When EXISTS Doesn't: File Geodatabases and Correlated Subqueries
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
In /blogs/tilting/2016/09/27/performance-at-a-price-file-geodatabases-and-sql-support?sr=search&searchI..., I bring attention to the SQL support trade-off Esri made while developing the file geodatabase (FGDB) as a replacement for the personal geodatabase (PGDB). In that post, several links are provided for those who are interested in learning more about SQL support in file geodatabases. Although there is plenty of overlap in content between the various sources/links, there are also important statements that only exist in one place or another, and knowing that can be important when troubleshooting errors or trying to understand spurious results from data stored in file geodatabases.
One area where users can get themselves into trouble with file geodatabases and SQL is the EXISTS condition or operator. Looking at the SQL Reference (FileGDB_SQL.htm) in the File Geodatabase API ( @Esri Downloads ) or the SQL reference for query expressions used in ArcGIS:
[NOT] EXISTS
Returns TRUE if the subquery returns at least one record; otherwise, it returns FALSE. For example, this expression returns TRUE if the OBJECTID field contains a value of 50:
EXISTS (SELECT * FROM parcels WHERE "OBJECTID" = 50)EXISTS is supported in file, personal, and ArcSDE geodatabases only.
Seeing that SQL EXISTS is supported in the file geodatabase, how does someone get himself into trouble using it? Unfortunately, it is easier than you might expect, and the answer is correlated subqueries.
Correlated subqueries are fairly common when working with EXISTS, so common in fact that Microsoft's EXISTS (Transact-SQL) documentation and Oracle's EXISTS Condition documentation both use a correlated subquery in at least one code example. At its simplest, a correlated subquery is a subquery that relates back to one or more tables in the outer query. The theory and empiricism of correlated subqueries goes well beyond this blog post, but I will mention that correlated subqueries do have some JOIN-like properties, or at least appearances.
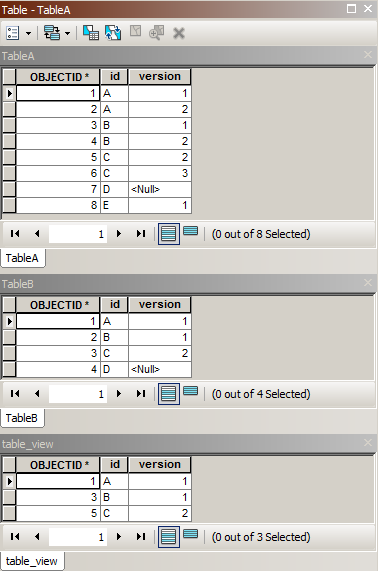
The following example is adapted from Select Max value arcpy, the same GeoNet question that got me researching this issue many months back. Let's start with 2 basic tables (TableA and TableB), each having a text and integer field, and one table containing a subset of records from the other table.
>>> fgdb = # path to file geodatabase
>>> pgdb = # path to personal geodatabase
>>> egdb = # path to enterprise geodatabase, SQL Server used in example
>>> gpkg = # path to GeoPackage
>>> gdbs = (fgdb, pgdb, egdb, gpkg)
>>>
>>> values = (("A", 1), ("A", 2), ("B", 1), ("B", 2),
... ("C", 2), ("C", 3), ("D", None), ("E", 1))
...
>>> table_names = ("TableA", "TableB")
>>>
>>> for gdb in gdbs:
... for i in xrange(2,0,-1):
... table = arcpy.CreateTable_management(gdb, table_names[i-1])
... arcpy.AddField_management(table, "id", "TEXT")
... arcpy.AddField_management(table, "version", "LONG")
... with arcpy.da.InsertCursor(table, ("id", "version")) as cur:
... for value in values[::i]:
... cur.insertRow(value)
...
... qry = ("EXISTS (SELECT 1"
... " FROM TableB"
... " WHERE TableB.id = TableA.id"
... " AND TableB.version = TableA.version)")
...
... table_view = arcpy.MakeTableView_management(table, "table_view", qry)
... print arcpy.GetCount_management(table_view)
... arcpy.Delete_management(table_view)
0
3
3
3
>>> The sample code above creates the two basic tables in a file geodatabase, personal geodatabase, enterprise geodatabase (I used SQL Server), and a GeoPackage. The code then creates a table view for each of the geodatabases by using EXISTS with a simple correlated subquery to select the records from TableA that have a matching id and version in TableB. The correct table view is shown in the screenshot above. One can see from the results of the code that no records are returned from the file geodatabase.
So why doesn't the file geodatabase return any records? Are subqueries not supported? Seeing that the documentation for EXISTS mentions subqueries, it seems they have to be supported, at least to some degree. Let's take a closer look at the Subqueries section of SQL reference for query expressions used in ArcGIS:
Subqueries
Note:
Coverages, shapefiles, and other nongeodatabase file-based data sources do not support subqueries. Subqueries that are performed on versioned ArcSDE feature classes and tables will not return features that are stored in the delta tables. File geodatabases provide the limited support for subqueries explained in this section, while personal and ArcSDE geodatabases provide full support. For information on the full set of subquery capabilities of personal and ArcSDE geodatabases, refer to your DBMS documentation.
A subquery is a query nested within another query. It can be used to apply predicate or aggregate functions or to compare data with values stored in another table....
Subquery support in file geodatabases is limited to the following:
- IN predicate. For example:
"COUNTRY_NAME" NOT IN (SELECT "COUNTRY_NAME" FROM indep_countries)
- Scalar subqueries with comparison operators. A scalar subquery returns a single value. For example:
"GDP2006" > (SELECT MAX("GDP2005") FROM countries)For file geodatabases, the set functions AVG, COUNT, MIN, MAX, and SUM can only be used within scalar subqueries.
- EXISTS predicate. For example:
EXISTS (SELECT * FROM indep_countries WHERE "COUNTRY_NAME" = 'Mexico')
The documentation states "limited support" for subqueries, but it also states the EXISTS predicate is supported. If subqueries aren't the problem, maybe correlated subqueries are the problem. After all, none of the EXISTS examples in all of the documentation uses a correlated subquery. Unfortunately, guessing is what we are left with because correlated subqueries are not mentioned explicitly in any of the file geodatabase documentation I can find.
From this simple example, it is clear the file geodatabase gives incorrect results when using EXISTS with correlated subqueries. Are the incorrect results a bug or limitation of SQL support in the file geodatabase? Even if one tries to argue the latter, there is still the problem of the user getting incorrect results instead of an error message, which should be what the user gets if correlated subqueries are not supported.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.