NumPy ..... Pandas nothing is obvious
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
NumPy vs Pandas
JIVE has fouled up the python syntax formatting in blogs...
hopefully this will be resolved soon
Well actually Pandas can't exist without NumPy. But apparently it has a 'friendlier' face than its parental unit .
This demonstrates a difference.
We will begin with an array derived from a table from within ArcGIS Pro.
I used the TableToNumPyArray
TableToNumPyArray—Data Access module | ArcGIS Desktop
A classy function.
The array
a # ---- the array from the table ----
array([( 1, 0, 'B', 'A_', 'Hall', 26), ( 2, 1, 'C', 'C_', 'Hall', 60),
( 3, 2, 'D', 'A_', 'Hall', 42), ( 4, 3, 'C', 'A_', 'Hall', 57),
( 5, 4, 'C', 'B_', 'Hall', 51), ( 6, 5, 'B', 'B_', 'Hosp', 14),
( 7, 6, 'C', 'A_', 'Hall', 45), ( 8, 7, 'B', 'B_', 'Hosp', 51),
( 9, 8, 'B', 'A_', 'Hall', 28), (10, 9, 'C', 'C_', 'Hosp', 58),
(11, 10, 'B', 'B_', 'Hosp', 6), (12, 11, 'C', 'A_', 'Hall', 49),
(13, 12, 'B', 'A_', 'Hosp', 42), (14, 13, 'C', 'A_', 'Hosp', 60),
(15, 14, 'C', 'B_', 'Hosp', 41), (16, 15, 'A', 'A_', 'Hosp', 53),
(17, 16, 'A', 'A_', 'Hall', 42), (18, 17, 'A', 'C_', 'Hall', 59),
(19, 18, 'C', 'C_', 'Hosp', 37), (20, 19, 'B', 'B_', 'Hall', 52)],
dtype=[('OBJECTID', '<i4'), ('f0', '<i4'), ('County', '<U2'), ('Town', '<U6'), ('Facility', '<U8'), ('Time', '<i4')])OOOO screams the crowd in disgust... it is confusing looking.
So we will revert to the every favorite Pandas.
import pandas as pd
pd.DataFrame(a)
OBJECTID f0 County Town Facility Time
0 1 0 B A_ Hall 26
1 2 1 C C_ Hall 60
2 3 2 D A_ Hall 42
3 4 3 C A_ Hall 57
4 5 4 C B_ Hall 51
5 6 5 B B_ Hosp 14
6 7 6 C A_ Hall 45
7 8 7 B B_ Hosp 51
8 9 8 B A_ Hall 28
9 10 9 C C_ Hosp 58
10 11 10 B B_ Hosp 6
11 12 11 C A_ Hall 49
12 13 12 B A_ Hosp 42
13 14 13 C A_ Hosp 60
14 15 14 C B_ Hosp 41
15 16 15 A A_ Hosp 53
16 17 16 A A_ Hall 42
17 18 17 A C_ Hall 59
18 19 18 C C_ Hosp 37
19 20 19 B B_ Hall 52AHHHHHH the crowd cheers... much better looking.
But wait! If you just wanted the array to look pretty, you can do that with numpy and python easily as well.
How about...
id OBJECTID f0 County Town Facility Time
-------------------------------------------------
000 1 0 B B_ Hall 11
001 2 1 A A_ Hall 24
002 3 2 C C_ Hosp 43
003 4 3 A B_ Hall 43
004 5 4 B B_ Hall 16
005 6 5 B A_ Hall 8
006 7 6 A C_ Hall 26
007 8 7 B C_ Hall 31
008 9 8 C C_ Hall 7
009 10 9 A A_ Hall 58
010 11 10 A A_ Hosp 20
011 12 11 C A_ Hosp 37
012 13 12 C B_ Hall 36
013 14 13 A B_ Hosp 33
014 15 14 C C_ Hosp 51
015 16 15 B C_ Hosp 53
016 17 16 C A_ Hosp 21
017 18 17 C C_ Hosp 42
018 19 18 A B_ Hosp 43
019 20 19 A C_ Hall 5??????? now the crowd is confused. Which is better? Which looks better?
The choice is yours. Maybe I will reveal pd_ at sometime but I might rename it to dp_ in homage to its coder.
# ---- quick prints and formats
Too much? How about a quick_prn of the array with edge items, width specification all done in a couple lines of code
quick_prn(a, max_lines=10)
Array fields:
('OBJECTID', 'f0', 'County', 'Town', 'Facility', 'Time')
[( 1, 0, 'B', 'A_', 'Hall', 26)
( 2, 1, 'C', 'C_', 'Hall', 60)
( 3, 2, 'D', 'A_', 'Hall', 42)
...
(18, 17, 'A', 'C_', 'Hall', 59)
(19, 18, 'C', 'C_', 'Hosp', 37)
(20, 19, 'B', 'B_', 'Hall', 52)]A few lines of code... a def for multiple purposes
def quick_prn(a, edgeitems=3, max_lines=25, wdth=100, decimals=2, prn=True):
"""Format a structured array by reshaping and replacing characters from
the string representation
"""
wdth = min(len(str(a[0])), wdth)
with np.printoptions(precision=decimals, edgeitems=edgeitems,
threshold=max_lines, linewidth=wdth):
print("\nArray fields:\n{}\n{}".format(a.dtype.names, a))---- Analysis? ----
What about pivot tables? Excel has them, so does Pandas. A quick call to some small python/numpy defs and...
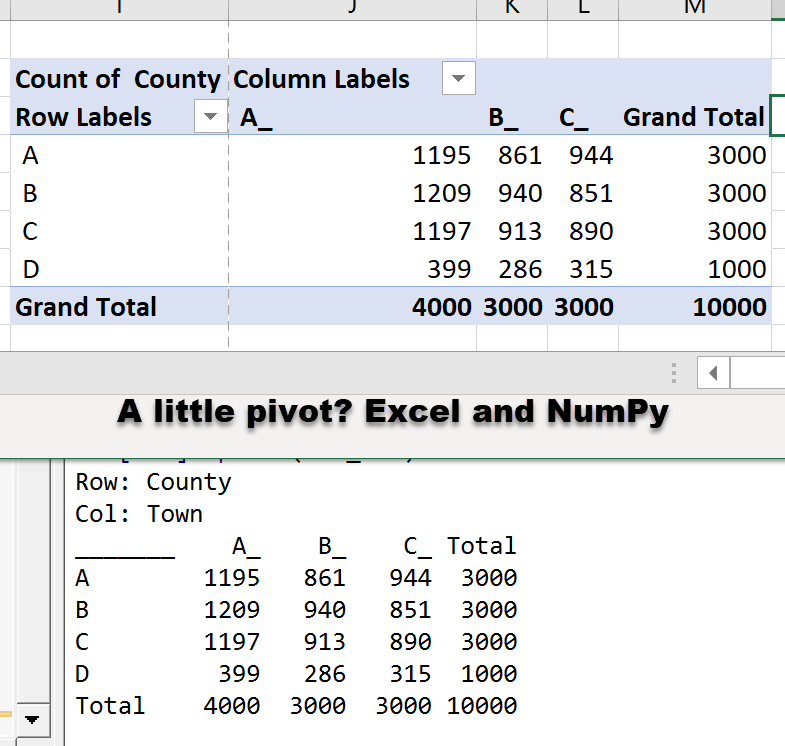
Can't do the blue bit though.
---- Comment -----
Of course this blog is purely in jest, but it serves to point out that not is all that it seems and that everything has a root. Remember your origins, even if that means in coding.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.