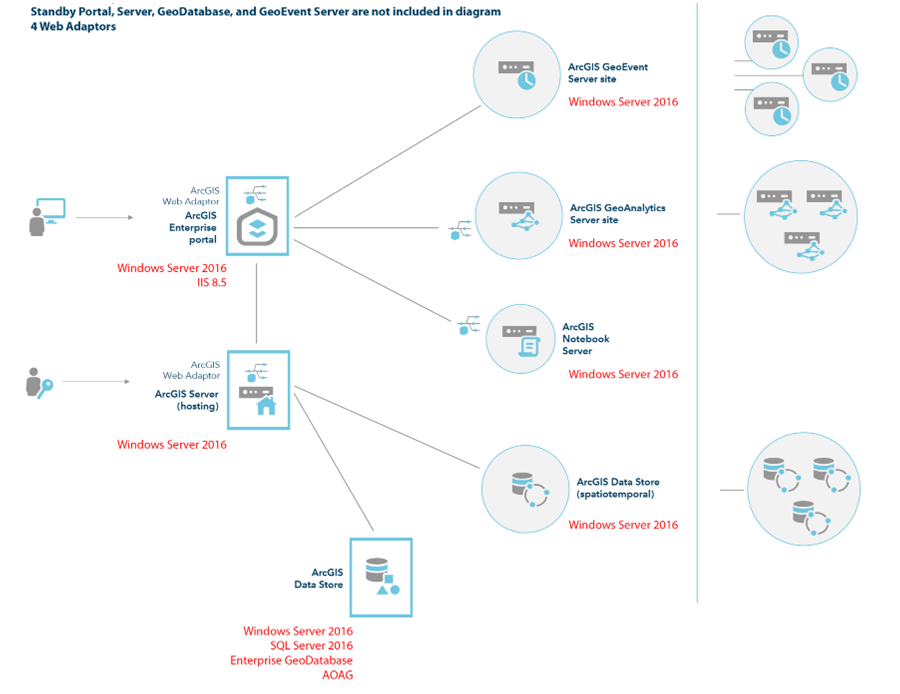
I have a client who wants to build their system as follows:

In their system design they want to architect a second ArcGIS Server as a failover? If so what would the DNS Alias structure look like? Notice the other "Standby" or failover components. 110 users currently, but hope to expand.
I proposed no need for failover:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just to clarify, this is a design where the hosting server would be active-passive (2 x VM's, 2 x sites)? Or, a hosting server site that is multi-machine (2 x VM's, 1 x site)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Multi-machine (2 x VM's, 1 x site)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If it is a multi-machine site, the two machines act as peers. There is no primary/standby concept for machines within an ArcGIS Server site. Now, there are ways to enable the Load balancer you are using to not send requests to a specific machine in the site using something called "Under Maintenence" mode that is in 10.7. This enables you as an admin to decide to set one machine's healtcheck to return false by setting "Under Maintenence" to "True" for that machine. As long as your Load Balancer is making use of the ArcGIS Server healthcheck, it will not send requests to that machine.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As Moginraj Mohandas said, a multi-machine site is not actually HA. When we talk about failover & HA, we need to talk about it in the context of risk. If you had two distinct AGS sites underneath a NLB, what risk are you trying to mitigate? If the network connectivity drops, failover means nothing. If the data tier drops, failover means nothing. Etc. Active-passive of AGS would only resolve an issue which is inherent to the AGS application tier. And, theoretically, both sites are identical so the issue could also occur in the passive site. I tend to find the argument for HA in the application tier is not strong enough to warrant the administrative overhead when considering how little risk it mitigates. Risk is only comprehensively mitigated when you have a passive site on a completely different domain/data centre with duplicate data holdings etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That is a valid point Angus Hooper . Although, the machines being identical doesn't necessarily mean any issue that occurs on one machine will occur on other ones(unless it is a specific site-wide software issue. Examples could range from issues in publishing to consumption of services, or just some behavior like slowness that could happen only on 1 machine). Also, having machines as part of the same site infact actually reduces the adminstrative burden(as opposed to having multiple sites that have the exact same configuration, where the burden of keeping the sites in sync is on the administrator of the site and not the software itself). Just some thoughts..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Exactly. When dealing with the various stakeholders you need to make sure everyone understands the differences between multi-machine site, multiple sites with distinct functions, multiple sites in HA under a NLB etc. Some of these design options may give the desired 'HA' benefit that you are wanting without being a 'true HA' design. For example, a multi-machine site provides some clever workflows for upgrading the site, upgrading underlying OS' and dropping or adding VM's without a perceived outage. This, depending on some audiences, may be the primary reason for a HA design and yet I wouldn't call it actual HA. It's all semantics, but I find the tricky part is unpacking that requirement of 'HA' or 'fault-tolerant' or 'no outages' and then pointing that in the direction of an appropriate design.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Angus Hooper and Moginraj Mohandas for both of your inputs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Angus Hooper and Moginraj Mohandas for both of your inputs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just a generic answer, but I always think linking to the ESRI maintained
System Design Strategies wiki pages
is useful for threads like these, due to the rich content of those pages.