- Home
- :
- All Communities
- :
- Products
- :
- ArcGIS Enterprise
- :
- ArcGIS Enterprise Questions
- :
- Re: ArcGIS Server Directories on EFS in AWS
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All,
This question has been asked before, but I thought I would get a refresh of current thinking.
The Esri supplied Cloudformation template for an HA AGS server site with multiple AGS machines utilises an EC2 instance in Autorecovery mode acting as a file share for use by the AGS site for the Server Directories. (with S3 & DynamoDB for configuration)
Like this
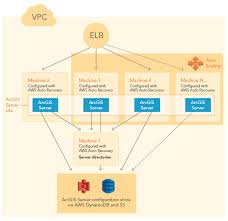
But Autorecover only works in a single Availability Zone and if the entire AZ is lost – theoretically your site will die and only be recoverable from any snapshot backups you have configured for the EBS volumes attached to the File Server.
The ESRi Australia Managed Cloud Services team Is using ObjectiveFS across two Linux EC2 (in different AZ) to provide a Samba share that can be used for the Server Directories, but this seems like a lot of config overhead.
There is another Esri supplied pattern illustrated when using AGS in Docker (experimental at 10.5.1 and not recommended for Production) that uses EFS as the storage for Server directories (and config)
https://s3.amazonaws.com/arcgisstore1051/7333/docs/ReadmeECS.html
Like this
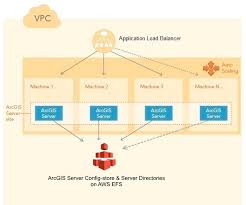
My question – and I am asked by clients fairly regularly, is – why don’t we recommend EFS as the HA File Store for Server directories?
I am aware that the Esri recommendation is to have a file store that provides low latency high volume read/write performance.
Is EFS not fast enough? (that is what I have been telling people up till now). Are there any benchmarks that give some performance comparisons?
Why is it OK to provide an EC2 instance with Autorecover as an alternative HA option when this would fail in the event of an AWS availability zone outage?
And, as a bonus question,
What is the equivalent answer for Azure?
Solved! Go to Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks David,
Will let you know how we go with this configuration as well.
DynamoDB for ArcGIS for Config store and ArcGIS Server System directories in FSx.
Cheers
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
FSx still working well in testing.
We have discovered another undocumented feature that arose when using webgisdr to migrate from an older simpler architecture to the new - specifically regarding Portal Content directories. In the source 10.7.1 system, portal content was on a shared EC2 file server (as created by Esri CF template) - in the target (also 10.7.1), we had portal content in S3 instead of file system. This breaks webgisdr import. (confirmed by Jonathan Quinn).
So, we have now changed to use FSx for Portal Content as well.
This is working without issues in Test.
but, for the size of this directory (~60 GB) AWS costs are a hundred dollars or so more expensive than using S3 would have been.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
any news on your AWS config? (particularly re: FSx)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi David
Yes we have deployed ArcGIS Server with config store in DynamoDB and ArcGIS Server directories in AWS Fsx. All is working well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi David,
We are performing a POC for HA ArcGIS Enterprise with ArcGIS Server Directories in AWS FSx; while also contemplating to put ArcGIS Config Store in AWS FSx instead of AWS DynamoDB.
May I know how your experience has been with AWS FSx? Does AWS FSx stand tall to the following statement from Amazon FSx doc - "It is optimized for enterprise applications in the AWS Cloud, with native Windows compatibility, enterprise performance and features, and consistent sub-millisecond latencies."
Your insights will be highly appreciated.
Best!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
our HA sites (8 of them) are still running with FSx for Portal Content and AGS System Directories. DynamoDB being used for AGS config.
Regarding Performance/Stability, we have not seen any issue with our environments that we would blame on FSx or DynamoDB, so I would stand by FSx as a workable HA solution.
We are currently trying to work out a good way to use AWS snapshots to maintain a Standby mirror site in a different VPC to allow for Blue-Green deployment of patches and upgrades without a need for outage. What we are uncertain of is how to copy FSx & DynamoDB content to a second site (using a different AD) and maintain close linking with the recovered EC2 instance snapshots. We are trying to avoid any chance of creating "orphan" portal items and/or AGS Service definitions which theoretically could happen if FSx replica is a different timestamp to that of the EC2 snapshot AMIs.
We are also aware that AWS method for maintaining an FSx replica across regions uses DFS-R which definitely could introduce delays in completing consistent write/reads. (I think this is why FSx is not on the officially endorsed list)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for your insights, David. Yes, I believe the underlying mechanism of AWS FSx does not allow it to cut into the list of supported shares for HA in the cloud.
I am assuming your secondary site is in a different region. When you say secondary site, do you mean it as your DR site or a mirror site for upgrades (something like a staging)? How will this help in avoiding the downtime when you are upgrading? As I understand, downtimes are inevitable during upgrades unless you have a DR site that you use in read only mode with limited functionality while upgrading the primary site. I am curious to know how downtimes can be avoided?
Is there any reason you are using AWS snapshot instead of webgisdr utility? AWS snapshot will help in copying the EC2 instance, but I think we still need them to point to a copy of DynamoDB and FSx. It seems like you are still figuring out how to copy the DynamoDB and FSx across regions without any delay and/or risking creation of orphans items in Enterprise portal.
As per my understanding, we need all EC2 instances to be a part of the same AD domain to use AWS FSx share. Is this why you are using a different AD for the secondary site?
We are working on implementing a primary and secondary sites, in 2 different regions, with both being configured for Highly Availability. We are planning to use DynamoDB and AWS FSx in both regions and periodically synchronizing the regions using webgisdr. While upgrading primary, we will use Route 53 to direct traffic to our secondary site (read only mode). That way there is no downtime for read access and limited functionality is available with Enterprise portal. Once the primary is upgraded, we will route traffic back to primary using Route 53. Then we will remove read only mode from secondary, upgrade the secondary site, and use webgisdr to sync the data from primary to secondary back again.
We considered using AWS DataSync to synchronize AWS FSx across regions and use DynamoDB with Global Tables but could not come to a logical conclusion with those AWS services.
I would appreciate your comments on this approach.
Best!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi again,
sounds like you are planning almost exactly the configuration we are moving toward. Using the "blue-green" staging pattern.
We have existing HA site at 10.7.1. We now want to move to 10.8.1 but have no time when the Portal and its federated services are not available at least for Read-Only.
As the Portal holds a lot of content (>400 GB), we are conscious that the upgrade is going to take a long time - we estimate at least 12 hours - probably more unless we temporarily beef up the Portal Server to have more CPU available to the javaw.exe processes.
So, we are looking at setting up the standby site (in the same Region- in Oz, moving out of ap-southeast2 is bad news in latency terms) to be used as "read-only" and giving the user community lots of pre-warning that the site will be under maintenance, and any new/updated content will be lost if it happens within the nominated time window. (if we were at 10.8+ we could go into Read-Only mode, but not available in earlier versions)
We are very familiar with using webgisdr - it was the method we used to originally migrate from one AWS account to another and upgrade from 10.6.1 to 10.7.1 along the way - but that time, the site was much smaller and far fewer people were affected by the outage.
The reason we are thinking about not using webgisdr this time is that it is very slow due to the large size of Portal content. The backup of portal itself takes >4 hrs (which runs in parallel with server and data store backups that take slightly less) and then it can take either 12 hrs to zip all the individual backups to a single archive (using file system backup_location); or 12 hours to upload the individual backup files to an S3 bucket (which sounds ridiculous, but at present is apparently unavoidable- at least at 10.7.1).
We would then expect maybe another 10-12 hours to import the package to the standby site, ouch.
- and then the time for the upgrade - so we are getting close to a full weekend.
If we can do snapshot restoration to the standby site, then we should be able to get the setup pre-upgrade down to a couple of hours or less.
We have used Route53 private zoning to allow the standby site to think it has the same Public & Admin urls as the Primary site (and using weighting to switch public access between the two) - but found problems when trying to use the same domain for both internal and external Load Balancer, so needed to end up using AWS DS's own DNS override.
this is why we are thinking to use a separate AD Domain for the standby site.
We are in contact with the AWS engineers regarding the best way to make the standby a replica of the primary site. I don't think using DynamoDB Global Tables will provide the isolation we probably need to be able to upgrade one site without affecting the other, but maybe DataSync will help for FSx transfer.
I will have to keep you posted on our progress
cheers,
David H.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for your response, David!
We are also evaluating Route 53 public and private zones to redirect traffic; and making sure that both our internal and external LBs work as expected. Hopefully, we will have more to share from our experiences.
Best!
Amol
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi David,
Good Day!
I was wondering if you have made any breakthrough with your secondary deployment, where you where planning to recover the EC2 instances from snapshots in the standby site? Did ArcGIS Enterprise come up in the standby site? Or you had explore any alternatives?
In our test, we have deployed the managed enterprise AD using AWS DS and replicated it to the Secondary Region. In addition to that , we have associated both VPCs (Primary and Secondary) in Route 53's private zone. However, the DNS resolution of the WebContextURL to the internal load balancer within the VPC was a challenge that we tried resolving by setting a forwarder to Amazon DNS Server in our DNS manager.
As we speak, we are still working on setting a full proof secondary deployment to minimize downtime while upgrading/patching. We have been successfully in moving FSx using Data Sync (still evaluating the integrity of the data copied) and S3 bucket using Cross region replication. Additionally, we are exploring AWS Data Pipeline to move DynamoDB Tables.
Looking forward to your updates and insights.
Stay Safe!
Best,
Amol