- Home
- :
- All Communities
- :
- ArcGIS Topics
- :
- Applications Prototype Lab
- :
- Applications Prototype Lab Blog
- :
- Deep Learning with the AWS DeepLens
Deep Learning with the AWS DeepLens
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Motivation
Amazon recently released a deep learning enabled camera called the DeepLens (https://aws.amazon.com/deeplens/). The DeepLens allows developers to build, train, and deploy deep learning models to carry out custom computer vision tasks. The Applications Prototype Lab obtained a DeepLens and began to explore its capabilities and limitations.
One of the most common tasks in computer vision is object detection. This task is slightly more involved than image classification since it requires localization of the object in the image space. This summer, we explored object detection and how we could expand it to fit our needs. For example, one use case could be to detect and recognize different animal species in a wildlife preserve. By doing this, we can gather relevant location-based information and use this information to carry out specific actions.
Animal species detection was tested using Tensorflow’s Object Detection API, which allowed building a model that could easily be deployed to the DeepLens. However, we needed to scale down our detection demo to make it easier to test on the ESRI campus. For this, we looked at face detection.
The DeepLens comes with sample projects, including those that carry out object and face detection. For experimentation purposes, we decided to see if we could expand the face detection sample to be able to recognize and distinguish between different people.
Services and Frameworks
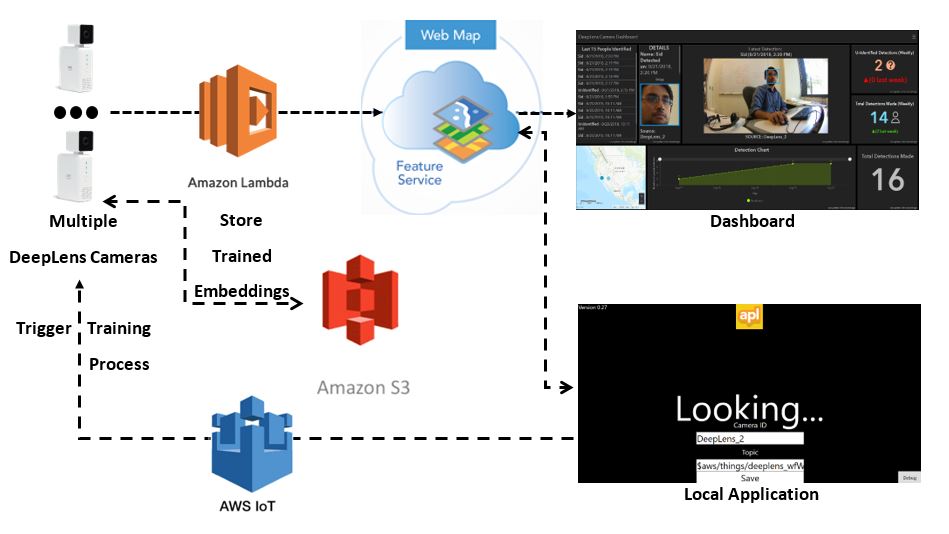
Over the course of the summer, we built a face recognition demo using various Amazon and ESRI services. These services include:
- The AWS DeepLens Console (to facilitate deployment of the projects onto the DeepLens)
- Amazon Lambda (to develop the Python Lambda functions that run the inference models)
- Amazon S3 (to store the trained database, as well as the models required for inference)
- The AWS IoT Console (to facilitate communication to and from the DeepLens)
- A feature service and web map hosted on ArcGIS (to store the data from the DeepLens’ detections)
- Operations Dashboard (one for each DeepLens, to display the relevant information)
To carry out the inference for this experiment, we used the following machine learning frameworks/toolkits:
- MxNet (the default MxNet model trained for face detection and optimized for the DeepLens)
- Dlib (a toolkit with facial landmark detection functionality that helps in face recognition)
Workflow
The MxNet and Dlib models are deployed on the DeepLens along with an inference lambda function. The DeepLens loads the models and begins taking in frames from its video input. These frames are passed through the face detection and recognition models to find a match from within the database stored in an Amazon S3 bucket. If the face is recognized, the feature service is updated with relevant information, such as name, detection time, DeepLens ID, and DeepLens location, and the recognition process continues.
If there is no match to the database, or if the recognition model is unsure, a match is still returned with “Unidentified” as the name. When this happens, we are triggering the DeepLens for training. For this, we have a local application running on the same device as the dashboard. When encountering an unidentified object, the application prompts the person to begin training. If training is triggered, the DeepLens plays audio instructions and grabs the relevant facial landmark information to train itself. The database in the S3 bucket is finally updated with this data, and the recognition process resumes.
Results
The face recognition model returns a result if its inference has an accuracy of at least 60%. The model has been able to return the correct result, whether identified or unidentified, during roughly 80% of the tests. There have been a few cases of false positives and negatives, but this has been reduced significantly by tightening the threshold values and only returning consistent detections (over multiple frames). The accuracy of the DeepLens detections can be increased with further tweaking of the model parameters and threshold values.
The model was initially trained and tested on a database containing facial landmark data for four people. Since then, the database has increased to containing data for ten people. This has led to a reduction in the occurrence of false positives.The model is more likely to be accurate if there are more people that are trained and stored into the database.
Object or animal species detection can be implemented on the DeepLens if we have a model that is trained on enough data (related to the object(s) we intend to detect). This data should consist of positives (images containing the object to be detected) as well as negatives (images that do not contain the object) for the best accuracy. Once we have the models ready, the process to get it running on the DeepLens is very similar to the one used to run the face detection demo.
Limitations
The DeepLens currently only supports Lambda functions written in Python 2.7, but Amazon seems to be working on building support for Python 3.x.
The model optimizer for the DeepLens only supports optimizing certain MxNet, Tensorflow, and Caffe models for the in-built GPU. Other frameworks and models can still be used on the DeepLens, but the inference speed is be drastically reduced.
Future Work
We discovered that the DeepLens has a simple microphone. Although the DeepLens is primarily designed for computer vision tasks, it would be interesting to run audio analysis tests and have it run alongside other computer vision tasks, for example, to know when a door has been opened or closed.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.